 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Multilingual Hallucination in Large Vision-Language Models
Paper and Code
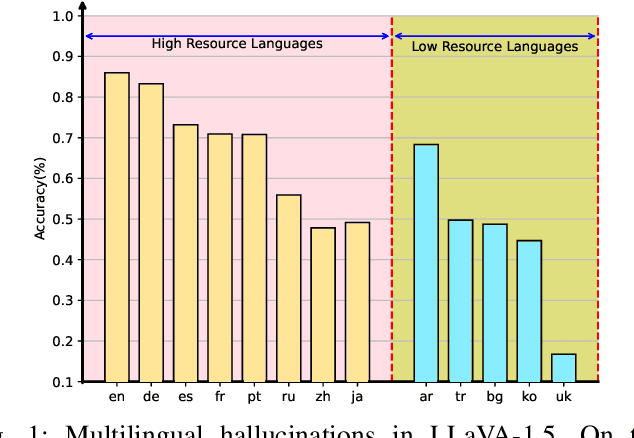
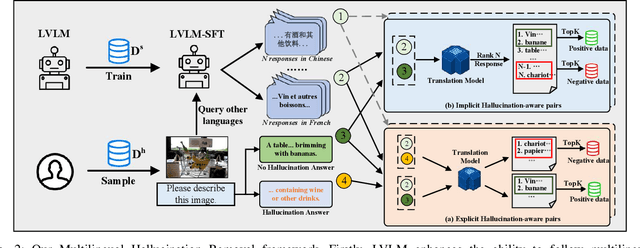

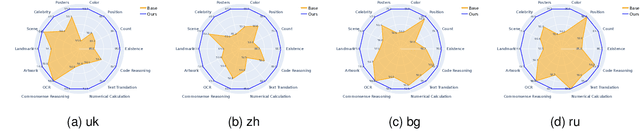
While Large Vision-Language Models (LVLMs) have exhibited remarkable capabilities across a wide range of tasks, they suffer from hallucination problems, where models generate plausible yet incorrect answers given the input image-query pair. This hallucination phenomenon is even more severe when querying the image in non-English languages, while existing methods for mitigating hallucinations in LVLMs only consider the English scenarios. In this paper, we make the first attempt to mitigate this important multilingual hallucination in LVLMs. With thorough experiment analysis, we found that multilingual hallucination in LVLMs is a systemic problem that could arise from deficiencies in multilingual capabilities or inadequate multimodal abilities. To this end, we propose a two-stage Multilingual Hallucination Removal (MHR) framework for LVLMs, aiming to improve resistance to hallucination for both high-resource and low-resource languages. Instead of relying on the intricate manual annotations of multilingual resources, we fully leverage the inherent capabilities of the LVLM and propose a novel cross-lingual alignment method, which generates multiple responses for each image-query input and then identifies the hallucination-aware pairs for each language. These data pairs are finally used for direct preference optimization to prompt the LVLMs to favor non-hallucinating responses. Experimental results show that our MHR achieves a substantial reduction in hallucination generation for LVLMs. Notably, on our extended multilingual POPE benchmark, our framework delivers an average increase of 19.0% in accuracy across 13 different languages. Our code and model weights are available at https://github.com/ssmisya/MHR