 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBespoke Approximation of Multiplication-Accumulation and Activation Targeting Printed Multilayer Perceptrons
Dec 29, 2023



Printed Electronics (PE) feature distinct and remarkable characteristics that make them a prominent technology for achieving true ubiquitous computing. This is particularly relevant in application domains that require conformal and ultra-low cost solutions, which have experienced limited penetration of computing until now. Unlike silicon-based technologies, PE offer unparalleled features such as non-recurring engineering costs, ultra-low manufacturing cost, and on-demand fabrication of conformal, flexible, non-toxic, and stretchable hardware. However, PE face certain limitations due to their large feature sizes, that impede the realization of complex circuits, such as machine learning classifiers. In this work, we address these limitations by leveraging the principles of Approximate Computing and Bespoke (fully-customized) design. We propose an automated framework for designing ultra-low power Multilayer Perceptron (MLP) classifiers which employs, for the first time, a holistic approach to approximate all functions of the MLP's neurons: multiplication, accumulation, and activation. Through comprehensive evaluation across various MLPs of varying size, our framework demonstrates the ability to enable battery-powered operation of even the most intricate MLP architecture examined, significantly surpassing the current state of the art.
Hardware-Aware DNN Compression via Diverse Pruning and Mixed-Precision Quantization
Dec 23, 2023



Deep Neural Networks (DNNs) have shown significant advantages in a wide variety of domains. However, DNNs are becoming computationally intensive and energy hungry at an exponential pace, while at the same time, there is a vast demand for running sophisticated DNN-based services on resource constrained embedded devices. In this paper, we target energy-efficient inference on embedded DNN accelerators. To that end, we propose an automated framework to compress DNNs in a hardware-aware manner by jointly employing pruning and quantization. We explore, for the first time, per-layer fine- and coarse-grained pruning, in the same DNN architecture, in addition to low bit-width mixed-precision quantization for weights and activations. Reinforcement Learning (RL) is used to explore the associated design space and identify the pruning-quantization configuration so that the energy consumption is minimized whilst the prediction accuracy loss is retained at acceptable levels. Using our novel composite RL agent we are able to extract energy-efficient solutions without requiring retraining and/or fine tuning. Our extensive experimental evaluation over widely used DNNs and the CIFAR-10/100 and ImageNet datasets demonstrates that our framework achieves $39\%$ average energy reduction for $1.7\%$ average accuracy loss and outperforms significantly the state-of-the-art approaches.
Approximate Decision Trees For Machine Learning Classification on Tiny Printed Circuits
Mar 15, 2022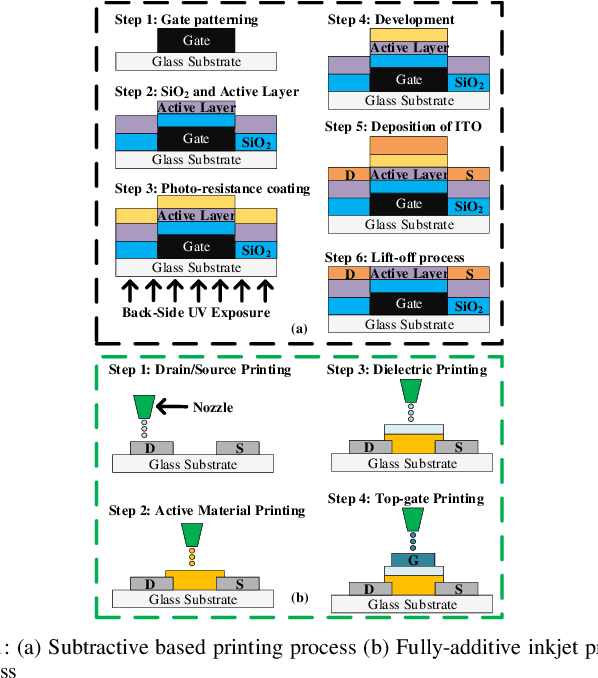
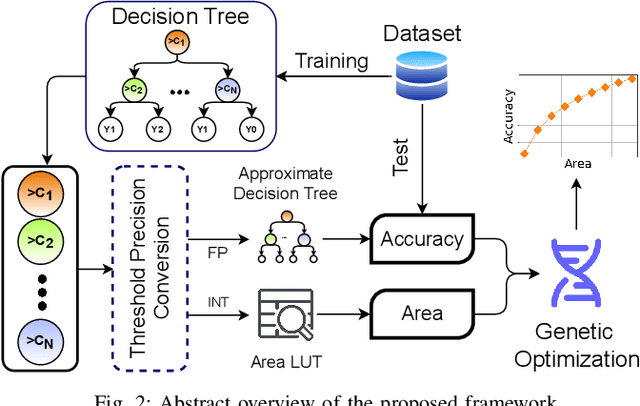
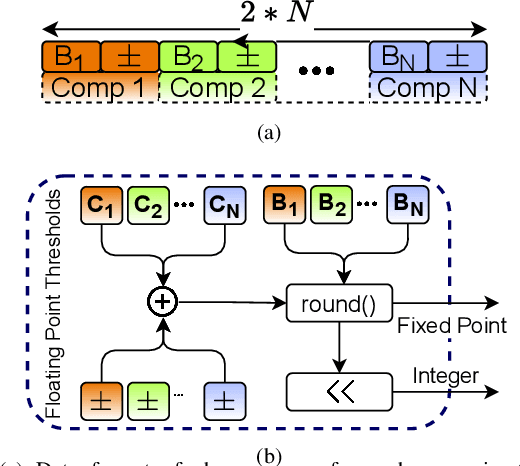
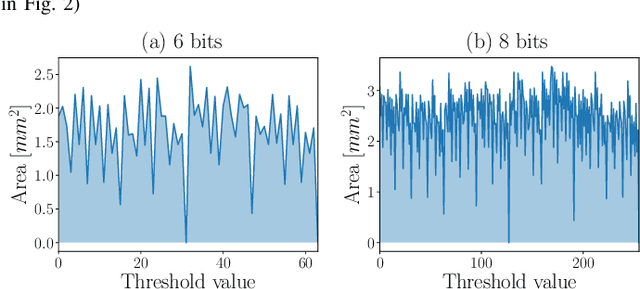
Although Printed Electronics (PE) cannot compete with silicon-based systems in conventional evaluation metrics, e.g., integration density, area and performance, PE offers attractive properties such as on-demand ultra-low-cost fabrication, flexibility and non-toxicity. As a result, it targets application domains that are untouchable by lithography-based silicon electronics and thus have not yet seen much proliferation of computing. However, despite the attractive characteristics of PE, the large feature sizes in PE prohibit the realization of complex printed circuits, such as Machine Learning (ML) classifiers. In this work, we exploit the hardware-friendly nature of Decision Trees for machine learning classification and leverage the hardware-efficiency of the approximate design in order to generate approximate ML classifiers that are suitable for tiny, ultra-resource constrained, and battery-powered printed applications.
AdaPT: Fast Emulation of Approximate DNN Accelerators in PyTorch
Mar 08, 2022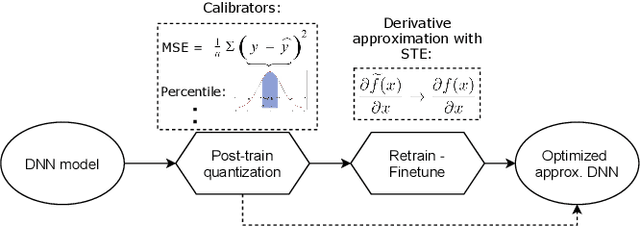
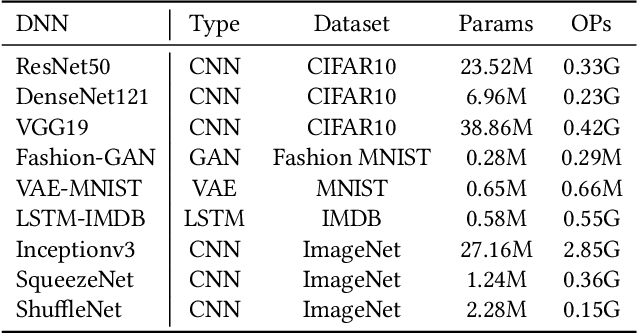
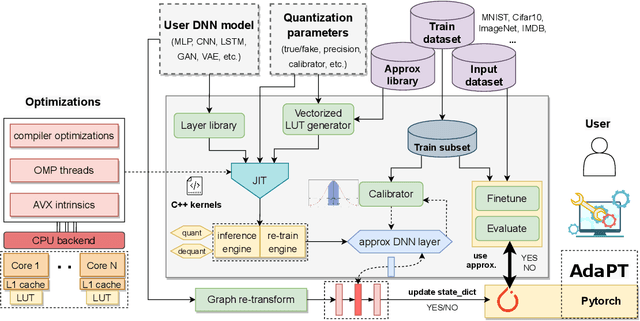

Current state-of-the-art employs approximate multipliers to address the highly increased power demands of DNN accelerators. However, evaluating the accuracy of approximate DNNs is cumbersome due to the lack of adequate support for approximate arithmetic in DNN frameworks. We address this inefficiency by presenting AdaPT, a fast emulation framework that extends PyTorch to support approximate inference as well as approximation-aware retraining. AdaPT can be seamlessly deployed and is compatible with the most DNNs. We evaluate the framework on several DNN models and application fields including CNNs, LSTMs, and GANs for a number of approximate multipliers with distinct bitwidth values. The results show substantial error recovery from approximate re-training and reduced inference time up to 53.9x with respect to the baseline approximate implementation.