 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaPT: Fast Emulation of Approximate DNN Accelerators in PyTorch
Paper and Code
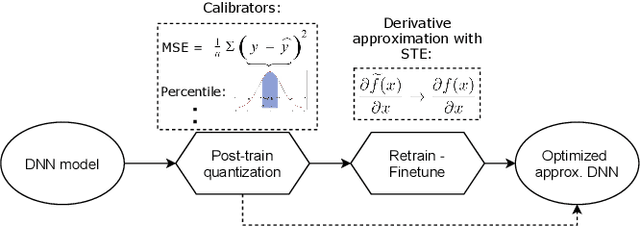
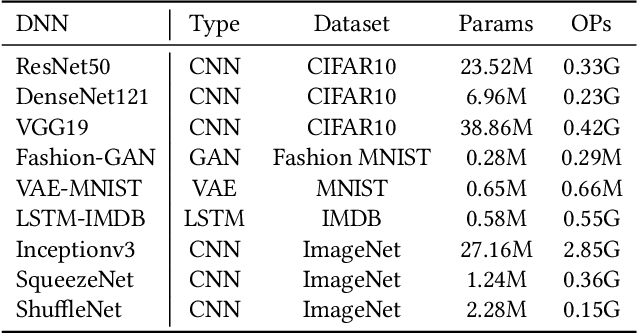
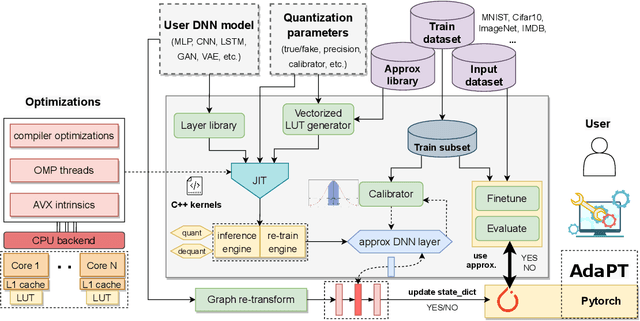

Current state-of-the-art employs approximate multipliers to address the highly increased power demands of DNN accelerators. However, evaluating the accuracy of approximate DNNs is cumbersome due to the lack of adequate support for approximate arithmetic in DNN frameworks. We address this inefficiency by presenting AdaPT, a fast emulation framework that extends PyTorch to support approximate inference as well as approximation-aware retraining. AdaPT can be seamlessly deployed and is compatible with the most DNNs. We evaluate the framework on several DNN models and application fields including CNNs, LSTMs, and GANs for a number of approximate multipliers with distinct bitwidth values. The results show substantial error recovery from approximate re-training and reduced inference time up to 53.9x with respect to the baseline approximate implementation.