 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPT: Universal Parallel Tuning for Transfer Learning with Efficient Parameter and Memory
Paper and Code
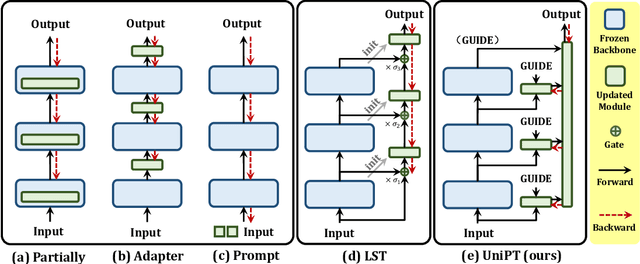
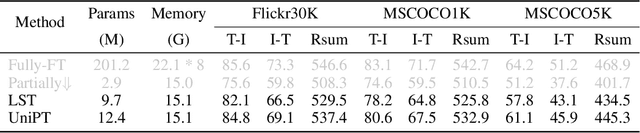
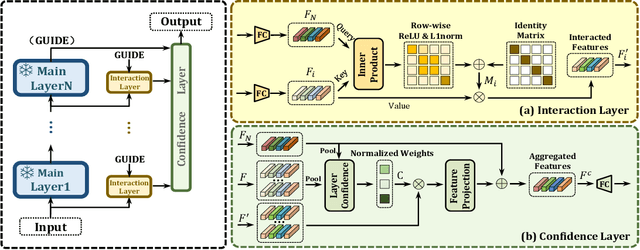
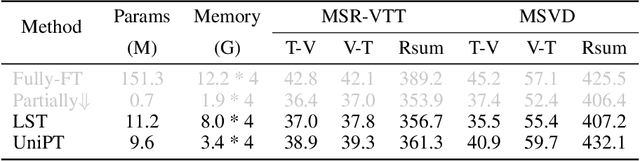
Fine-tuning pre-trained models has emerged as a powerful technique in numerous domains, owing to its ability to leverage enormous pre-existing knowledge and achieve remarkable performance on downstream tasks. However, updating the parameters of entire networks is computationally intensive. Although state-of-the-art parameter-efficient transfer learning (PETL) methods significantly reduce the trainable parameters and storage demand, almost all of them still need to back-propagate the gradients through large pre-trained networks. This memory-extensive characteristic extremely limits the applicability of PETL methods in real-world scenarios. To this end, we propose a new memory-efficient PETL strategy, dubbed Universal Parallel Tuning (UniPT). Specifically, we facilitate the transfer process via a lightweight learnable parallel network, which consists of two modules: 1) A parallel interaction module that decouples the inherently sequential connections and processes the intermediate activations detachedly of the pre-trained network. 2) A confidence aggregation module that learns optimal strategies adaptively for integrating cross-layer features. We evaluate UniPT with different backbones (e.g., VSE$\infty$, CLIP4Clip, Clip-ViL, and MDETR) on five challenging vision-and-language tasks (i.e., image-text retrieval, video-text retrieval, visual question answering, compositional question answering, and visual grounding). Extensive ablations on ten datasets have validated that our UniPT can not only dramatically reduce memory consumption and outperform the best memory-efficient competitor, but also achieve higher performance than existing PETL methods in a low-memory scenario on different architectures. Our code is publicly available at: https://github.com/Paranioar/UniPT.