 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManaged-Retention Memory: A New Class of Memory for the AI Era
Jan 16, 2025AI clusters today are one of the major uses of High Bandwidth Memory (HBM). However, HBM is suboptimal for AI workloads for several reasons. Analysis shows HBM is overprovisioned on write performance, but underprovisioned on density and read bandwidth, and also has significant energy per bit overheads. It is also expensive, with lower yield than DRAM due to manufacturing complexity. We propose a new memory class: Managed-Retention Memory (MRM), which is more optimized to store key data structures for AI inference workloads. We believe that MRM may finally provide a path to viability for technologies that were originally proposed to support Storage Class Memory (SCM). These technologies traditionally offered long-term persistence (10+ years) but provided poor IO performance and/or endurance. MRM makes different trade-offs, and by understanding the workload IO patterns, MRM foregoes long-term data retention and write performance for better potential performance on the metrics important for these workloads.
CT-NOR: Representing and Reasoning About Events in Continuous Time
Jun 13, 2012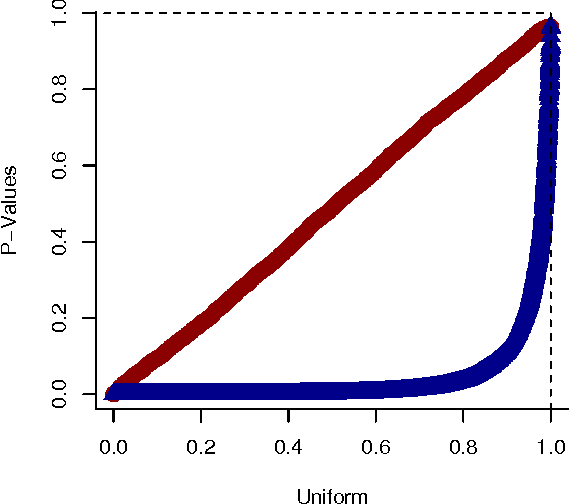
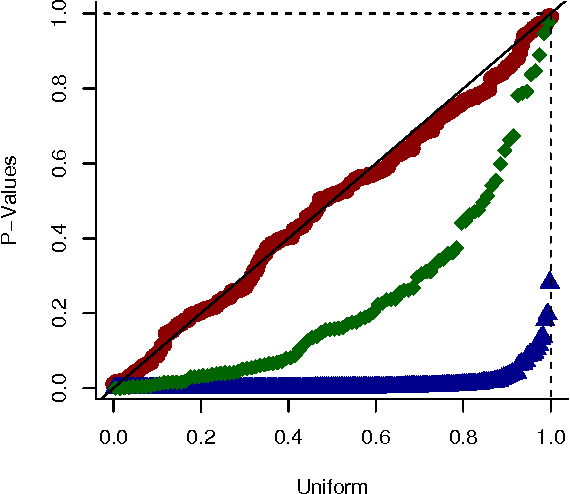
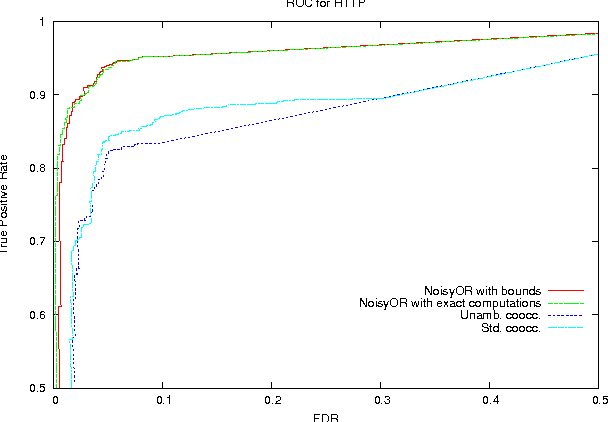
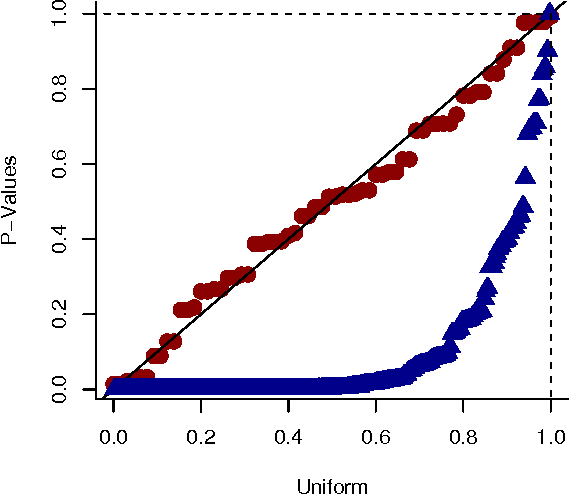
We present a generative model for representing and reasoning about the relationships among events in continuous time. We apply the model to the domain of networked and distributed computing environments where we fit the parameters of the model from timestamp observations, and then use hypothesis testing to discover dependencies between the events and changes in behavior for monitoring and diagnosis. After introducing the model, we present an EM algorithm for fitting the parameters and then present the hypothesis testing approach for both dependence discovery and change-point detection. We validate the approach for both tasks using real data from a trace of network events at Microsoft Research Cambridge. Finally, we formalize the relationship between the proposed model and the noisy-or gate for cases when time can be discretized.