 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Prompt Tuning:Unveiling Unseen Classes for Zero-Shot Semantic Segmentation
Paper and Code
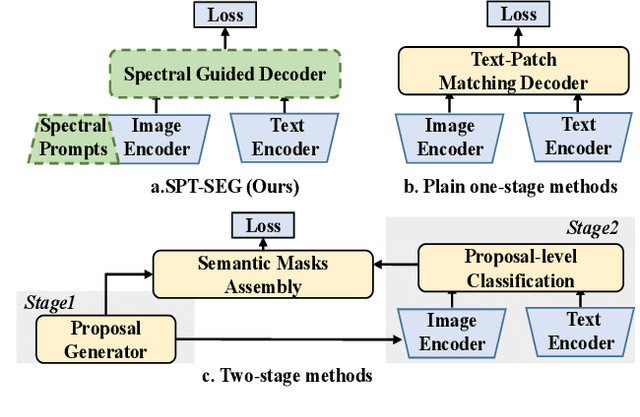
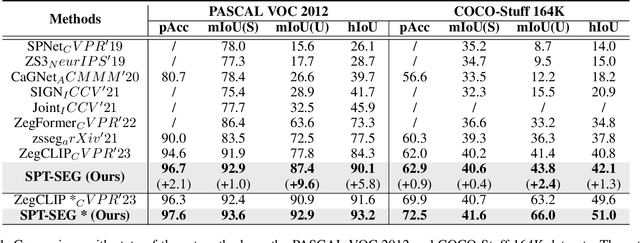
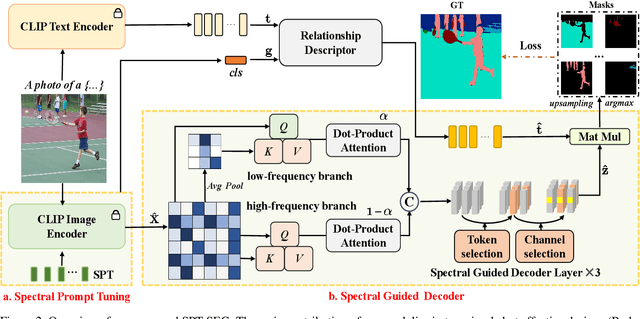
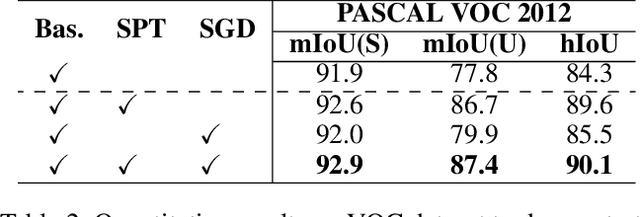
Recently, CLIP has found practical utility in the domain of pixel-level zero-shot segmentation tasks. The present landscape features two-stage methodologies beset by issues such as intricate pipelines and elevated computational costs. While current one-stage approaches alleviate these concerns and incorporate Visual Prompt Training (VPT) to uphold CLIP's generalization capacity, they still fall short in fully harnessing CLIP's potential for pixel-level unseen class demarcation and precise pixel predictions. To further stimulate CLIP's zero-shot dense prediction capability, we propose SPT-SEG, a one-stage approach that improves CLIP's adaptability from image to pixel. Specifically, we initially introduce Spectral Prompt Tuning (SPT), incorporating spectral prompts into the CLIP visual encoder's shallow layers to capture structural intricacies of images, thereby enhancing comprehension of unseen classes. Subsequently, we introduce the Spectral Guided Decoder (SGD), utilizing both high and low-frequency information to steer the network's spatial focus towards more prominent classification features, enabling precise pixel-level prediction outcomes. Through extensive experiments on two public datasets, we demonstrate the superiority of our method over state-of-the-art approaches, performing well across all classes and particularly excelling in handling unseen classes. Code is available at:https://github.com/clearxu/SPT.