 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Binary and Ternary Quantization Can Improve Feature Discrimination
Apr 18, 2025



In machine learning, quantization is widely used to simplify data representation and facilitate algorithm deployment on hardware. Given the fundamental role of classification in machine learning, it is crucial to investigate the impact of quantization on classification. Current research primarily focuses on quantization errors, operating under the premise that higher quantization errors generally result in lower classification performance. However, this premise lacks a solid theoretical foundation and often contradicts empirical findings. For instance, certain extremely low bit-width quantization methods, such as $\{0,1\}$-binary quantization and $\{0, \pm1\}$-ternary quantization, can achieve comparable or even superior classification accuracy compared to the original non-quantized data, despite exhibiting high quantization errors. To more accurately evaluate classification performance, we propose to directly investigate the feature discrimination of quantized data, instead of analyzing its quantization error. Interestingly, it is found that both binary and ternary quantization methods can improve, rather than degrade, the feature discrimination of the original data. This remarkable performance is validated through classification experiments across various data types, including images, speech, and texts.
Ternary and Binary Quantization for Improved Classification
Mar 31, 2022


Dimension reduction and data quantization are two important methods for reducing data complexity. In the paper, we study the methodology of first reducing data dimension by random projection and then quantizing the projections to ternary or binary codes, which has been widely applied in classification. Usually, the quantization will seriously degrade the accuracy of classification due to high quantization errors. Interestingly, however, we observe that the quantization could provide comparable and often superior accuracy, as the data to be quantized are sparse features generated with common filters. Furthermore, this quantization property could be maintained in the random projections of sparse features, if both the features and random projection matrices are sufficiently sparse. By conducting extensive experiments, we validate and analyze this intriguing property.
Cascaded Compressed Sensing Networks: A Reversible Architecture for Layerwise Learning
Oct 20, 2021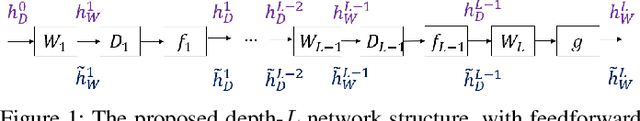
Recently, the method that learns networks layer by layer has attracted increasing interest for its ease of analysis. For the method, the main challenge lies in deriving an optimization target for each layer by inversely propagating the global target of the network. The propagation problem is ill posed, due to involving the inversion of nonlinear activations from lowdimensional to high-dimensional spaces. To address the problem, the existing solution is to learn an auxiliary network to specially propagate the target. However, the network lacks stability, and moreover, it results in higher complexity for network learning. In the letter, we show that target propagation could be achieved by modeling the network s each layer with compressed sensing, without the need of auxiliary networks. Experiments show that the proposed method could achieve better performance than the auxiliary network-based method.
Deep Learning to Ternary Hash Codes by Continuation
Jul 16, 2021
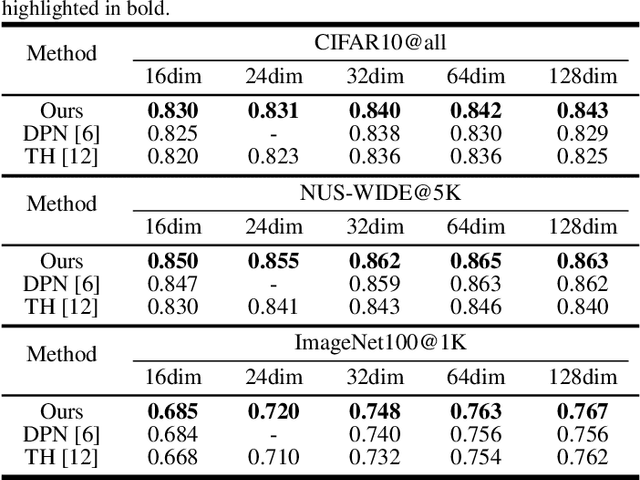
Recently, it has been observed that {0,1,-1}-ternary codes which are simply generated from deep features by hard thresholding, tend to outperform {-1,1}-binary codes in image retrieval. To obtain better ternary codes, we for the first time propose to jointly learn the features with the codes by appending a smoothed function to the networks. During training, the function could evolve into a non-smoothed ternary function by a continuation method. The method circumvents the difficulty of directly training discrete functions and reduces the quantization errors of ternary codes. Experiments show that the generated codes indeed could achieve higher retrieval accuracy.
Learning Actions from Human Demonstration Video for Robotic Manipulation
Sep 10, 2019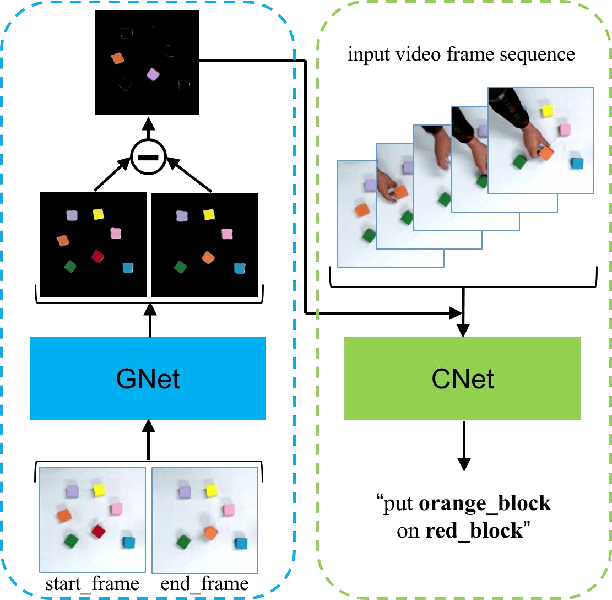
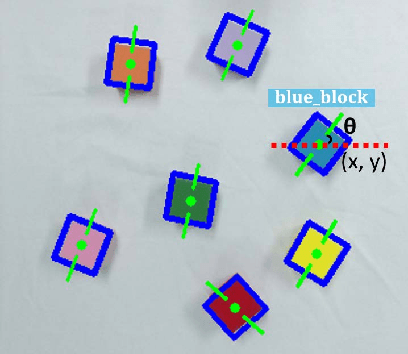
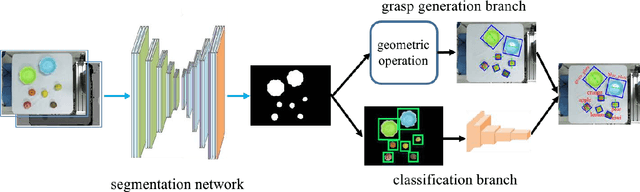
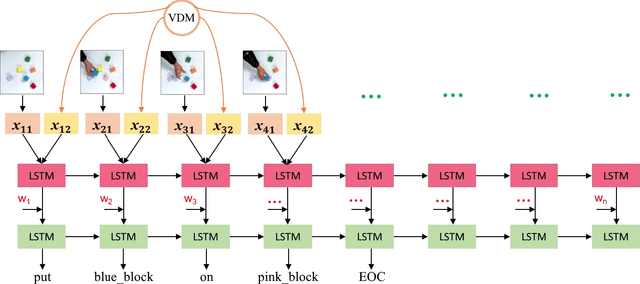
Learning actions from human demonstration is an emerging trend for designing intelligent robotic systems, which can be referred as video to command. The performance of such approach highly relies on the quality of video captioning. However, the general video captioning methods focus more on the understanding of the full frame, lacking of consideration on the specific object of interests in robotic manipulations. We propose a novel deep model to learn actions from human demonstration video for robotic manipulation. It consists of two deep networks, grasp detection network (GNet) and video captioning network (CNet). GNet performs two functions: providing grasp solutions and extracting the local features for the object of interests in robotic manipulation. CNet outputs the captioning results by fusing the features of both full frames and local objects. Experimental results on UR5 robotic arm show that our method could produce more accurate command from video demonstration than state-of-the-art work, thereby leading to more robust grasping performance.
Sparse Matrix-based Random Projection for Classification
Oct 12, 2014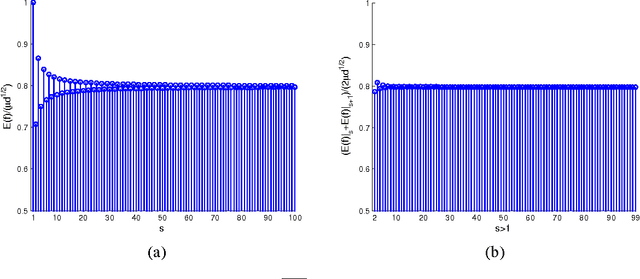
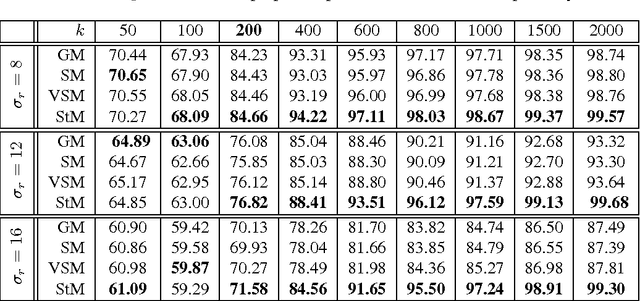


As a typical dimensionality reduction technique, random projection can be simply implemented with linear projection, while maintaining the pairwise distances of high-dimensional data with high probability. Considering this technique is mainly exploited for the task of classification, this paper is developed to study the construction of random matrix from the viewpoint of feature selection, rather than of traditional distance preservation. This yields a somewhat surprising theoretical result, that is, the sparse random matrix with exactly one nonzero element per column, can present better feature selection performance than other more dense matrices, if the projection dimension is sufficiently large (namely, not much smaller than the number of feature elements); otherwise, it will perform comparably to others. For random projection, this theoretical result implies considerable improvement on both complexity and performance, which is widely confirmed with the classification experiments on both synthetic data and real data.