 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlined Photoacoustic Image Processing with Foundation Models: A Training-Free Solution
Apr 11, 2024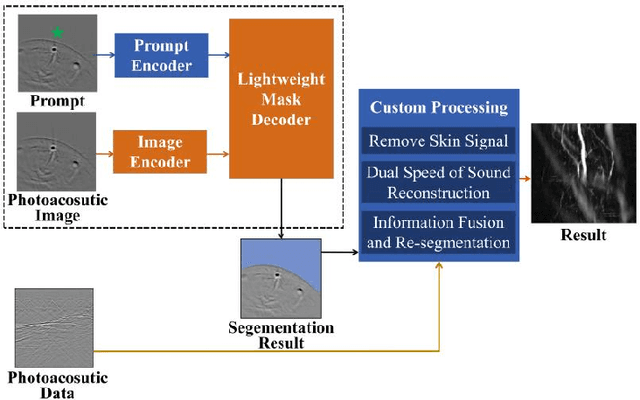


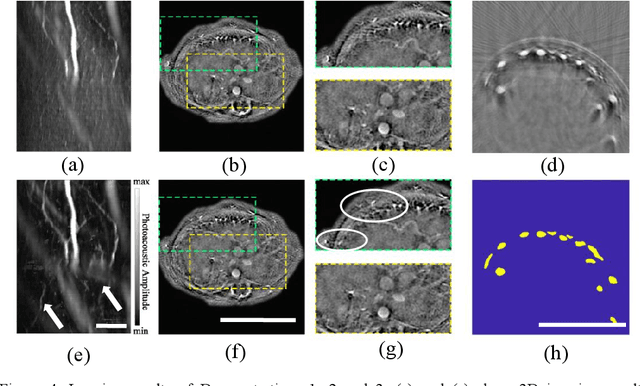
Foundation models have rapidly evolved and have achieved significant accomplishments in computer vision tasks. Specifically, the prompt mechanism conveniently allows users to integrate image prior information into the model, making it possible to apply models without any training. Therefore, we propose a method based on foundation models and zero training to solve the tasks of photoacoustic (PA) image segmentation. We employed the segment anything model (SAM) by setting simple prompts and integrating the model's outputs with prior knowledge of the imaged objects to accomplish various tasks, including: (1) removing the skin signal in three-dimensional PA image rendering; (2) dual speed-of-sound reconstruction, and (3) segmentation of finger blood vessels. Through these demonstrations, we have concluded that deep learning can be directly applied in PA imaging without the requirement for network design and training. This potentially allows for a hands-on, convenient approach to achieving efficient and accurate segmentation of PA images. This letter serves as a comprehensive tutorial, facilitating the mastery of the technique through the provision of code and sample datasets.