 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting Networks with Co-training for Continual Learning
Paper and Code
Sep 09, 2020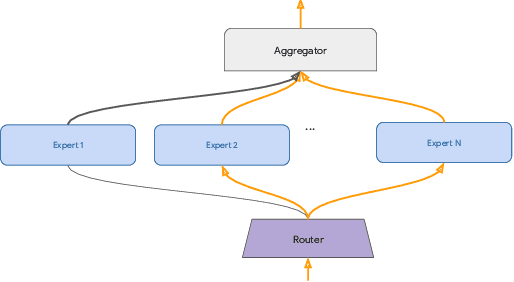


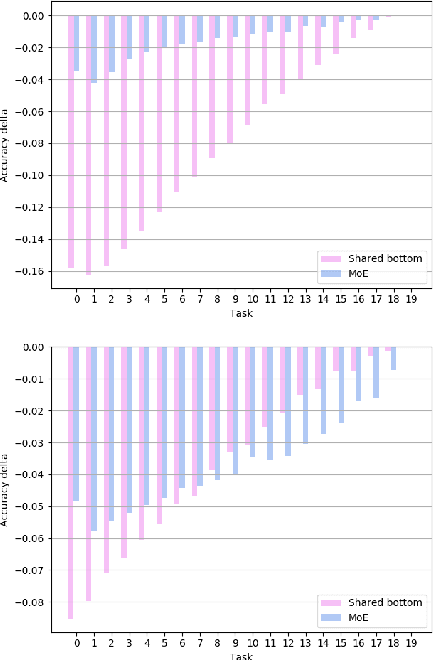
The core challenge with continual learning is catastrophic forgetting, the phenomenon that when neural networks are trained on a sequence of tasks they rapidly forget previously learned tasks. It has been observed that catastrophic forgetting is most severe when tasks are dissimilar to each other. We propose the use of sparse routing networks for continual learning. For each input, these network architectures activate a different path through a network of experts. Routing networks have been shown to learn to route similar tasks to overlapping sets of experts and dissimilar tasks to disjoint sets of experts. In the continual learning context this behaviour is desirable as it minimizes interference between dissimilar tasks while allowing positive transfer between related tasks. In practice, we find it is necessary to develop a new training method for routing networks, which we call co-training which avoids poorly initialized experts when new tasks are presented. When combined with a small episodic memory replay buffer, sparse routing networks with co-training outperform densely connected networks on the MNIST-Permutations and MNIST-Rotations benchmarks.