 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive ASR: Towards Human-Like Interaction and Semantic Coherence Evaluation for Agentic Speech Recognition
Apr 14, 2026Recent years have witnessed remarkable progress in automatic speech recognition (ASR), driven by advances in model architectures and large-scale training data. However, two important aspects remain underexplored. First, Word Error Rate (WER), the dominant evaluation metric for decades, treats all words equally and often fails to reflect the semantic correctness of an utterance at the sentence level. Second, interactive correction-an essential component of human communication-has rarely been systematically studied in ASR research. In this paper, we integrate these two perspectives under an agentic framework for interactive ASR. We propose leveraging LLM-as-a-Judge as a semantic-aware evaluation metric to assess recognition quality beyond token-level accuracy. Furthermore, we design an LLM-driven agent framework to simulate human-like multi-turn interaction, enabling iterative refinement of recognition outputs through semantic feedback. Extensive experiments are conducted on standard benchmarks, including GigaSpeech (English), WenetSpeech (Chinese), the ASRU 2019 code-switching test set. Both objective and subjective evaluations demonstrate the effectiveness of the proposed framework in improving semantic fidelity and interactive correction capability. We will release the code to facilitate future research in interactive and agentic ASR.
FunAudio-ASR Technical Report
Sep 15, 2025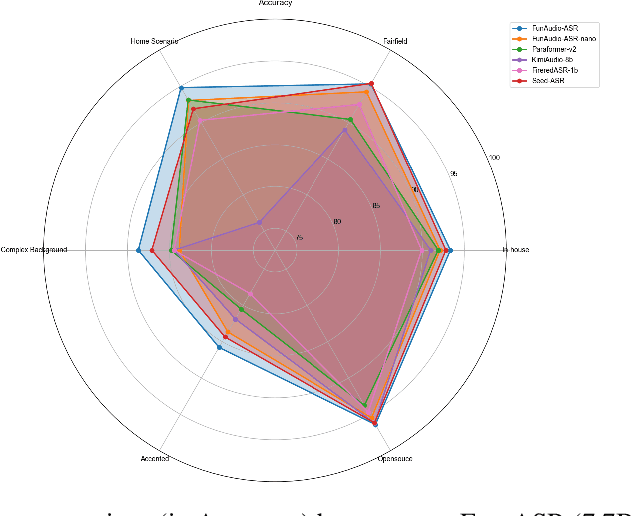
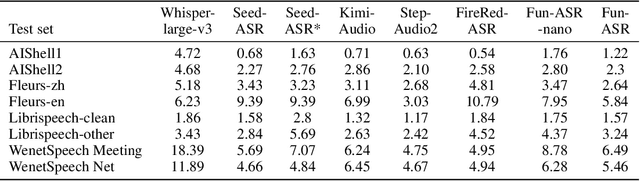
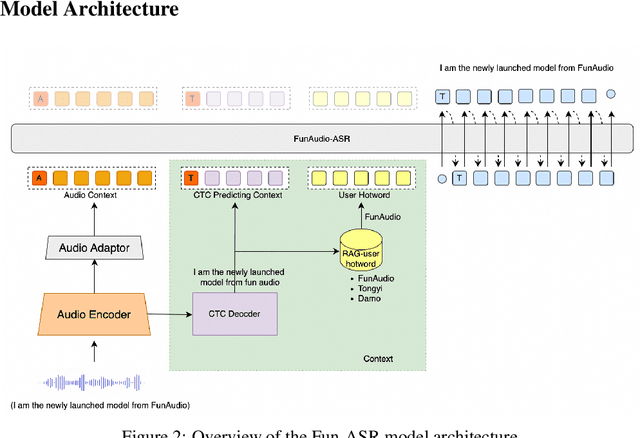
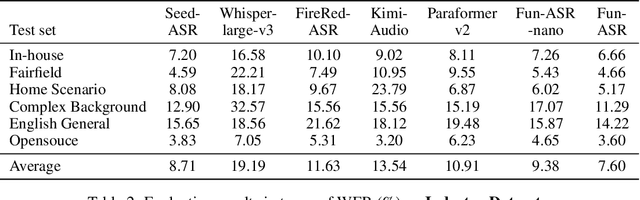
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Causal Self-supervised Pretrained Frontend with Predictive Code for Speech Separation
Apr 03, 2025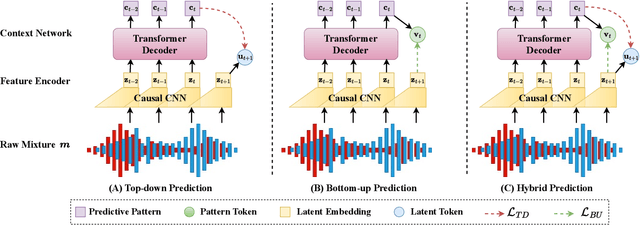
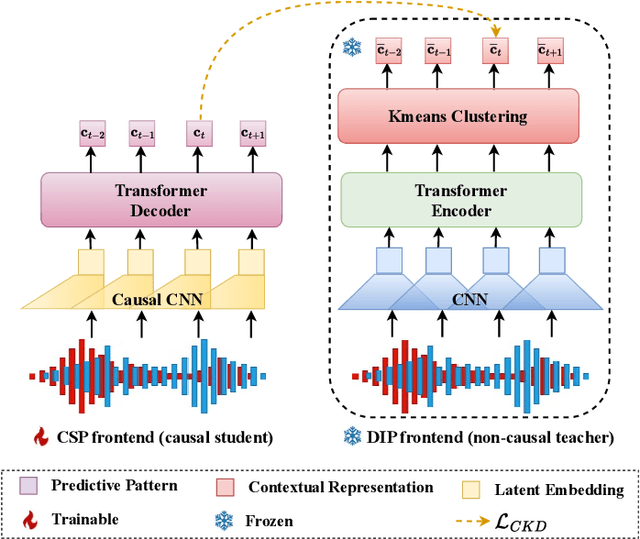
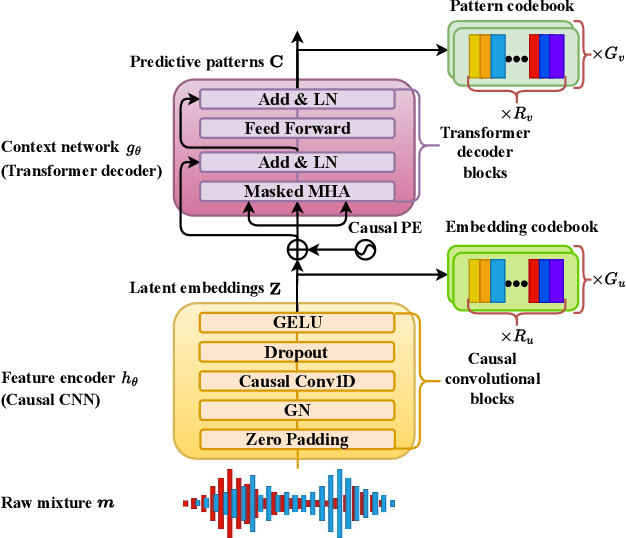
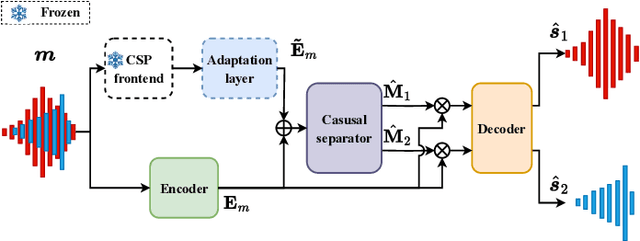
Speech separation (SS) seeks to disentangle a multi-talker speech mixture into single-talker speech streams. Although SS can be generally achieved using offline methods, such a processing paradigm is not suitable for real-time streaming applications. Causal separation models, which rely only on past and present information, offer a promising solution for real-time streaming. However, these models typically suffer from notable performance degradation due to the absence of future context. In this paper, we introduce a novel frontend that is designed to mitigate the mismatch between training and run-time inference by implicitly incorporating future information into causal models through predictive patterns. The pretrained frontend employs a transformer decoder network with a causal convolutional encoder as the backbone and is pretrained in a self-supervised manner with two innovative pretext tasks: autoregressive hybrid prediction and contextual knowledge distillation. These tasks enable the model to capture predictive patterns directly from mixtures in a self-supervised manner. The pretrained frontend subsequently serves as a feature extractor to generate high-quality predictive patterns. Comprehensive evaluations on synthetic and real-world datasets validated the effectiveness of the proposed pretrained frontend.
Context-Aware Two-Step Training Scheme for Domain Invariant Speech Separation
Mar 16, 2025
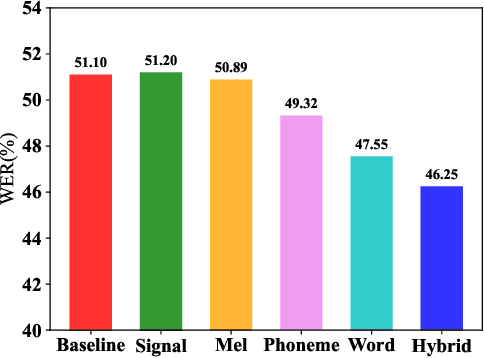


Speech separation seeks to isolate individual speech signals from a multi-talk speech mixture. Despite much progress, a system well-trained on synthetic data often experiences performance degradation on out-of-domain data, such as real-world speech mixtures. To address this, we introduce a novel context-aware, two-stage training scheme for speech separation models. In this training scheme, the conventional end-to-end architecture is replaced with a framework that contains a context extractor and a segregator. The two modules are trained step by step to simulate the speech separation process of an auditory system. We evaluate the proposed training scheme through cross-domain experiments on both synthetic and real-world speech mixtures, and demonstrate that our new scheme effectively boosts separation quality across different domains without adaptation, as measured by signal quality metrics and word error rate (WER). Additionally, an ablation study on the real test set highlights that the context information, including phoneme and word representations from pretrained SSL models, serves as effective domain invariant training targets for separation models.
Speech Separation with Pretrained Frontend to Minimize Domain Mismatch
Nov 05, 2024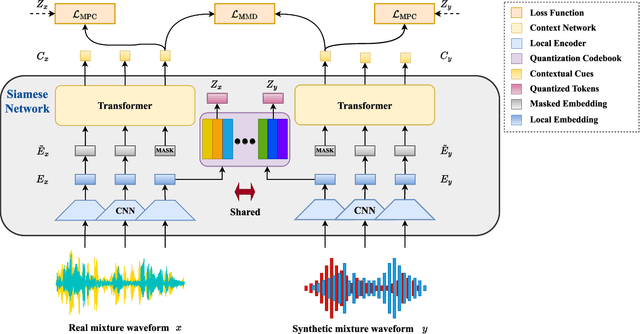
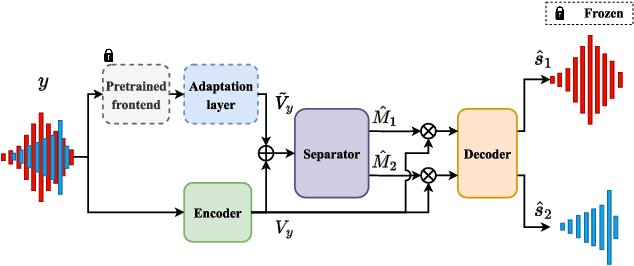
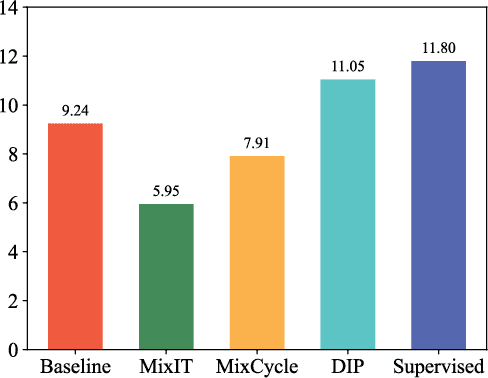
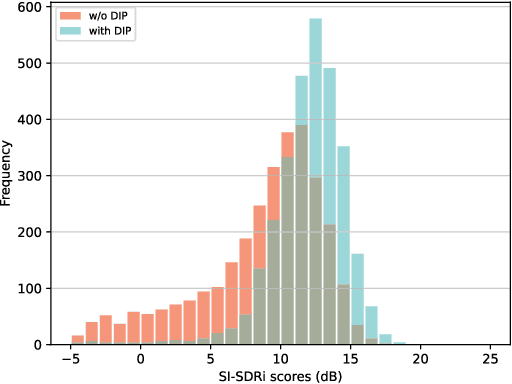
Speech separation seeks to separate individual speech signals from a speech mixture. Typically, most separation models are trained on synthetic data due to the unavailability of target reference in real-world cocktail party scenarios. As a result, there exists a domain gap between real and synthetic data when deploying speech separation models in real-world applications. In this paper, we propose a self-supervised domain-invariant pretrained (DIP) frontend that is exposed to mixture data without the need for target reference speech. The DIP frontend utilizes a Siamese network with two innovative pretext tasks, mixture predictive coding (MPC) and mixture invariant coding (MIC), to capture shared contextual cues between real and synthetic unlabeled mixtures. Subsequently, we freeze the DIP frontend as a feature extractor when training the downstream speech separation models on synthetic data. By pretraining the DIP frontend with the contextual cues, we expect that the speech separation skills learned from synthetic data can be effectively transferred to real data. To benefit from the DIP frontend, we introduce a novel separation pipeline to align the feature resolution of the separation models. We evaluate the speech separation quality on standard benchmarks and real-world datasets. The results confirm the superiority of our DIP frontend over existing speech separation models. This study underscores the potential of large-scale pretraining to enhance the quality and intelligibility of speech separation in real-world applications.
* IEEE/ACM Transactions on Audio, Speech, and Language Processing
Selective HuBERT: Self-Supervised Pre-Training for Target Speaker in Clean and Mixture Speech
Nov 08, 2023Self-supervised pre-trained speech models were shown effective for various downstream speech processing tasks. Since they are mainly pre-trained to map input speech to pseudo-labels, the resulting representations are only effective for the type of pre-train data used, either clean or mixture speech. With the idea of selective auditory attention, we propose a novel pre-training solution called Selective-HuBERT, or SHuBERT, which learns the selective extraction of target speech representations from either clean or mixture speech. Specifically, SHuBERT is trained to predict pseudo labels of a target speaker, conditioned on an enrolled speech from the target speaker. By doing so, SHuBERT is expected to selectively attend to the target speaker in a complex acoustic environment, thus benefiting various downstream tasks. We further introduce a dual-path training strategy and use the cross-correlation constraint between the two branches to encourage the model to generate noise-invariant representation. Experiments on SUPERB benchmark and LibriMix dataset demonstrate the universality and noise-robustness of SHuBERT. Furthermore, we find that our high-quality representation can be easily integrated with conventional supervised learning methods to achieve significant performance, even under extremely low-resource labeled data.
ImagineNET: Target Speaker Extraction with Intermittent Visual Cue through Embedding Inpainting
Oct 31, 2022The speaker extraction technique seeks to single out the voice of a target speaker from the interfering voices in a speech mixture. Typically an auxiliary reference of the target speaker is used to form voluntary attention. Either a pre-recorded utterance or a synchronized lip movement in a video clip can serve as the auxiliary reference. The use of visual cue is not only feasible, but also effective due to its noise robustness, and becoming popular. However, it is difficult to guarantee that such parallel visual cue is always available in real-world applications where visual occlusion or intermittent communication can occur. In this paper, we study the audio-visual speaker extraction algorithms with intermittent visual cue. We propose a joint speaker extraction and visual embedding inpainting framework to explore the mutual benefits. To encourage the interaction between the two tasks, they are performed alternately with an interlacing structure and optimized jointly. We also propose two types of visual inpainting losses and study our proposed method with two types of popularly used visual embeddings. The experimental results show that we outperform the baseline in terms of signal quality, perceptual quality, and intelligibility.