 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Separation with Pretrained Frontend to Minimize Domain Mismatch
Paper and Code
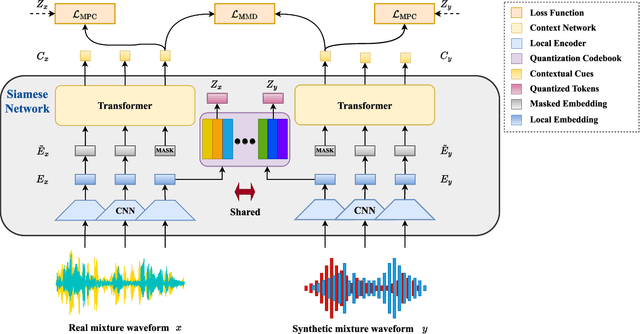
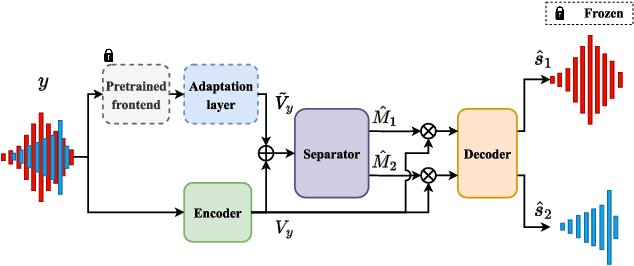
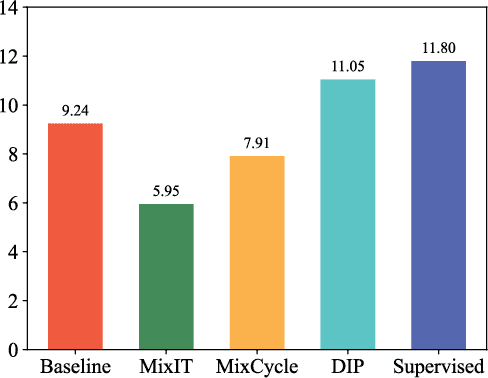
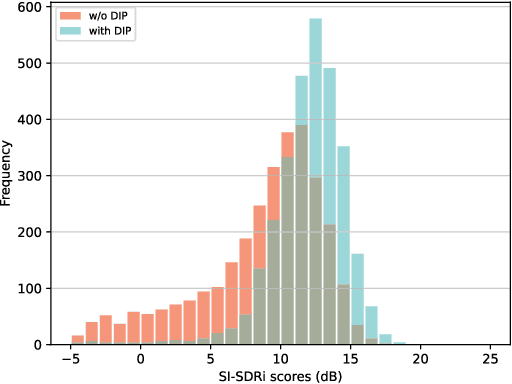
Speech separation seeks to separate individual speech signals from a speech mixture. Typically, most separation models are trained on synthetic data due to the unavailability of target reference in real-world cocktail party scenarios. As a result, there exists a domain gap between real and synthetic data when deploying speech separation models in real-world applications. In this paper, we propose a self-supervised domain-invariant pretrained (DIP) frontend that is exposed to mixture data without the need for target reference speech. The DIP frontend utilizes a Siamese network with two innovative pretext tasks, mixture predictive coding (MPC) and mixture invariant coding (MIC), to capture shared contextual cues between real and synthetic unlabeled mixtures. Subsequently, we freeze the DIP frontend as a feature extractor when training the downstream speech separation models on synthetic data. By pretraining the DIP frontend with the contextual cues, we expect that the speech separation skills learned from synthetic data can be effectively transferred to real data. To benefit from the DIP frontend, we introduce a novel separation pipeline to align the feature resolution of the separation models. We evaluate the speech separation quality on standard benchmarks and real-world datasets. The results confirm the superiority of our DIP frontend over existing speech separation models. This study underscores the potential of large-scale pretraining to enhance the quality and intelligibility of speech separation in real-world applications.