 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020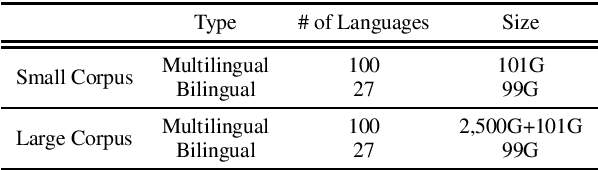
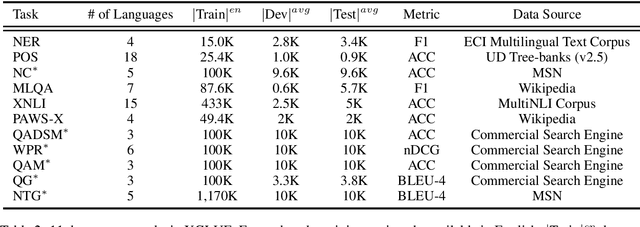
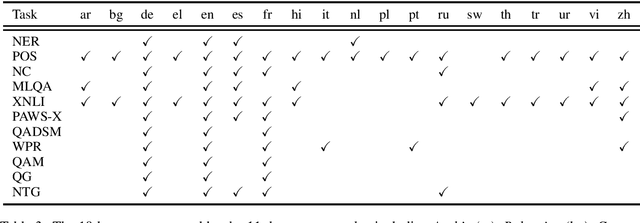
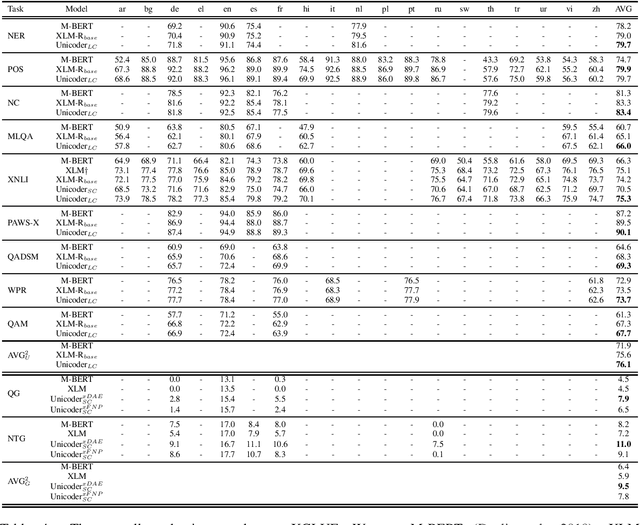
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
PasteGAN: A Semi-Parametric Method to Generate Image from Scene Graph
May 05, 2019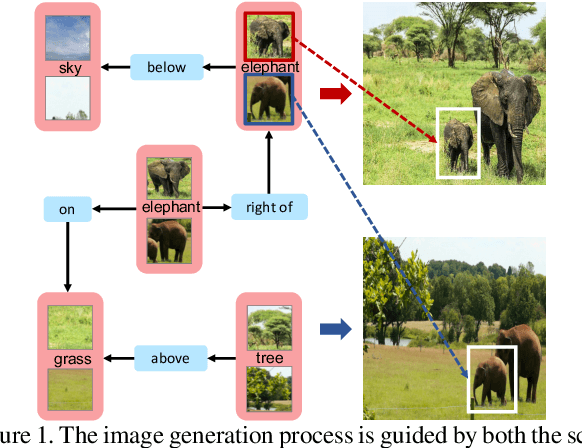
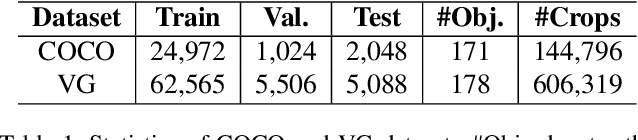
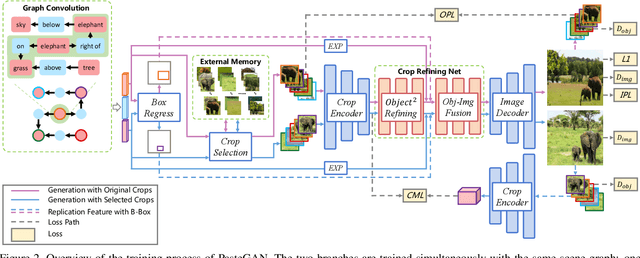
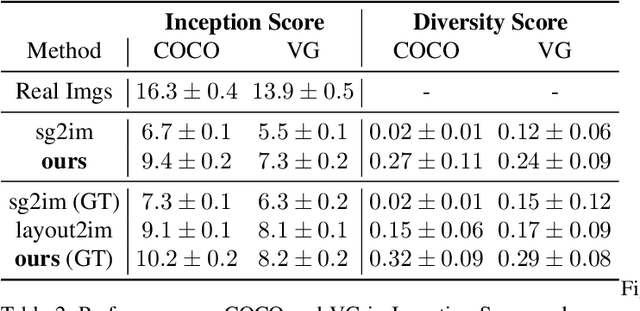
Despite some exciting progress on high-quality image generation from structured~(scene graphs) or free-form~(sentences) descriptions, most of them only guarantee the image-level semantical consistency, \ie the generated image matching the semantic meaning of the description. However, it still lacks the investigations on synthesizing the images in a more controllable way, like finely manipulating the visual appearance of every object. Therefore, to generate the images with preferred objects and rich interactions, we propose a semi-parametric method, denoted as PasteGAN, for generating the image from the scene graph, where spatial arrangements of the objects and their pair-wise relationships are defined by the scene graph and the object appearances are determined by given object crops. To enhance the interactions of the objects in the output, we design a Crop Refining Network to embed the objects as well as their relationships into one map. Multiple losses work collaboratively to guarantee the generated images highly respecting the crops and complying with the scene graphs while maintaining excellent image quality. A crop selector is also proposed to pick the most-compatible crops from our external object tank by encoding the interactions around the objects in the scene graph if the crops are not provided. Evaluated on Visual Genome and COCO-Stuff, our proposed method significantly outperforms the SOTA methods on both Inception Score and Diversity Score with a huge margin. Extensive experiments also demonstrate our method's ability to generate complex and diverse images with given objects.