 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo be Critical: Self-Calibrated Weakly Supervised Learning for Salient Object Detection
Sep 04, 2021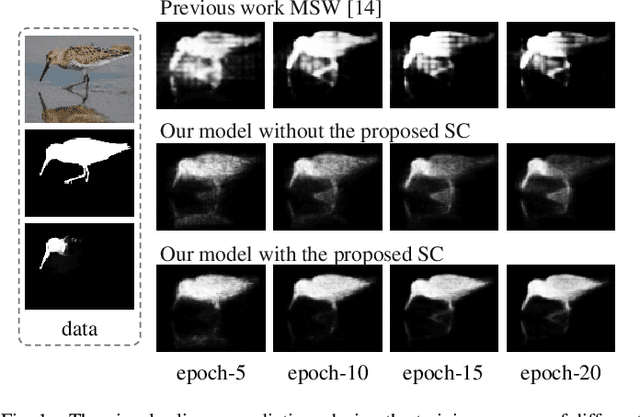
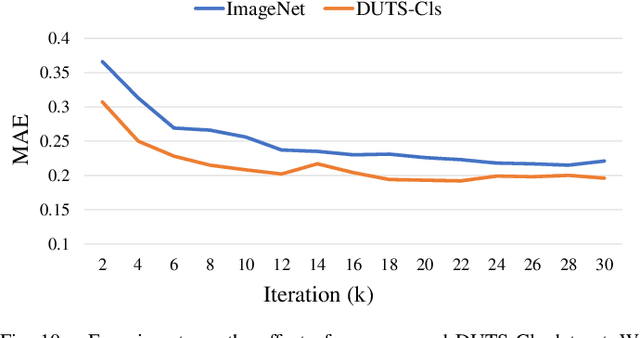
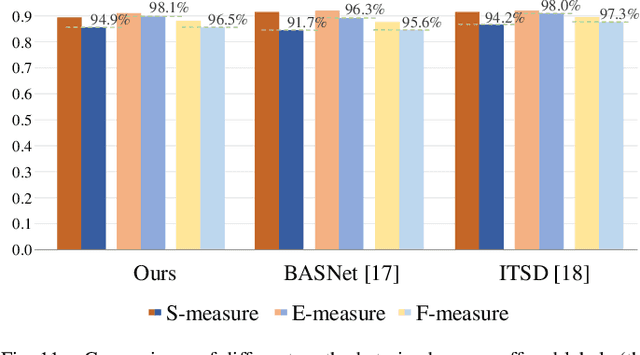
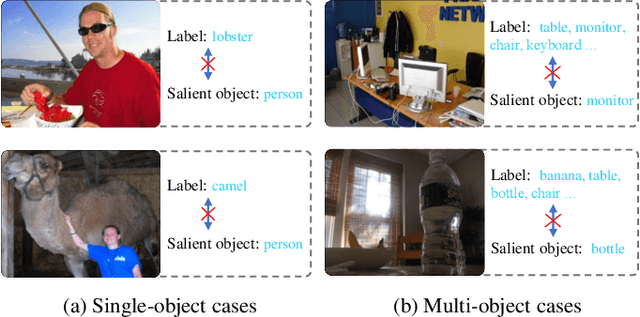
Weakly-supervised salient object detection (WSOD) aims to develop saliency models using image-level annotations. Despite of the success of previous works, explorations on an effective training strategy for the saliency network and accurate matches between image-level annotations and salient objects are still inadequate. In this work, 1) we propose a self-calibrated training strategy by explicitly establishing a mutual calibration loop between pseudo labels and network predictions, liberating the saliency network from error-prone propagation caused by pseudo labels. 2) we prove that even a much smaller dataset (merely 1.8% of ImageNet) with well-matched annotations can facilitate models to achieve better performance as well as generalizability. This sheds new light on the development of WSOD and encourages more contributions to the community. Comprehensive experiments demonstrate that our method outperforms all the existing WSOD methods by adopting the self-calibrated strategy only. Steady improvements are further achieved by training on the proposed dataset. Additionally, our method achieves 94.7% of the performance of fully-supervised methods on average. And what is more, the fully supervised models adopting our predicted results as "ground truths" achieve successful results (95.6% for BASNet and 97.3% for ITSD on F-measure), while costing only 0.32% of labeling time for pixel-level annotation.