 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood things come in small packages: Should we adopt Lite-GPUs in AI infrastructure?
Jan 17, 2025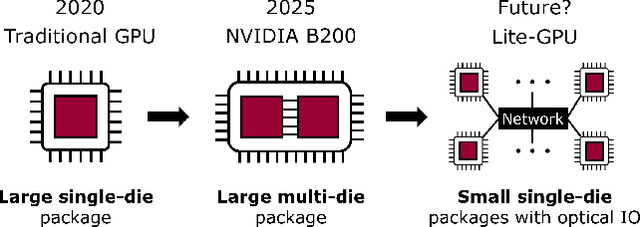
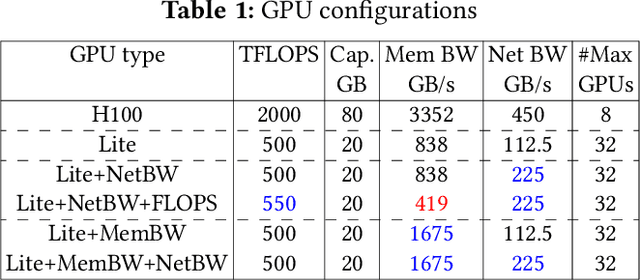
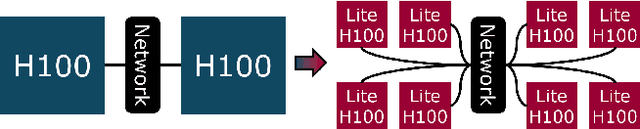
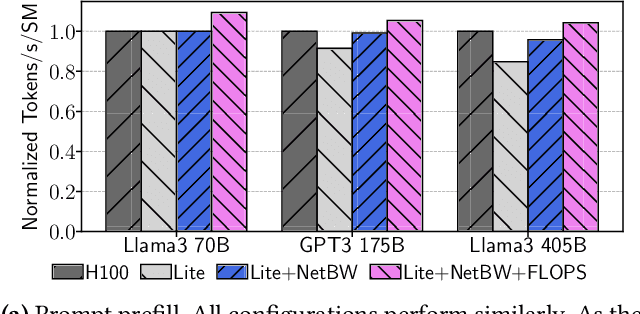
To match the blooming demand of generative AI workloads, GPU designers have so far been trying to pack more and more compute and memory into single complex and expensive packages. However, there is growing uncertainty about the scalability of individual GPUs and thus AI clusters, as state-of-the-art GPUs are already displaying packaging, yield, and cooling limitations. We propose to rethink the design and scaling of AI clusters through efficiently-connected large clusters of Lite-GPUs, GPUs with single, small dies and a fraction of the capabilities of larger GPUs. We think recent advances in co-packaged optics can be key in overcoming the communication challenges of distributing AI workloads onto more Lite-GPUs. In this paper, we present the key benefits of Lite-GPUs on manufacturing cost, blast radius, yield, and power efficiency; and discuss systems opportunities and challenges around resource, workload, memory, and network management.
Managed-Retention Memory: A New Class of Memory for the AI Era
Jan 16, 2025AI clusters today are one of the major uses of High Bandwidth Memory (HBM). However, HBM is suboptimal for AI workloads for several reasons. Analysis shows HBM is overprovisioned on write performance, but underprovisioned on density and read bandwidth, and also has significant energy per bit overheads. It is also expensive, with lower yield than DRAM due to manufacturing complexity. We propose a new memory class: Managed-Retention Memory (MRM), which is more optimized to store key data structures for AI inference workloads. We believe that MRM may finally provide a path to viability for technologies that were originally proposed to support Storage Class Memory (SCM). These technologies traditionally offered long-term persistence (10+ years) but provided poor IO performance and/or endurance. MRM makes different trade-offs, and by understanding the workload IO patterns, MRM foregoes long-term data retention and write performance for better potential performance on the metrics important for these workloads.