 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVATAR -- Machine Learning Pipeline Evaluation Using Surrogate Model
Feb 03, 2020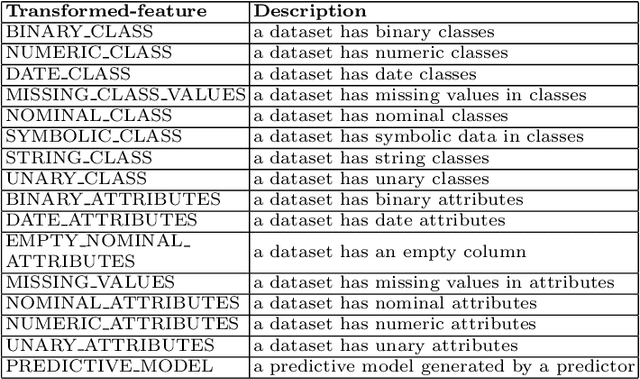
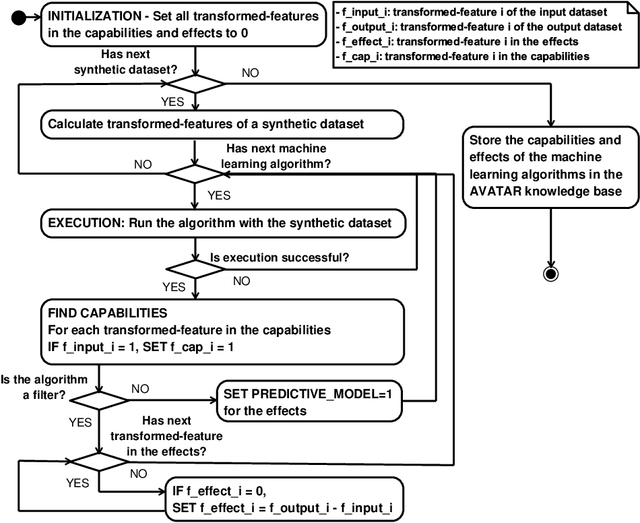
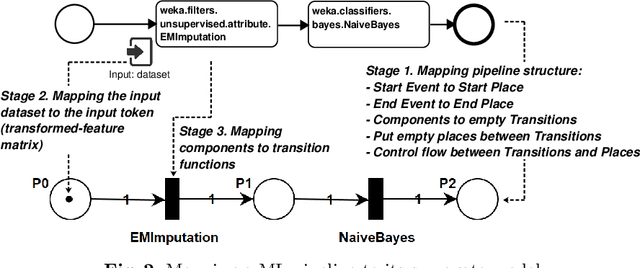
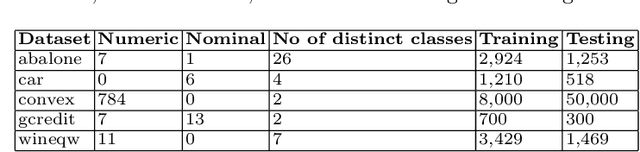
The evaluation of machine learning (ML) pipelines is essential during automatic ML pipeline composition and optimisation. The previous methods such as Bayesian-based and genetic-based optimisation, which are implemented in Auto-Weka, Auto-sklearn and TPOT, evaluate pipelines by executing them. Therefore, the pipeline composition and optimisation of these methods requires a tremendous amount of time that prevents them from exploring complex pipelines to find better predictive models. To further explore this research challenge, we have conducted experiments showing that many of the generated pipelines are invalid, and it is unnecessary to execute them to find out whether they are good pipelines. To address this issue, we propose a novel method to evaluate the validity of ML pipelines using a surrogate model (AVATAR). The AVATAR enables to accelerate automatic ML pipeline composition and optimisation by quickly ignoring invalid pipelines. Our experiments show that the AVATAR is more efficient in evaluating complex pipelines in comparison with the traditional evaluation approaches requiring their execution.
Support Feature Machines
Jan 28, 2019
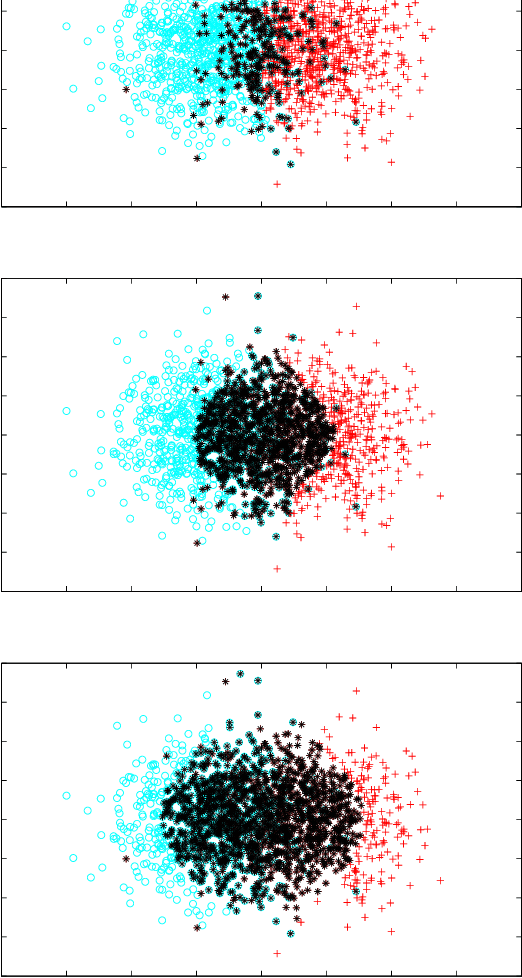
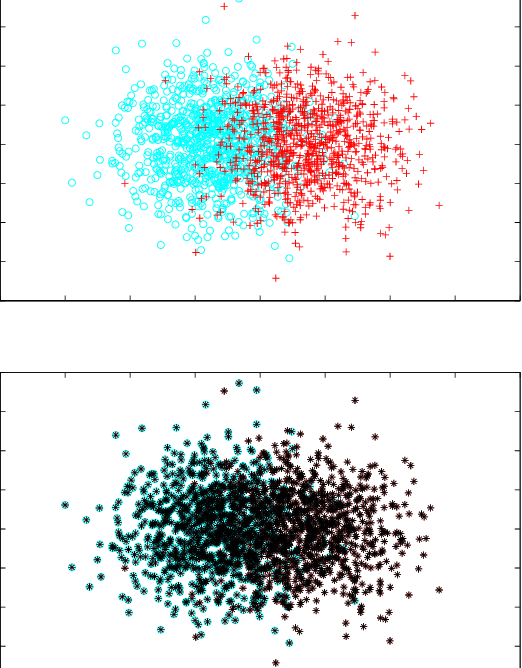
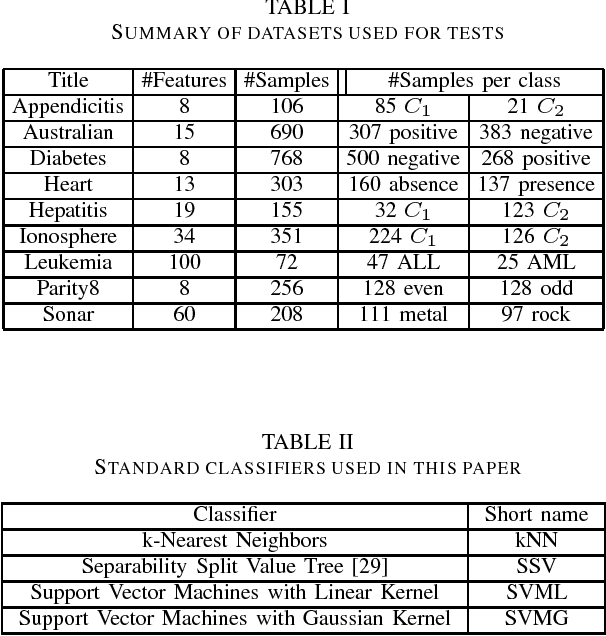
Support Vector Machines (SVMs) with various kernels have played dominant role in machine learning for many years, finding numerous applications. Although they have many attractive features interpretation of their solutions is quite difficult, the use of a single kernel type may not be appropriate in all areas of the input space, convergence problems for some kernels are not uncommon, the standard quadratic programming solution has $O(m^3)$ time and $O(m^2)$ space complexity for $m$ training patterns. Kernel methods work because they implicitly provide new, useful features. Such features, derived from various kernels and other vector transformations, may be used directly in any machine learning algorithm, facilitating multiresolution, heterogeneous models of data. Therefore Support Feature Machines (SFM) based on linear models in the extended feature spaces, enabling control over selection of support features, give at least as good results as any kernel-based SVMs, removing all problems related to interpretation, scaling and convergence. This is demonstrated for a number of benchmark datasets analyzed with linear discrimination, SVM, decision trees and nearest neighbor methods.
* 8 pages, 9 figs. More at http://www.is.umk.pl/~duch/cv/WD-topics.html