 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Methods for Small Data and Upstream Bioprocessing Applications: A Comprehensive Review
Jun 14, 2025Data is crucial for machine learning (ML) applications, yet acquiring large datasets can be costly and time-consuming, especially in complex, resource-intensive fields like biopharmaceuticals. A key process in this industry is upstream bioprocessing, where living cells are cultivated and optimised to produce therapeutic proteins and biologics. The intricate nature of these processes, combined with high resource demands, often limits data collection, resulting in smaller datasets. This comprehensive review explores ML methods designed to address the challenges posed by small data and classifies them into a taxonomy to guide practical applications. Furthermore, each method in the taxonomy was thoroughly analysed, with a detailed discussion of its core concepts and an evaluation of its effectiveness in tackling small data challenges, as demonstrated by application results in the upstream bioprocessing and other related domains. By analysing how these methods tackle small data challenges from different perspectives, this review provides actionable insights, identifies current research gaps, and offers guidance for leveraging ML in data-constrained environments.
Hyperbox Mixture Regression for Process Performance Prediction in Antibody Production
Nov 03, 2024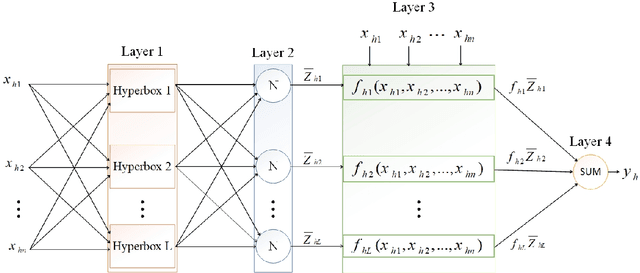
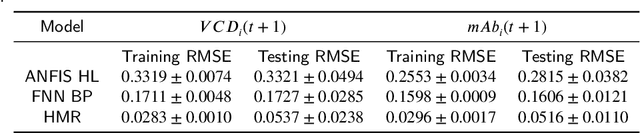
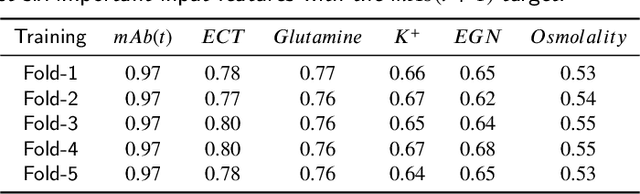
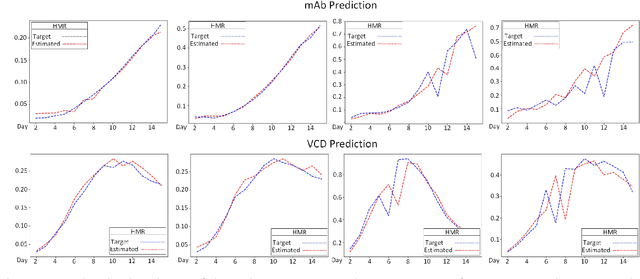
This paper addresses the challenges of predicting bioprocess performance, particularly in monoclonal antibody (mAb) production, where conventional statistical methods often fall short due to time-series data's complexity and high dimensionality. We propose a novel Hyperbox Mixture Regression (HMR) model which employs hyperbox-based input space partitioning to enhance predictive accuracy while managing uncertainty inherent in bioprocess data. The HMR model is designed to dynamically generate hyperboxes for input samples in a single-pass process, thereby improving learning speed and reducing computational complexity. Our experimental study utilizes a dataset that contains 106 bioreactors. This study evaluates the model's performance in predicting critical quality attributes in monoclonal antibody manufacturing over a 15-day cultivation period. The results demonstrate that the HMR model outperforms comparable approximators in accuracy and learning speed and maintains interpretability and robustness under uncertain conditions. These findings underscore the potential of HMR as a powerful tool for enhancing predictive analytics in bioprocessing applications.
Uncertainty Quantification Using Ensemble Learning and Monte Carlo Sampling for Performance Prediction and Monitoring in Cell Culture Processes
Sep 03, 2024



Biopharmaceutical products, particularly monoclonal antibodies (mAbs), have gained prominence in the pharmaceutical market due to their high specificity and efficacy. As these products are projected to constitute a substantial portion of global pharmaceutical sales, the application of machine learning models in mAb development and manufacturing is gaining momentum. This paper addresses the critical need for uncertainty quantification in machine learning predictions, particularly in scenarios with limited training data. Leveraging ensemble learning and Monte Carlo simulations, our proposed method generates additional input samples to enhance the robustness of the model in small training datasets. We evaluate the efficacy of our approach through two case studies: predicting antibody concentrations in advance and real-time monitoring of glucose concentrations during bioreactor runs using Raman spectra data. Our findings demonstrate the effectiveness of the proposed method in estimating the uncertainty levels associated with process performance predictions and facilitating real-time decision-making in biopharmaceutical manufacturing. This contribution not only introduces a novel approach for uncertainty quantification but also provides insights into overcoming challenges posed by small training datasets in bioprocess development. The evaluation demonstrates the effectiveness of our method in addressing key challenges related to uncertainty estimation within upstream cell cultivation, illustrating its potential impact on enhancing process control and product quality in the dynamic field of biopharmaceuticals.
Applications of Machine Learning in Biopharmaceutical Process Development and Manufacturing: Current Trends, Challenges, and Opportunities
Oct 16, 2023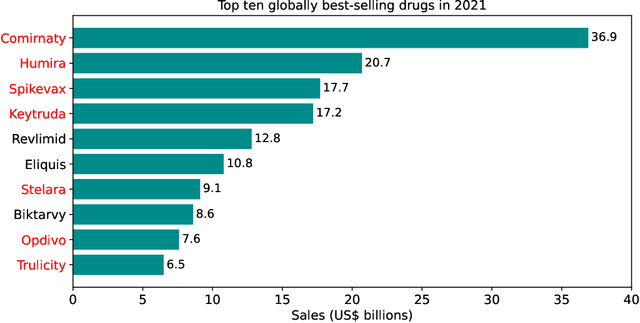

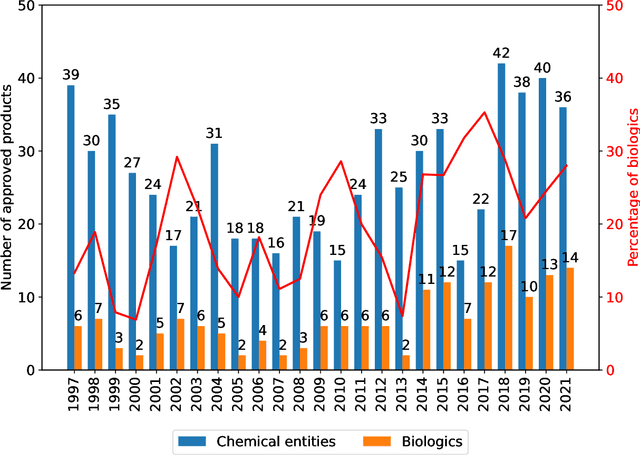
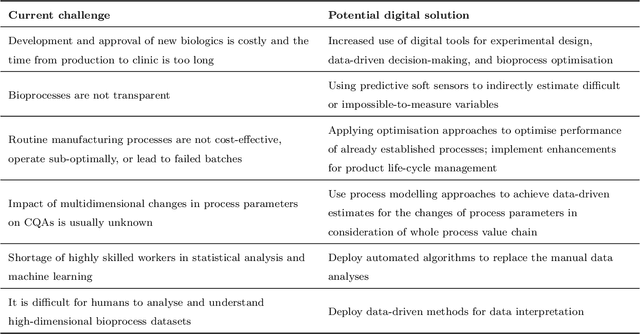
While machine learning (ML) has made significant contributions to the biopharmaceutical field, its applications are still in the early stages in terms of providing direct support for quality-by-design based development and manufacturing of biopharmaceuticals, hindering the enormous potential for bioprocesses automation from their development to manufacturing. However, the adoption of ML-based models instead of conventional multivariate data analysis methods is significantly increasing due to the accumulation of large-scale production data. This trend is primarily driven by the real-time monitoring of process variables and quality attributes of biopharmaceutical products through the implementation of advanced process analytical technologies. Given the complexity and multidimensionality of a bioproduct design, bioprocess development, and product manufacturing data, ML-based approaches are increasingly being employed to achieve accurate, flexible, and high-performing predictive models to address the problems of analytics, monitoring, and control within the biopharma field. This paper aims to provide a comprehensive review of the current applications of ML solutions in a bioproduct design, monitoring, control, and optimisation of upstream, downstream, and product formulation processes. Finally, this paper thoroughly discusses the main challenges related to the bioprocesses themselves, process data, and the use of machine learning models in biopharmaceutical process development and manufacturing. Moreover, it offers further insights into the adoption of innovative machine learning methods and novel trends in the development of new digital biopharma solutions.
hyperbox-brain: A Toolbox for Hyperbox-based Machine Learning Algorithms
Oct 06, 2022
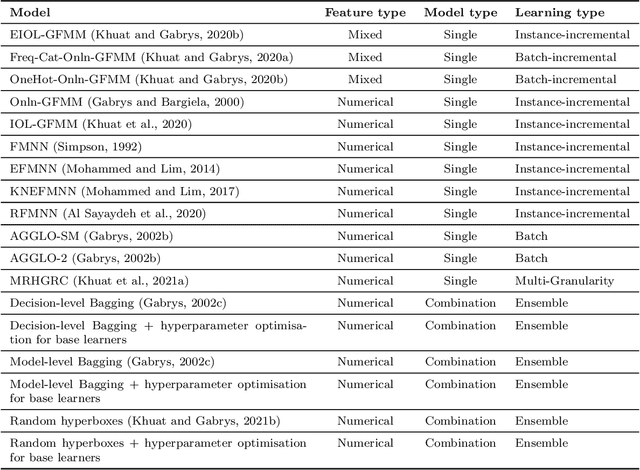
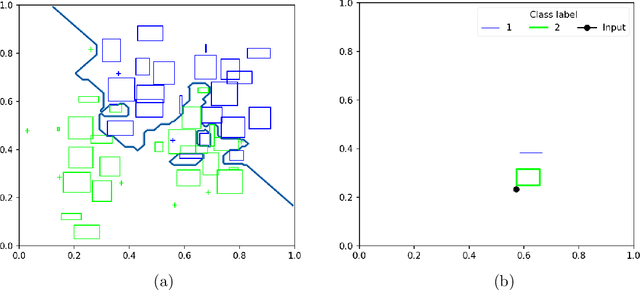

Hyperbox-based machine learning algorithms are an important and popular branch of machine learning in the construction of classifiers using fuzzy sets and logic theory and neural network architectures. This type of learning is characterised by many strong points of modern predictors such as a high scalability, explainability, online adaptation, effective learning from a small amount of data, native ability to deal with missing data and accommodating new classes. Nevertheless, there is no comprehensive existing package for hyperbox-based machine learning which can serve as a benchmark for research and allow non-expert users to apply these algorithms easily. hyperbox-brain is an open-source Python library implementing the leading hyperbox-based machine learning algorithms. This library exposes a unified API which closely follows and is compatible with the renowned scikit-learn and numpy toolboxes. The library may be installed from Python Package Index (PyPI) and the conda package manager and is distributed under the GPL-3 license. The source code, documentation, detailed tutorials, and the full descriptions of the API are available at https://uts-caslab.github.io/hyperbox-brain.
The Roles and Modes of Human Interactions with Automated Machine Learning Systems
May 09, 2022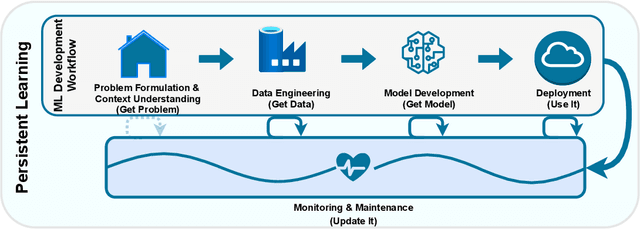
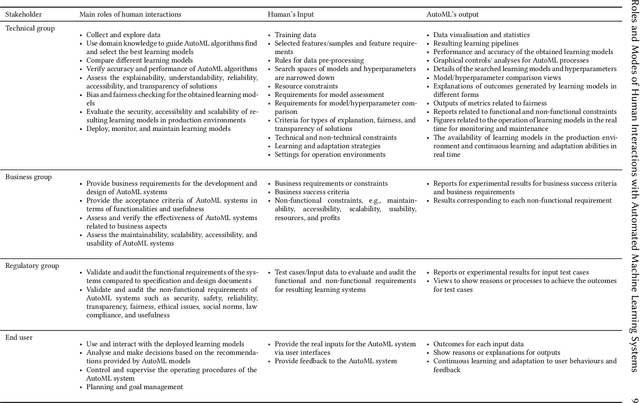
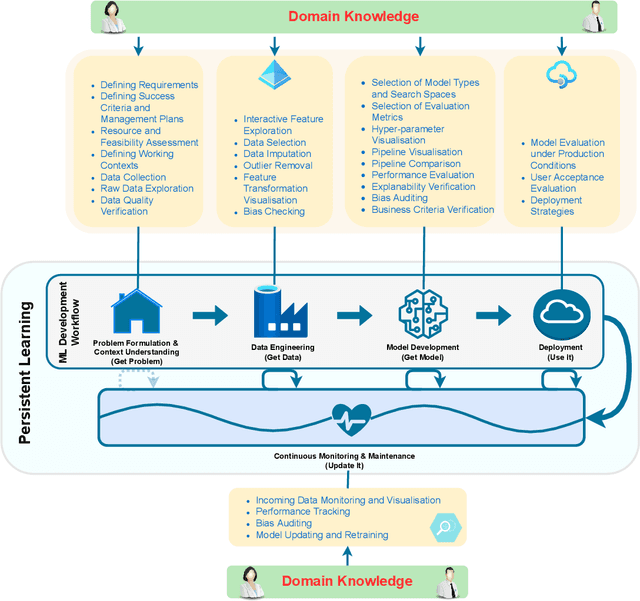
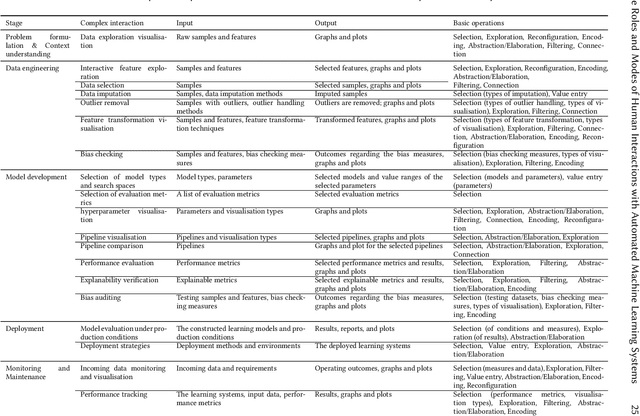
As automated machine learning (AutoML) systems continue to progress in both sophistication and performance, it becomes important to understand the `how' and `why' of human-computer interaction (HCI) within these frameworks, both current and expected. Such a discussion is necessary for optimal system design, leveraging advanced data-processing capabilities to support decision-making involving humans, but it is also key to identifying the opportunities and risks presented by ever-increasing levels of machine autonomy. Within this context, we focus on the following questions: (i) How does HCI currently look like for state-of-the-art AutoML algorithms, especially during the stages of development, deployment, and maintenance? (ii) Do the expectations of HCI within AutoML frameworks vary for different types of users and stakeholders? (iii) How can HCI be managed so that AutoML solutions acquire human trust and broad acceptance? (iv) As AutoML systems become more autonomous and capable of learning from complex open-ended environments, will the fundamental nature of HCI evolve? To consider these questions, we project existing literature in HCI into the space of AutoML; this connection has, to date, largely been unexplored. In so doing, we review topics including user-interface design, human-bias mitigation, and trust in artificial intelligence (AI). Additionally, to rigorously gauge the future of HCI, we contemplate how AutoML may manifest in effectively open-ended environments. This discussion necessarily reviews projected developmental pathways for AutoML, such as the incorporation of reasoning, although the focus remains on how and why HCI may occur in such a framework rather than on any implementational details. Ultimately, this review serves to identify key research directions aimed at better facilitating the roles and modes of human interactions with both current and future AutoML systems.
An Online Learning Algorithm for a Neuro-Fuzzy Classifier with Mixed-Attribute Data
Sep 30, 2020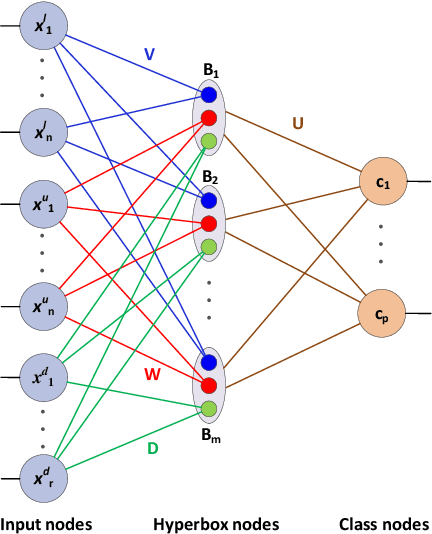


General fuzzy min-max neural network (GFMMNN) is one of the efficient neuro-fuzzy systems for data classification. However, one of the downsides of its original learning algorithms is the inability to handle and learn from the mixed-attribute data. While categorical features encoding methods can be used with the GFMMNN learning algorithms, they exhibit a lot of shortcomings. Other approaches proposed in the literature are not suitable for on-line learning as they require entire training data available in the learning phase. With the rapid change in the volume and velocity of streaming data in many application areas, it is increasingly required that the constructed models can learn and adapt to the continuous data changes in real-time without the need for their full retraining or access to the historical data. This paper proposes an extended online learning algorithm for the GFMMNN. The proposed method can handle the datasets with both continuous and categorical features. The extensive experiments confirmed superior and stable classification performance of the proposed approach in comparison to other relevant learning algorithms for the GFMM model.
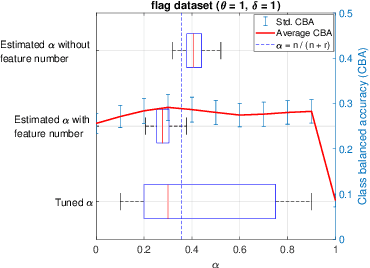
An in-depth comparison of methods handling mixed-attribute data for general fuzzy min-max neural network
Sep 01, 2020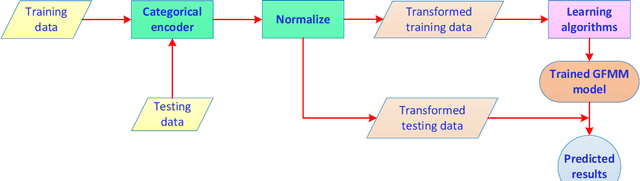
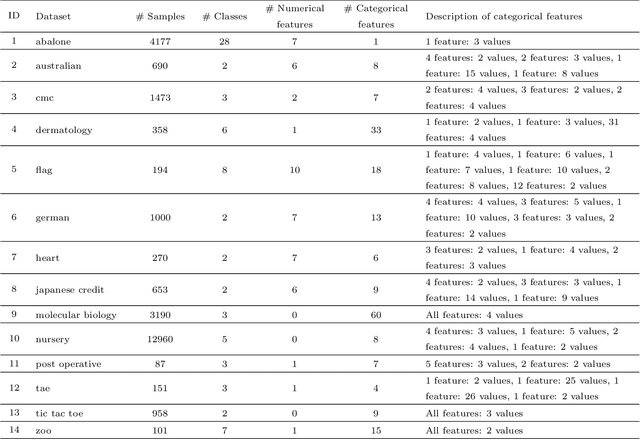
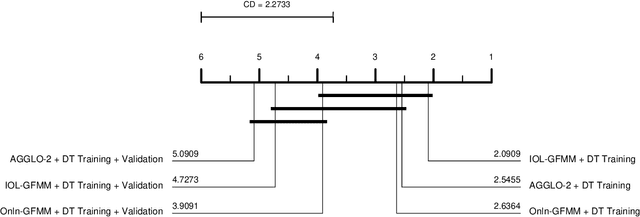
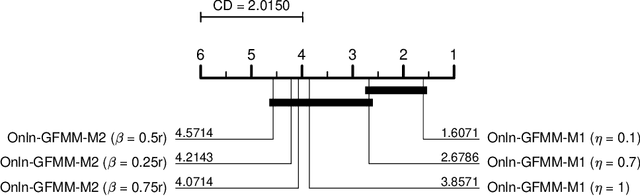
A general fuzzy min-max (GFMM) neural network is one of the efficient neuro-fuzzy systems for classification problems. However, a disadvantage of most of the current learning algorithms for GFMM is that they can handle effectively numerical valued features only. Therefore, this paper provides some potential approaches to adapting GFMM learning algorithms for classification problems with mixed-type or only categorical features as they are very common in practical applications and often carry very useful information. We will compare and assess three main methods of handling datasets with mixed features, including the use of encoding methods, the combination of the GFMM model with other classifiers, and employing the specific learning algorithms for both types of features. The experimental results showed that the target and James-Stein are appropriate categorical encoding methods for learning algorithms of GFMM models, while the combination of GFMM neural networks and decision trees is a flexible way to enhance the classification performance of GFMM models on datasets with the mixed features. The learning algorithms with the mixed-type feature abilities are potential approaches to deal with mixed-attribute data in a natural way, but they need further improvement to achieve a better classification accuracy. Based on the analysis, we also identify the strong and weak points of different methods and propose potential research directions.
Random Hyperboxes
Jun 01, 2020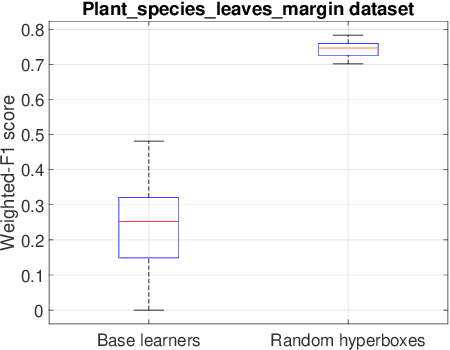
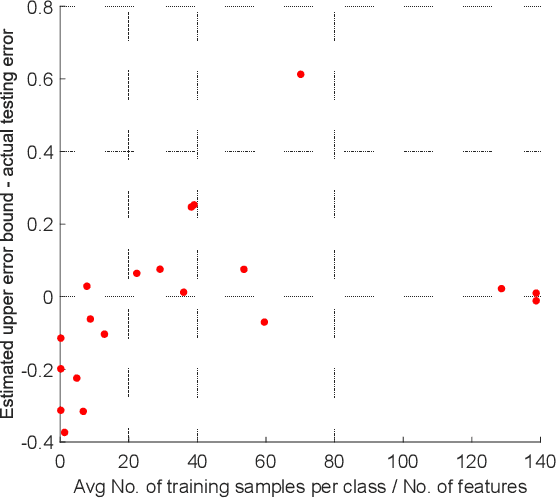


This paper proposes a simple yet powerful ensemble classifier, called Random Hyperboxes, constructed from individual hyperbox-based classifiers trained on the random subsets of sample and feature spaces of the training set. We also show a generalization error bound of the proposed classifier based on the strength of the individual hyperbox-based classifiers as well as the correlation among them. The effectiveness of the proposed classifier is analyzed using a carefully selected illustrative example and compared empirically with other popular single and ensemble classifiers via 20 datasets using statistical testing methods. The experimental results confirmed that our proposed method outperformed other fuzzy min-max neural networks, popular learning algorithms, and is competitive with other ensemble methods. Finally, we identify the existing issues related to the generalization error bounds of the real datasets and inform the potential research directions.
Accelerated learning algorithms of general fuzzy min-max neural network using a branch-and-bound-based hyperbox selection rule
Mar 25, 2020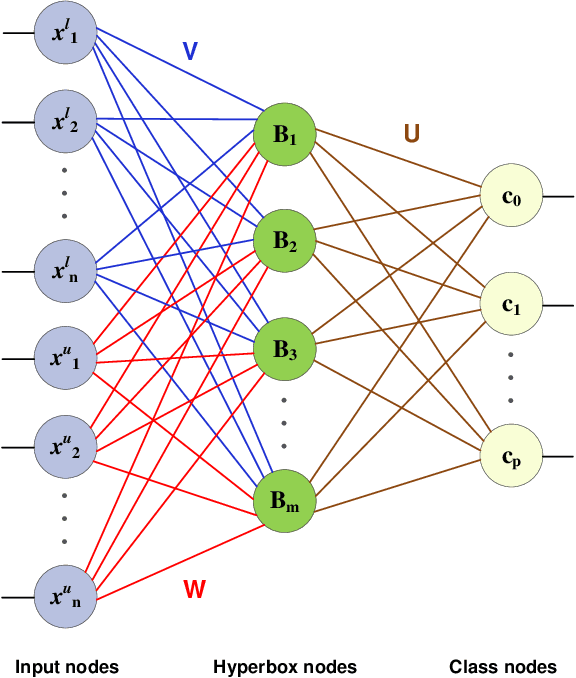
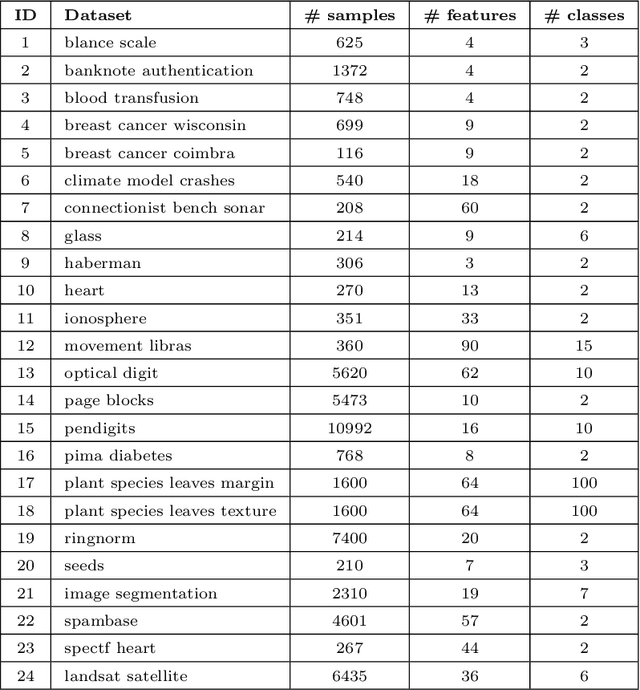
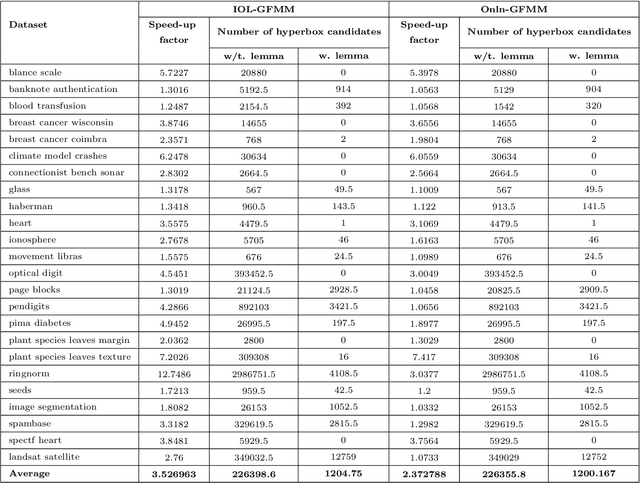
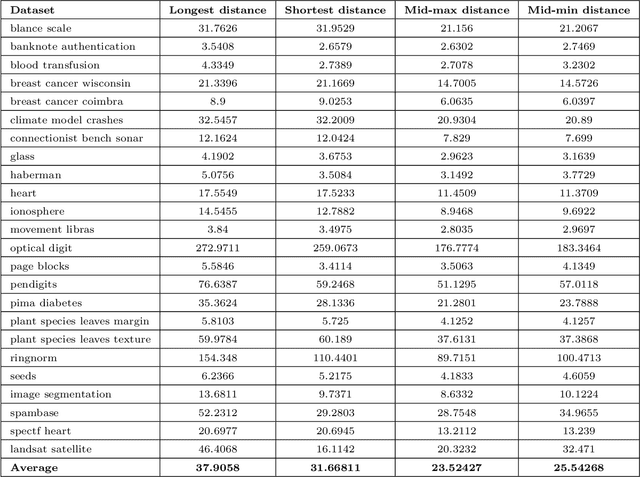
This paper proposes a method to accelerate the training process of general fuzzy min-max neural network. The purpose is to reduce the unsuitable hyperboxes selected as the potential candidates of the expansion step of existing hyperboxes to cover a new input pattern in the online learning algorithms or candidates of the hyperbox aggregation process in the agglomerative learning algorithms. Our proposed approach is based on the mathematical formulas to form a branch-and-bound solution aiming to remove the hyperboxes which are certain not to satisfy expansion or aggregation conditions, and in turn decreasing the training time of learning algorithms. The efficiency of the proposed method is assessed over a number of widely used data sets. The experimental results indicated the significant decrease in training time of proposed approach for both online and agglomerative learning algorithms. Notably, the training time of the online learning algorithms is reduced from 1.2 to 12 times when using the proposed method, while the agglomerative learning algorithms are accelerated from 7 to 37 times on average.