 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Search Space Construction for Machine Learning Pipeline Synthesis
Paper and Code
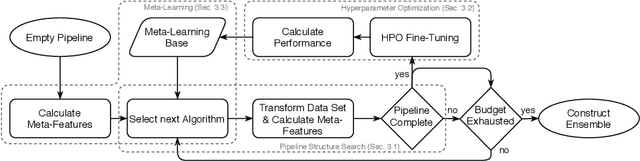
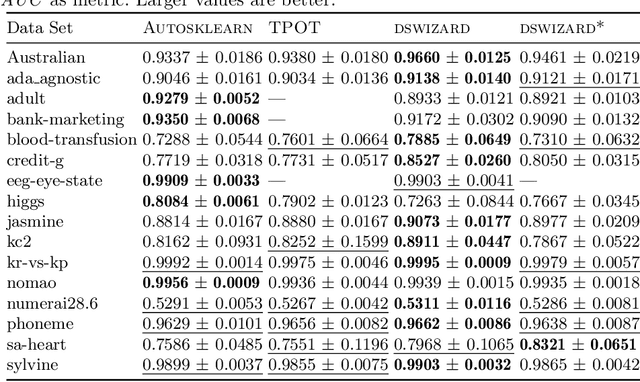
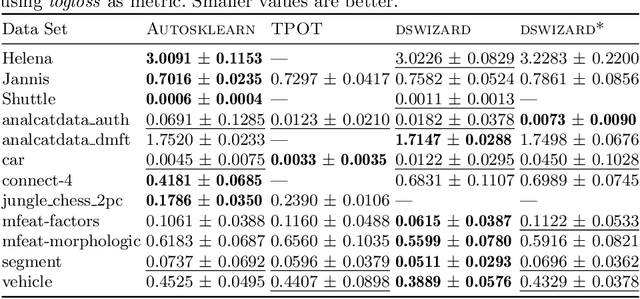
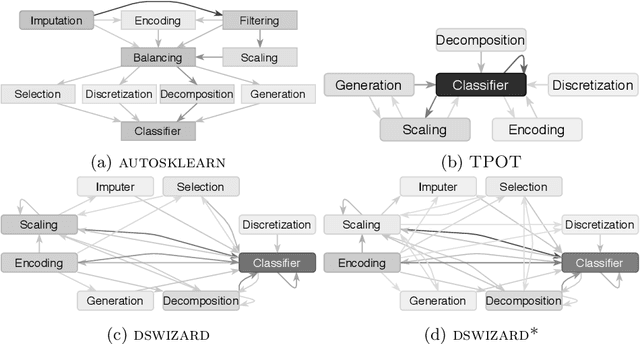
Automated machine learning (AutoML) aims for constructing machine learning (ML) pipelines automatically. Many studies have investigated efficient methods for algorithm selection and hyperparameter optimization. However, methods for ML pipeline synthesis and optimization considering the impact of complex pipeline structures containing multiple preprocessing and classification algorithms have not been studied thoroughly. In this paper, we propose a data-centric approach based on meta-features for pipeline construction and hyperparameter optimization inspired by human behavior. By expanding the pipeline search space incrementally in combination with meta-features of intermediate data sets, we are able to prune the pipeline structure search space efficiently. Consequently, flexible and data set specific ML pipelines can be constructed. We prove the effectiveness and competitiveness of our approach on 28 data sets used in well-established AutoML benchmarks in comparison with state-of-the-art AutoML frameworks.