 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCumulative Utility Parity for Fair Federated Learning under Intermittent Client Participation
Feb 14, 2026In real-world federated learning (FL) systems, client participation is intermittent, heterogeneous, and often correlated with data characteristics or resource constraints. Existing fairness approaches in FL primarily focus on equalizing loss or accuracy conditional on participation, implicitly assuming that clients have comparable opportunities to contribute over time. However, when participation itself is uneven, these objectives can lead to systematic under-representation of intermittently available clients, even if per-round performance appears fair. We propose cumulative utility parity, a fairness principle that evaluates whether clients receive comparable long-term benefit per participation opportunity, rather than per training round. To operationalize this notion, we introduce availability-normalized cumulative utility, which disentangles unavoidable physical constraints from avoidable algorithmic bias arising from scheduling and aggregation. Experiments on temporally skewed, non-IID federated benchmarks demonstrate that our approach substantially improves long-term representation parity, while maintaining near-perfect performance.
Locally Differentially Private Embedding Models in Distributed Fraud Prevention Systems
Jan 03, 2024



Global financial crime activity is driving demand for machine learning solutions in fraud prevention. However, prevention systems are commonly serviced to financial institutions in isolation, and few provisions exist for data sharing due to fears of unintentional leaks and adversarial attacks. Collaborative learning advances in finance are rare, and it is hard to find real-world insights derived from privacy-preserving data processing systems. In this paper, we present a collaborative deep learning framework for fraud prevention, designed from a privacy standpoint, and awarded at the recent PETs Prize Challenges. We leverage latent embedded representations of varied-length transaction sequences, along with local differential privacy, in order to construct a data release mechanism which can securely inform externally hosted fraud and anomaly detection models. We assess our contribution on two distributed data sets donated by large payment networks, and demonstrate robustness to popular inference-time attacks, along with utility-privacy trade-offs analogous to published work in alternative application domains.
Distributed data analytics
Mar 26, 2022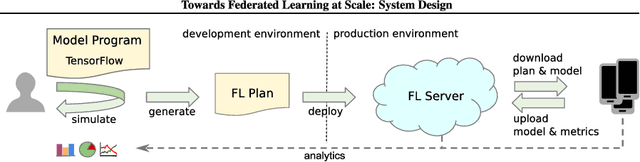

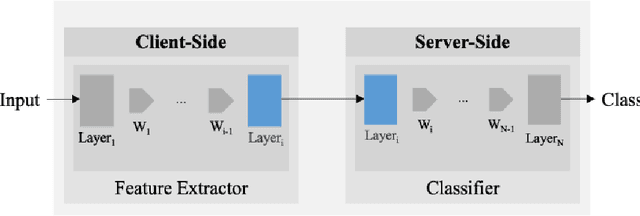
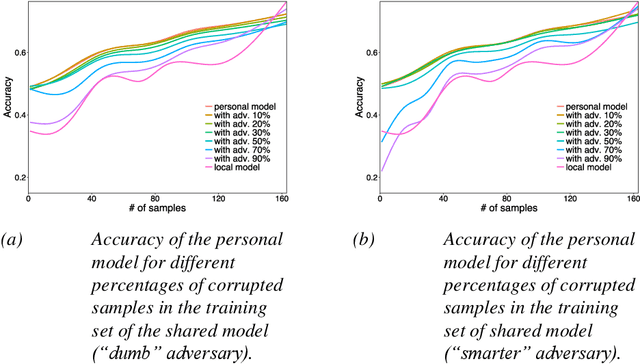
Machine Learning (ML) techniques have begun to dominate data analytics applications and services. Recommendation systems are a key component of online service providers. The financial industry has adopted ML to harness large volumes of data in areas such as fraud detection, risk-management, and compliance. Deep Learning is the technology behind voice-based personal assistants, etc. Deployment of ML technologies onto cloud computing infrastructures has benefited numerous aspects of our daily life. The advertising and associated online industries in particular have fuelled a rapid rise the in deployment of personal data collection and analytics tools. Traditionally, behavioural analytics relies on collecting vast amounts of data in centralised cloud infrastructure before using it to train machine learning models that allow user behaviour and preferences to be inferred. A contrasting approach, distributed data analytics, where code and models for training and inference are distributed to the places where data is collected, has been boosted by two recent, ongoing developments: increased processing power and memory capacity available in user devices at the edge of the network, such as smartphones and home assistants; and increased sensitivity to the highly intrusive nature of many of these devices and services and the attendant demands for improved privacy. Indeed, the potential for increased privacy is not the only benefit of distributing data analytics to the edges of the network: reducing the movement of large volumes of data can also improve energy efficiency, helping to ameliorate the ever increasing carbon footprint of our digital infrastructure, enabling much lower latency for service interactions than is possible when services are cloud-hosted. These approaches often introduce challenges in privacy, utility, and efficiency trade-offs, while having to ensure fruitful user engagement.
Revisiting IoT Device Identification
Jul 16, 2021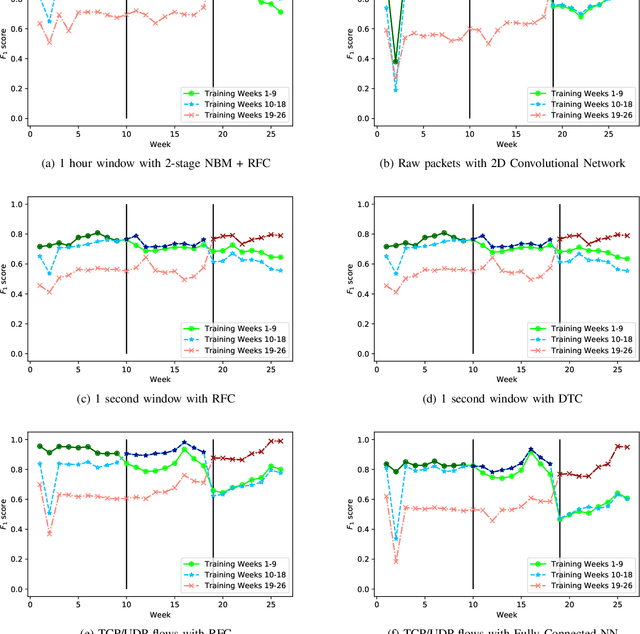

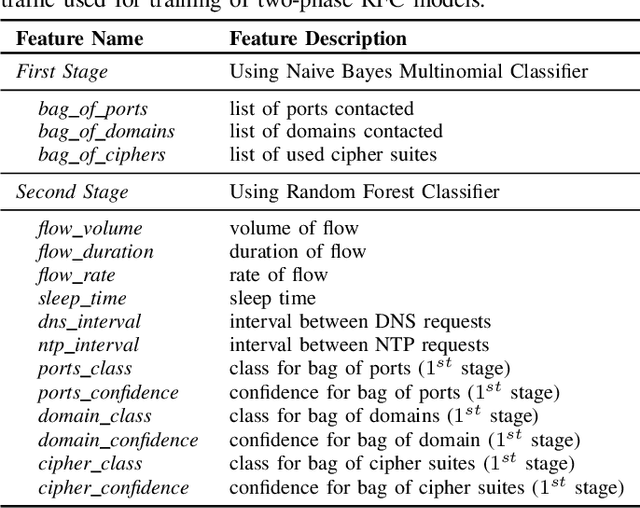

Internet-of-Things (IoT) devices are known to be the source of many security problems, and as such, they would greatly benefit from automated management. This requires robustly identifying devices so that appropriate network security policies can be applied. We address this challenge by exploring how to accurately identify IoT devices based on their network behavior, while leveraging approaches previously proposed by other researchers. We compare the accuracy of four different previously proposed machine learning models (tree-based and neural network-based) for identifying IoT devices. We use packet trace data collected over a period of six months from a large IoT test-bed. We show that, while all models achieve high accuracy when evaluated on the same dataset as they were trained on, their accuracy degrades over time, when evaluated on data collected outside the training set. We show that on average the models' accuracy degrades after a couple of weeks by up to 40 percentage points (on average between 12 and 21 percentage points). We argue that, in order to keep the models' accuracy at a high level, these need to be continuously updated.
The Case for Retraining of ML Models for IoT Device Identification at the Edge
Nov 17, 2020
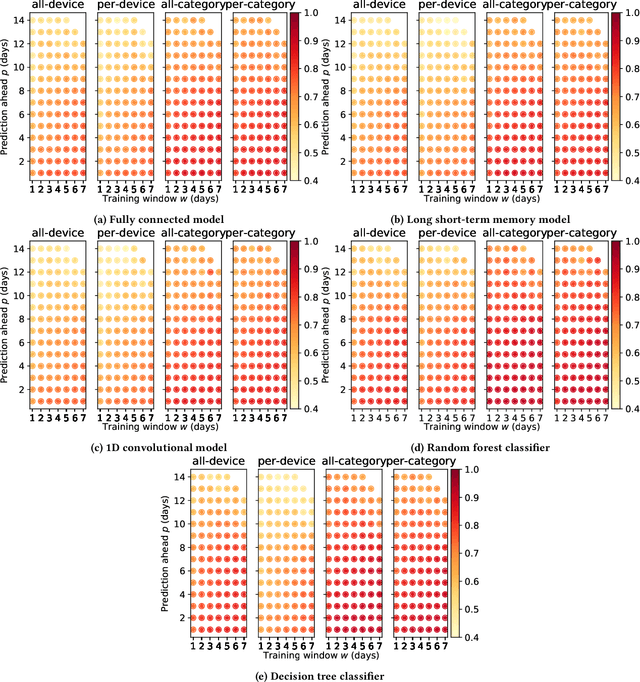
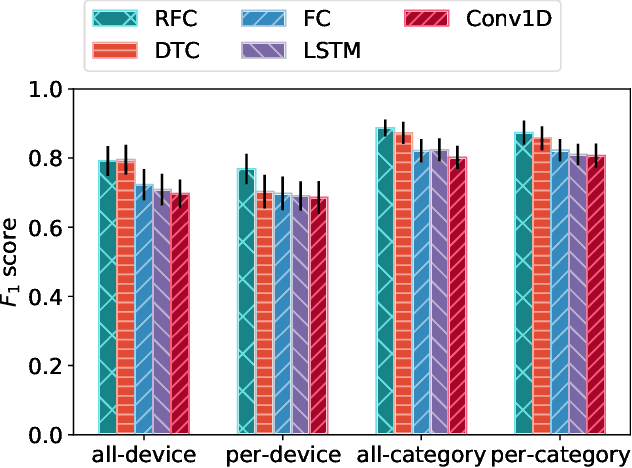
Internet-of-Things (IoT) devices are known to be the source of many security problems, and as such they would greatly benefit from automated management. This requires robustly identifying devices so that appropriate network security policies can be applied. We address this challenge by exploring how to accurately identify IoT devices based on their network behavior, using resources available at the edge of the network. In this paper, we compare the accuracy of five different machine learning models (tree-based and neural network-based) for identifying IoT devices by using packet trace data from a large IoT test-bed, showing that all models need to be updated over time to avoid significant degradation in accuracy. In order to effectively update the models, we find that it is necessary to use data gathered from the deployment environment, e.g., the household. We therefore evaluate our approach using hardware resources and data sources representative of those that would be available at the edge of the network, such as in an IoT deployment. We show that updating neural network-based models at the edge is feasible, as they require low computational and memory resources and their structure is amenable to being updated. Our results show that it is possible to achieve device identification and categorization with over 80% and 90% accuracy respectively at the edge.
Privacy-Preserving Personal Model Training
Apr 03, 2018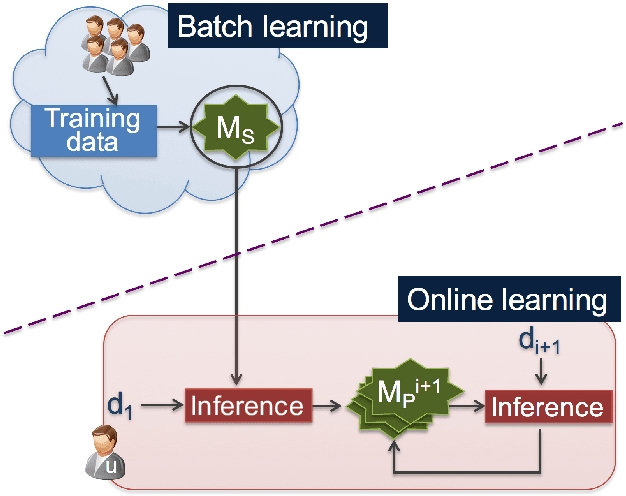
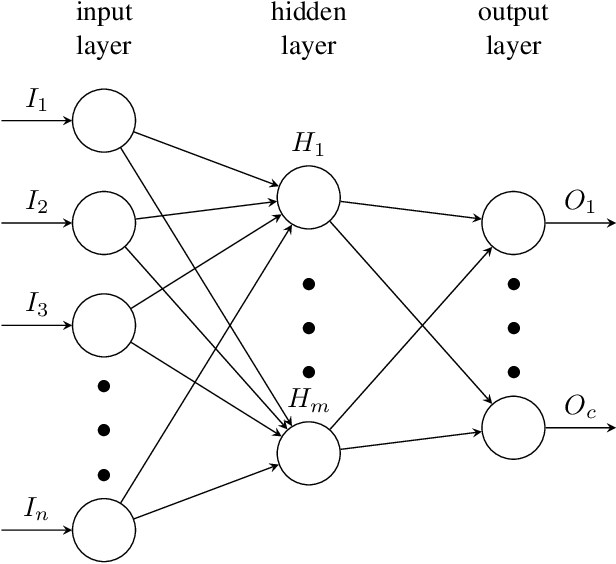
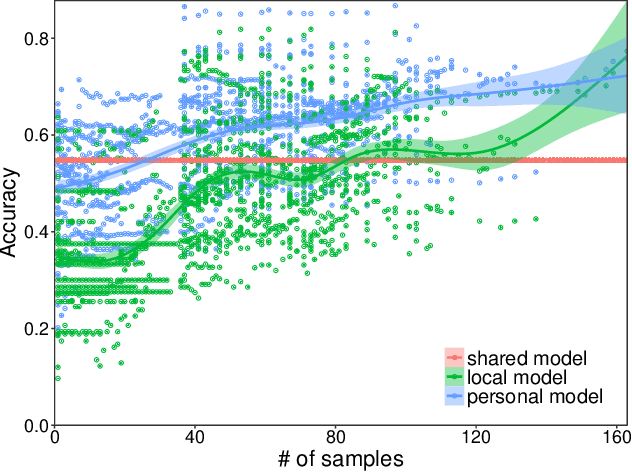
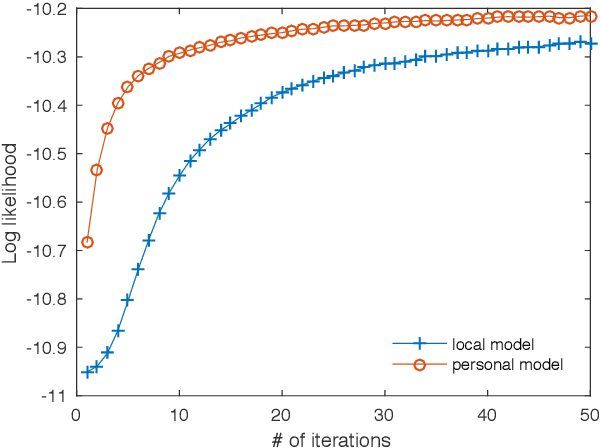
Many current Internet services rely on inferences from models trained on user data. Commonly, both the training and inference tasks are carried out using cloud resources fed by personal data collected at scale from users. Holding and using such large collections of personal data in the cloud creates privacy risks to the data subjects, but is currently required for users to benefit from such services. We explore how to provide for model training and inference in a system where computation is pushed to the data in preference to moving data to the cloud, obviating many current privacy risks. Specifically, we take an initial model learnt from a small set of users and retrain it locally using data from a single user. We evaluate on two tasks: one supervised learning task, using a neural network to recognise users' current activity from accelerometer traces; and one unsupervised learning task, identifying topics in a large set of documents. In both cases the accuracy is improved. We also analyse the robustness of our approach against adversarial attacks, as well as its feasibility by presenting a performance evaluation on a representative resource-constrained device (a Raspberry Pi).
User-centric Composable Services: A New Generation of Personal Data Analytics
Nov 26, 2017
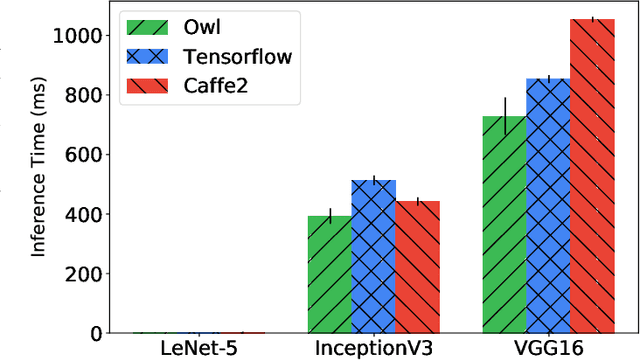
Machine Learning (ML) techniques, such as Neural Network, are widely used in today's applications. However, there is still a big gap between the current ML systems and users' requirements. ML systems focus on improving the performance of models in training, while individual users cares more about response time and expressiveness of the tool. Many existing research and product begin to move computation towards edge devices. Based on the numerical computing system Owl, we propose to build the Zoo system to support construction, compose, and deployment of ML models on edge and local devices.
Probabilistic Synchronous Parallel
Oct 05, 2017
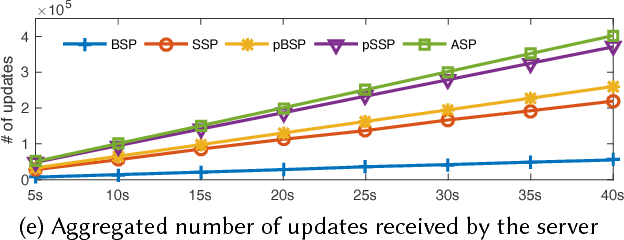
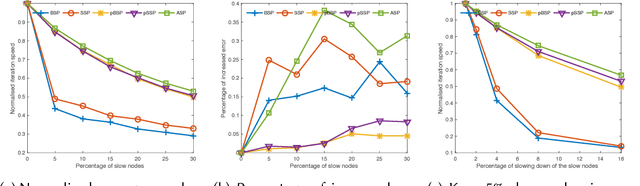
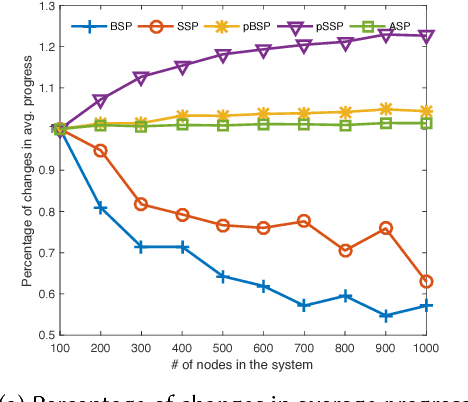
Most machine learning and deep neural network algorithms rely on certain iterative algorithms to optimise their utility/cost functions, e.g. Stochastic Gradient Descent. In distributed learning, the networked nodes have to work collaboratively to update the model parameters, and the way how they proceed is referred to as synchronous parallel design (or barrier control). Synchronous parallel protocol is the building block of any distributed learning framework, and its design has direct impact on the performance and scalability of the system. In this paper, we propose a new barrier control technique - Probabilistic Synchronous Parallel (PSP). Com- paring to the previous Bulk Synchronous Parallel (BSP), Stale Synchronous Parallel (SSP), and (Asynchronous Parallel) ASP, the proposed solution e ectively improves both the convergence speed and the scalability of the SGD algorithm by introducing a sampling primitive into the system. Moreover, we also show that the sampling primitive can be applied atop of the existing barrier control mechanisms to derive fully distributed PSP-based synchronous parallel. We not only provide a thorough theoretical analysis1 on the convergence of PSP-based SGD algorithm, but also implement a full-featured distributed learning framework called Actor and perform intensive evaluation atop of it.
CT-NOR: Representing and Reasoning About Events in Continuous Time
Jun 13, 2012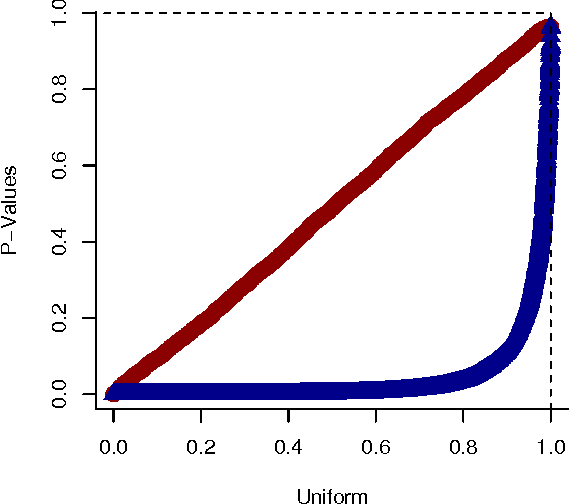
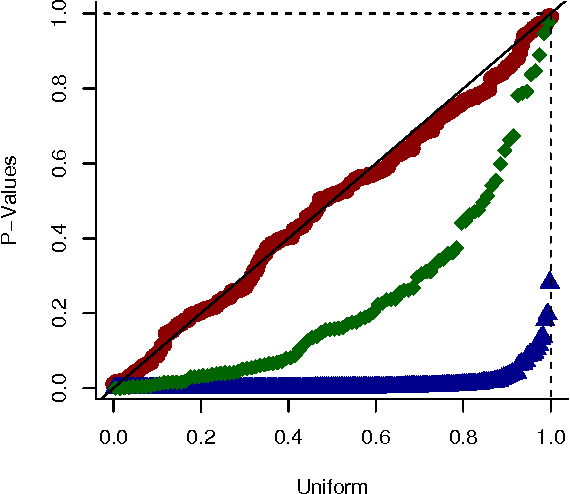
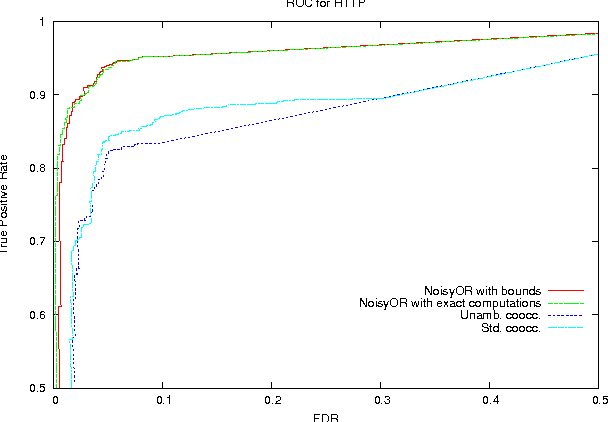
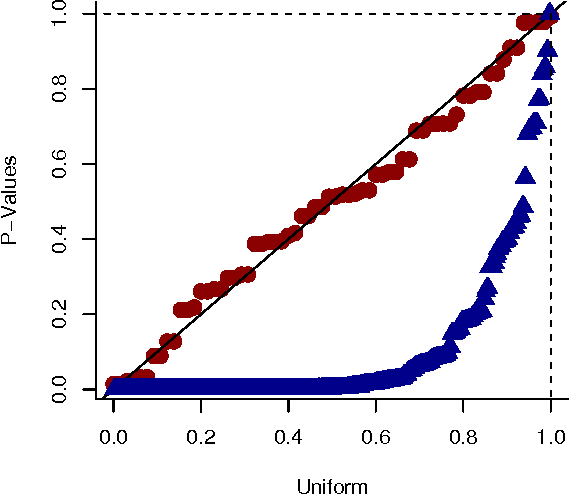
We present a generative model for representing and reasoning about the relationships among events in continuous time. We apply the model to the domain of networked and distributed computing environments where we fit the parameters of the model from timestamp observations, and then use hypothesis testing to discover dependencies between the events and changes in behavior for monitoring and diagnosis. After introducing the model, we present an EM algorithm for fitting the parameters and then present the hypothesis testing approach for both dependence discovery and change-point detection. We validate the approach for both tasks using real data from a trace of network events at Microsoft Research Cambridge. Finally, we formalize the relationship between the proposed model and the noisy-or gate for cases when time can be discretized.