 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Aware Statistical Inference with Differentially Private Synthetic Data
Paper and Code
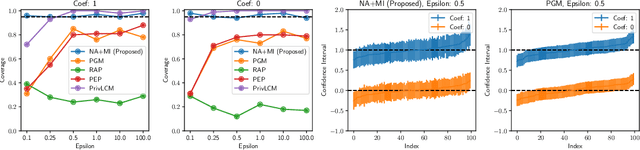
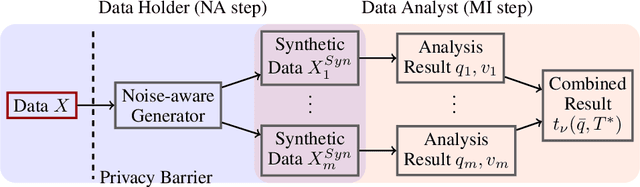
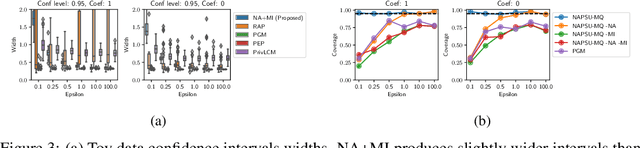
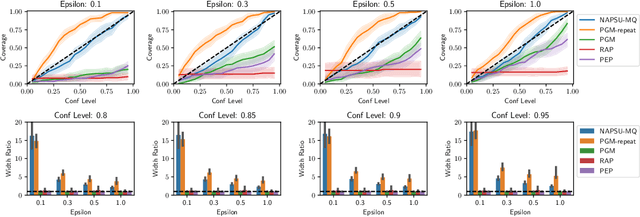
While generation of synthetic data under differential privacy (DP) has received a lot of attention in the data privacy community, analysis of synthetic data has received much less. Existing work has shown that simply analysing DP synthetic data as if it were real does not produce valid inferences of population-level quantities. For example, confidence intervals become too narrow, which we demonstrate with a simple experiment. We tackle this problem by combining synthetic data analysis techniques from the field of multiple imputation, and synthetic data generation using noise-aware Bayesian modeling into a pipeline NA+MI that allows computing accurate uncertainty estimates for population-level quantities from DP synthetic data. To implement NA+MI for discrete data generation from marginal queries, we develop a novel noise-aware synthetic data generation algorithm NAPSU-MQ using the principle of maximum entropy. Our experiments demonstrate that the pipeline is able to produce accurate confidence intervals from DP synthetic data. The intervals become wider with tighter privacy to accurately capture the additional uncertainty stemming from DP noise.