 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting OpenAI's Whisper for Speech Recognition on Code-Switch Mandarin-English SEAME and ASRU2019 Datasets
Paper and Code
Nov 29, 2023

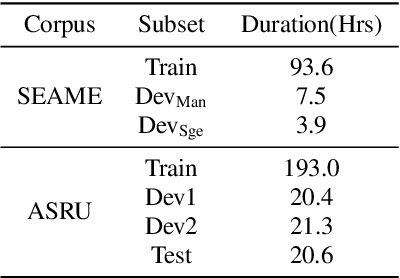

This paper details the experimental results of adapting the OpenAI's Whisper model for Code-Switch Mandarin-English Speech Recognition (ASR) on the SEAME and ASRU2019 corpora. We conducted 2 experiments: a) using adaptation data from 1 to 100/200 hours to demonstrate effectiveness of adaptation, b) examining different language ID setup on Whisper prompt. The Mixed Error Rate results show that the amount of adaptation data may be as low as $1\sim10$ hours to achieve saturation in performance gain (SEAME) while the ASRU task continued to show performance with more adaptation data ($>$100 hours). For the language prompt, the results show that although various prompting strategies initially produce different outcomes, adapting the Whisper model with code-switch data uniformly improves its performance. These results may be relevant also to the community when applying Whisper for related tasks of adapting to new target domains.