 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning and the Early Estimation of Single-Photon Source Quality using Machine Learning Methods
Aug 21, 2024The use of single-photon sources (SPSs) is central to numerous systems and devices proposed amidst a modern surge in quantum technology. However, manufacturing schemes remain imperfect, and single-photon emission purity must often be experimentally verified via interferometry. Such a process is typically slow and costly, which has motivated growing research into whether SPS quality can be more rapidly inferred from incomplete emission statistics. Hence, this study is a sequel to previous work that demonstrated significant uncertainty in the standard method of quality estimation, i.e. the least-squares fitting of a physically motivated function, and asks: can machine learning (ML) do better? The study leverages eight datasets obtained from measurements involving an exemplary quantum emitter, i.e. a single InGaAs/GaAs epitaxial quantum dot; these eight contexts predominantly vary in the intensity of the exciting laser. Specifically, via a form of `transfer learning', five ML models, three linear and two ensemble-based, are trained on data from seven of the contexts and tested on the eighth. Validation metrics quickly reveal that even a linear regressor can outperform standard fitting when it is tested on the same contexts it was trained on, but the success of transfer learning is less assured, even though statistical analysis, made possible by data augmentation, suggests its superiority as an early estimator. Accordingly, the study concludes by discussing future strategies for grappling with the problem of SPS context dissimilarity, e.g. feature engineering and model adaptation.
The Challenge of Quickly Determining the Quality of a Single-Photon Source
Jun 22, 2023Novel methods for rapidly estimating single-photon source (SPS) quality, e.g. of quantum dots, have been promoted in recent literature to address the expensive and time-consuming nature of experimental validation via intensity interferometry. However, the frequent lack of uncertainty discussions and reproducible details raises concerns about their reliability. This study investigates one such proposal on eight datasets obtained from an InGaAs/GaAs epitaxial quantum dot that emits at 1.3 {\mu}m and is excited by an 80 MHz laser. The study introduces a novel contribution by employing data augmentation, a machine learning technique, to supplement experimental data with bootstrapped samples. Analysis of the SPS quality metric, i.e. the probability of multi-photon emission events, as derived from efficient histogram fitting of the synthetic samples, reveals significant uncertainty contributed by stochastic variability in the Poisson processes that describe detection rates. Ignoring this source of error risks severe overconfidence in both early quality estimates and claims for state-of-the-art SPS devices. Additionally, this study finds that standard least-squares fitting is comparable to the studied counter-proposal, expanding averages show some promise for early estimation, and reducing background counts improves fitting accuracy but does not address the Poisson-process variability. Ultimately, data augmentation demonstrates its value in supplementing physical experiments; its benefit here is to emphasise the need for a cautious assessment of SPS quality.
The Technological Emergence of AutoML: A Survey of Performant Software and Applications in the Context of Industry
Nov 08, 2022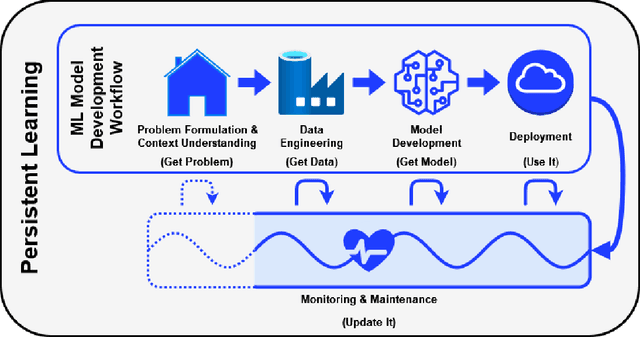
With most technical fields, there exists a delay between fundamental academic research and practical industrial uptake. Whilst some sciences have robust and well-established processes for commercialisation, such as the pharmaceutical practice of regimented drug trials, other fields face transitory periods in which fundamental academic advancements diffuse gradually into the space of commerce and industry. For the still relatively young field of Automated/Autonomous Machine Learning (AutoML/AutonoML), that transitory period is under way, spurred on by a burgeoning interest from broader society. Yet, to date, little research has been undertaken to assess the current state of this dissemination and its uptake. Thus, this review makes two primary contributions to knowledge around this topic. Firstly, it provides the most up-to-date and comprehensive survey of existing AutoML tools, both open-source and commercial. Secondly, it motivates and outlines a framework for assessing whether an AutoML solution designed for real-world application is 'performant'; this framework extends beyond the limitations of typical academic criteria, considering a variety of stakeholder needs and the human-computer interactions required to service them. Thus, additionally supported by an extensive assessment and comparison of academic and commercial case-studies, this review evaluates mainstream engagement with AutoML in the early 2020s, identifying obstacles and opportunities for accelerating future uptake.
On Taking Advantage of Opportunistic Meta-knowledge to Reduce Configuration Spaces for Automated Machine Learning
Aug 08, 2022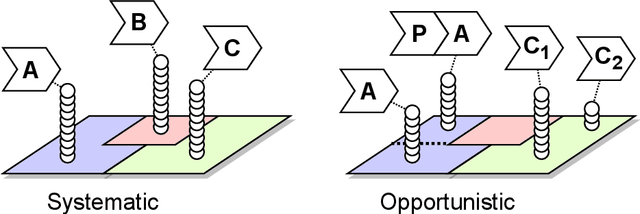
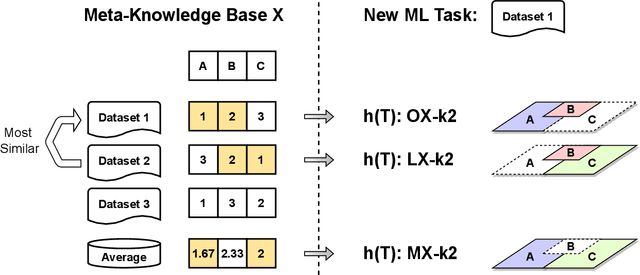
The automated machine learning (AutoML) process can require searching through complex configuration spaces of not only machine learning (ML) components and their hyperparameters but also ways of composing them together, i.e. forming ML pipelines. Optimisation efficiency and the model accuracy attainable for a fixed time budget suffer if this pipeline configuration space is excessively large. A key research question is whether it is both possible and practical to preemptively avoid costly evaluations of poorly performing ML pipelines by leveraging their historical performance for various ML tasks, i.e. meta-knowledge. The previous experience comes in the form of classifier/regressor accuracy rankings derived from either (1) a substantial but non-exhaustive number of pipeline evaluations made during historical AutoML runs, i.e. 'opportunistic' meta-knowledge, or (2) comprehensive cross-validated evaluations of classifiers/regressors with default hyperparameters, i.e. 'systematic' meta-knowledge. Numerous experiments with the AutoWeka4MCPS package suggest that (1) opportunistic/systematic meta-knowledge can improve ML outcomes, typically in line with how relevant that meta-knowledge is, and (2) configuration-space culling is optimal when it is neither too conservative nor too radical. However, the utility and impact of meta-knowledge depend critically on numerous facets of its generation and exploitation, warranting extensive analysis; these are often overlooked/underappreciated within AutoML and meta-learning literature. In particular, we observe strong sensitivity to the `challenge' of a dataset, i.e. whether specificity in choosing a predictor leads to significantly better performance. Ultimately, identifying `difficult' datasets, thus defined, is crucial to both generating informative meta-knowledge bases and understanding optimal search-space reduction strategies.
The Roles and Modes of Human Interactions with Automated Machine Learning Systems
May 09, 2022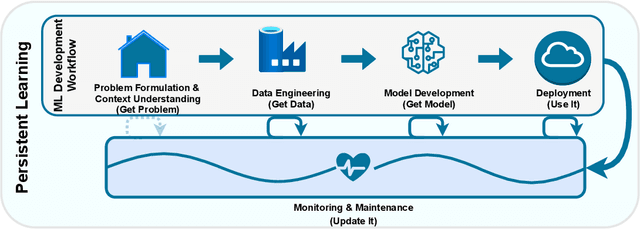
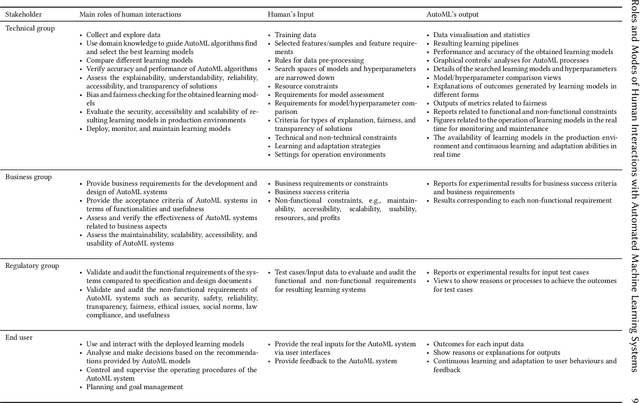
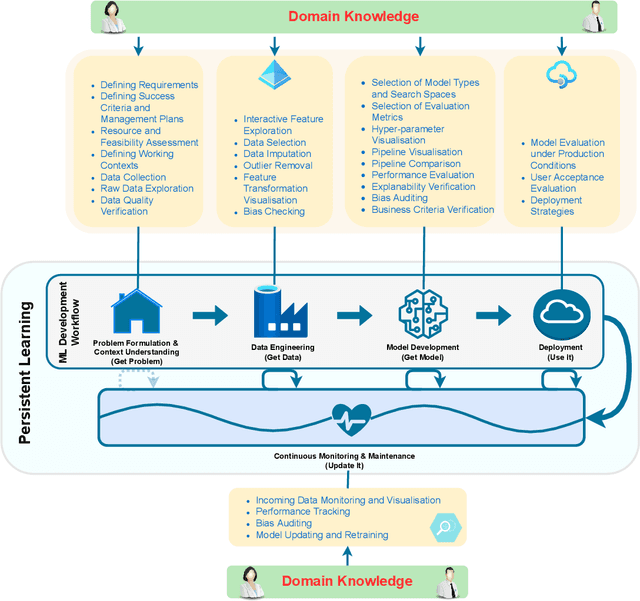
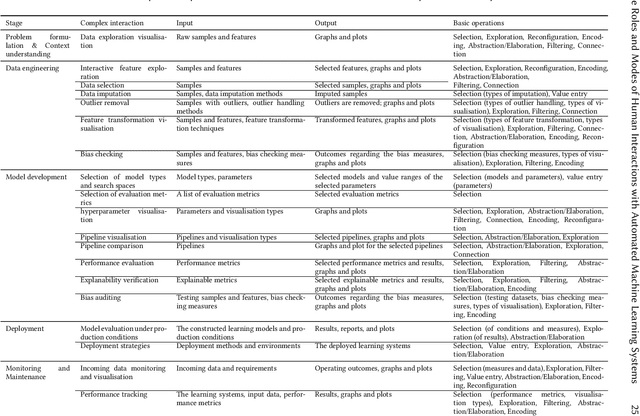
As automated machine learning (AutoML) systems continue to progress in both sophistication and performance, it becomes important to understand the `how' and `why' of human-computer interaction (HCI) within these frameworks, both current and expected. Such a discussion is necessary for optimal system design, leveraging advanced data-processing capabilities to support decision-making involving humans, but it is also key to identifying the opportunities and risks presented by ever-increasing levels of machine autonomy. Within this context, we focus on the following questions: (i) How does HCI currently look like for state-of-the-art AutoML algorithms, especially during the stages of development, deployment, and maintenance? (ii) Do the expectations of HCI within AutoML frameworks vary for different types of users and stakeholders? (iii) How can HCI be managed so that AutoML solutions acquire human trust and broad acceptance? (iv) As AutoML systems become more autonomous and capable of learning from complex open-ended environments, will the fundamental nature of HCI evolve? To consider these questions, we project existing literature in HCI into the space of AutoML; this connection has, to date, largely been unexplored. In so doing, we review topics including user-interface design, human-bias mitigation, and trust in artificial intelligence (AI). Additionally, to rigorously gauge the future of HCI, we contemplate how AutoML may manifest in effectively open-ended environments. This discussion necessarily reviews projected developmental pathways for AutoML, such as the incorporation of reasoning, although the focus remains on how and why HCI may occur in such a framework rather than on any implementational details. Ultimately, this review serves to identify key research directions aimed at better facilitating the roles and modes of human interactions with both current and future AutoML systems.
Automated Deep Learning: Neural Architecture Search Is Not the End
Jan 21, 2022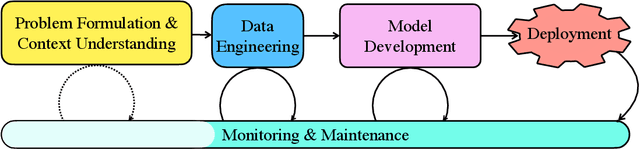
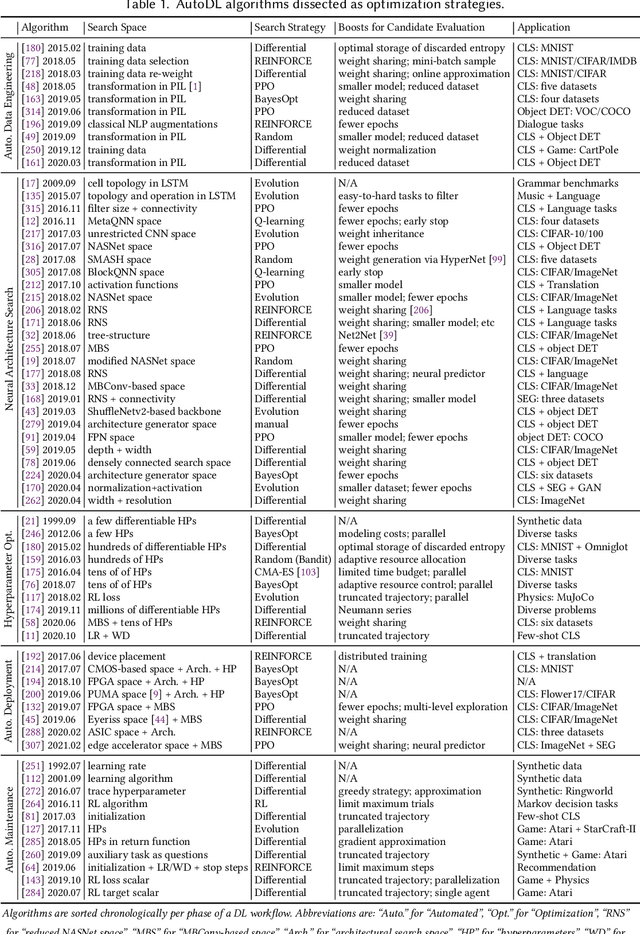
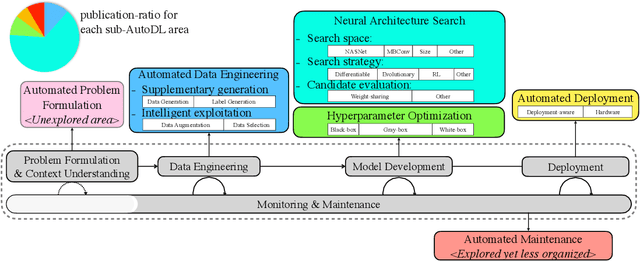
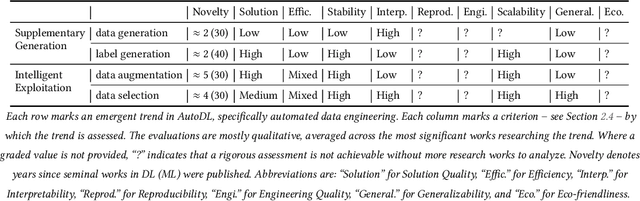
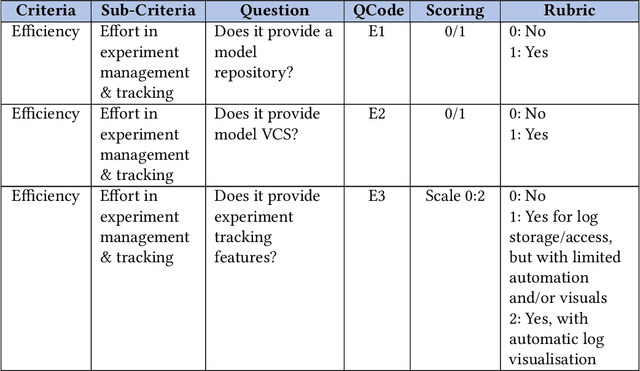
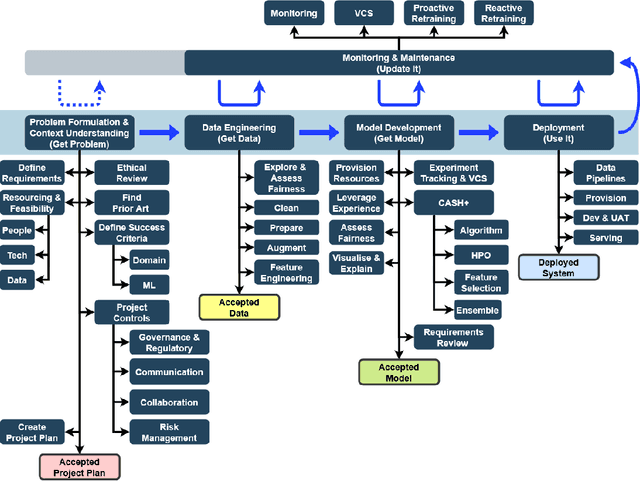
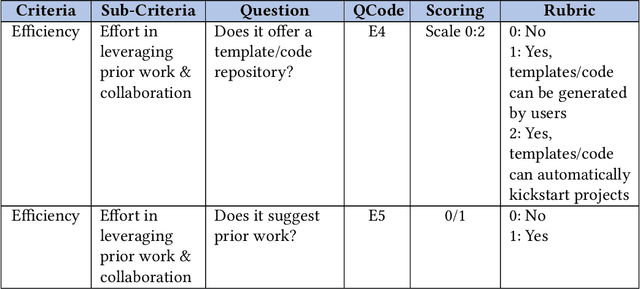
Deep learning (DL) has proven to be a highly effective approach for developing models in diverse contexts, including visual perception, speech recognition, and machine translation. However, the end-to-end process for applying DL is not trivial. It requires grappling with problem formulation and context understanding, data engineering, model development, deployment, continuous monitoring and maintenance, and so on. Moreover, each of these steps typically relies heavily on humans, in terms of both knowledge and interactions, which impedes the further advancement and democratization of DL. Consequently, in response to these issues, a new field has emerged over the last few years: automated deep learning (AutoDL). This endeavor seeks to minimize the need for human involvement and is best known for its achievements in neural architecture search (NAS), a topic that has been the focus of several surveys. That stated, NAS is not the be-all and end-all of AutoDL. Accordingly, this review adopts an overarching perspective, examining research efforts into automation across the entirety of an archetypal DL workflow. In so doing, this work also proposes a comprehensive set of ten criteria by which to assess existing work in both individual publications and broader research areas. These criteria are: novelty, solution quality, efficiency, stability, interpretability, reproducibility, engineering quality, scalability, generalizability, and eco-friendliness. Thus, ultimately, this review provides an evaluative overview of AutoDL in the early 2020s, identifying where future opportunities for progress may exist.
Exploring Opportunistic Meta-knowledge to Reduce Search Spaces for Automated Machine Learning
May 01, 2021
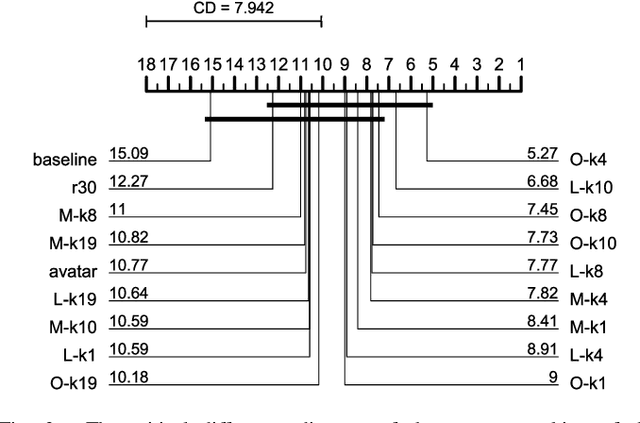
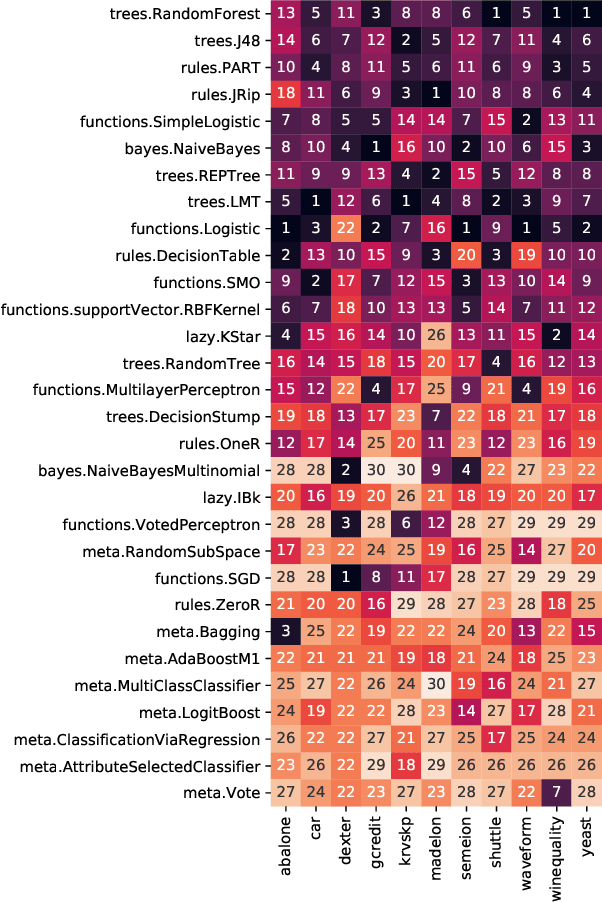
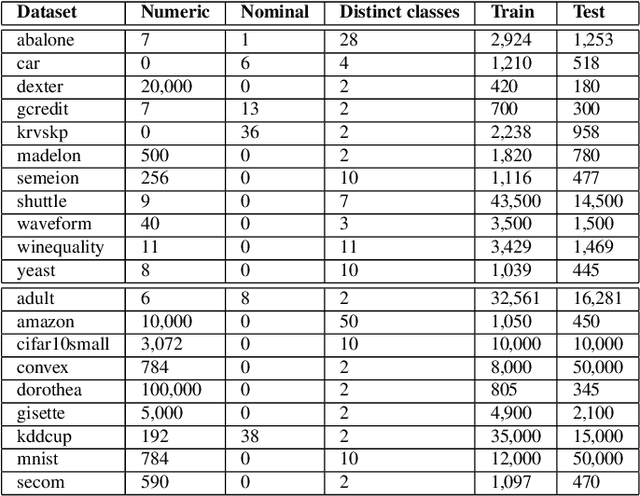
Machine learning (ML) pipeline composition and optimisation have been studied to seek multi-stage ML models, i.e. preprocessor-inclusive, that are both valid and well-performing. These processes typically require the design and traversal of complex configuration spaces consisting of not just individual ML components and their hyperparameters, but also higher-level pipeline structures that link these components together. Optimisation efficiency and resulting ML-model accuracy both suffer if this pipeline search space is unwieldy and excessively large; it becomes an appealing notion to avoid costly evaluations of poorly performing ML components ahead of time. Accordingly, this paper investigates whether, based on previous experience, a pool of available classifiers/regressors can be preemptively culled ahead of initiating a pipeline composition/optimisation process for a new ML problem, i.e. dataset. The previous experience comes in the form of classifier/regressor accuracy rankings derived, with loose assumptions, from a substantial but non-exhaustive number of pipeline evaluations; this meta-knowledge is considered 'opportunistic'. Numerous experiments with the AutoWeka4MCPS package, including ones leveraging similarities between datasets via the relative landmarking method, show that, despite its seeming unreliability, opportunistic meta-knowledge can improve ML outcomes. However, results also indicate that the culling of classifiers/regressors should not be too severe either. In effect, it is better to search through a 'top tier' of recommended predictors than to pin hopes onto one previously supreme performer.
AutonoML: Towards an Integrated Framework for Autonomous Machine Learning
Dec 23, 2020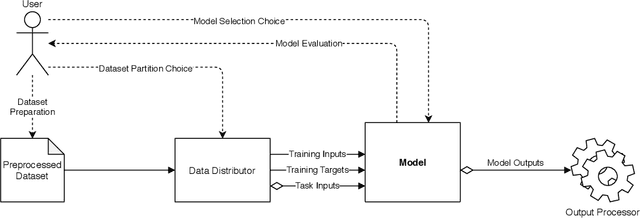
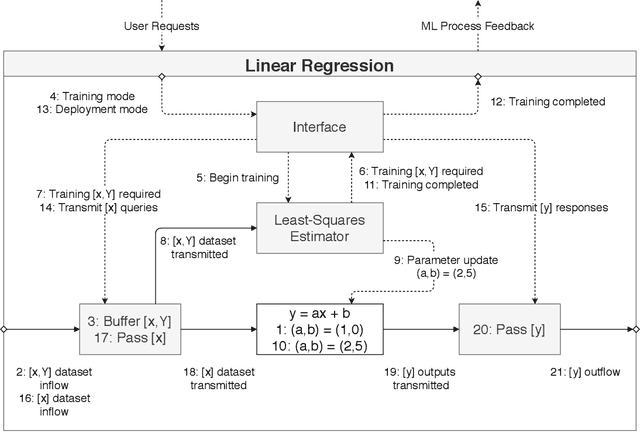
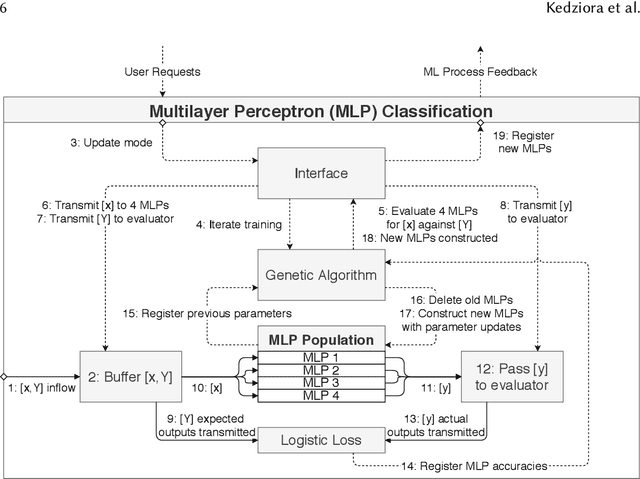
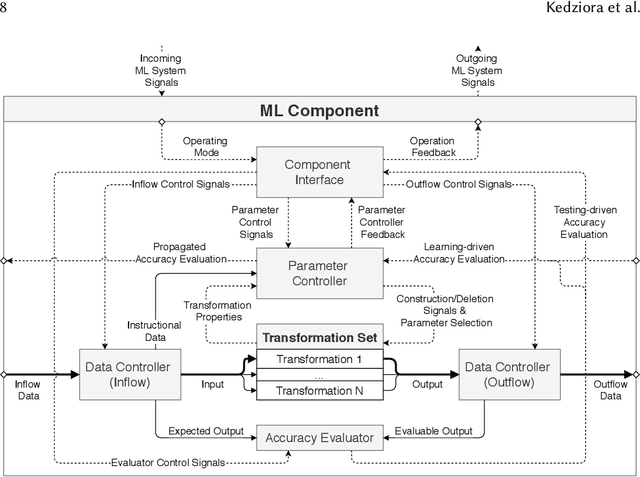
Over the last decade, the long-running endeavour to automate high-level processes in machine learning (ML) has risen to mainstream prominence, stimulated by advances in optimisation techniques and their impact on selecting ML models/algorithms. Central to this drive is the appeal of engineering a computational system that both discovers and deploys high-performance solutions to arbitrary ML problems with minimal human interaction. Beyond this, an even loftier goal is the pursuit of autonomy, which describes the capability of the system to independently adjust an ML solution over a lifetime of changing contexts. However, these ambitions are unlikely to be achieved in a robust manner without the broader synthesis of various mechanisms and theoretical frameworks, which, at the present time, remain scattered across numerous research threads. Accordingly, this review seeks to motivate a more expansive perspective on what constitutes an automated/autonomous ML system, alongside consideration of how best to consolidate those elements. In doing so, we survey developments in the following research areas: hyperparameter optimisation, multi-component models, neural architecture search, automated feature engineering, meta-learning, multi-level ensembling, dynamic adaptation, multi-objective evaluation, resource constraints, flexible user involvement, and the principles of generalisation. We also develop a conceptual framework throughout the review, augmented by each topic, to illustrate one possible way of fusing high-level mechanisms into an autonomous ML system. Ultimately, we conclude that the notion of architectural integration deserves more discussion, without which the field of automated ML risks stifling both its technical advantages and general uptake.