 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing when we do not know: Bayesian continual learning for sensing-based analysis tasks
Jun 06, 2021


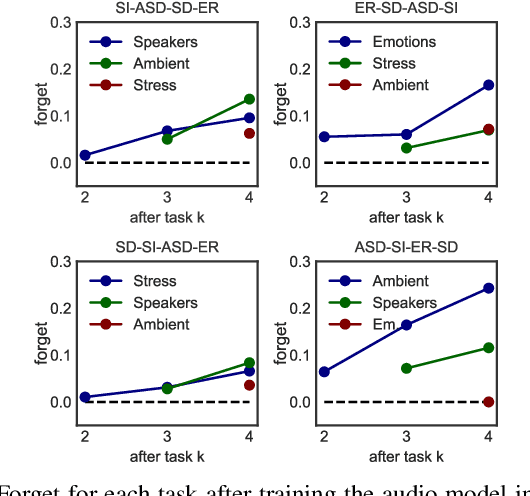
Despite much research targeted at enabling conventional machine learning models to continually learn tasks and data distributions sequentially without forgetting the knowledge acquired, little effort has been devoted to account for more realistic situations where learning some tasks accurately might be more critical than forgetting previous ones. In this paper we propose a Bayesian inference based framework to continually learn a set of real-world, sensing-based analysis tasks that can be tuned to prioritize the remembering of previously learned tasks or the learning of new ones. Our experiments prove the robustness and reliability of the learned models to adapt to the changing sensing environment, and show the suitability of using uncertainty of the predictions to assess their reliability.
Privacy-Preserving Personal Model Training
Apr 03, 2018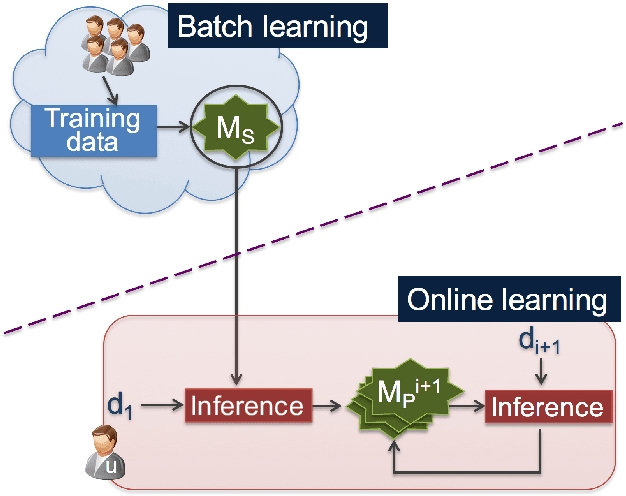
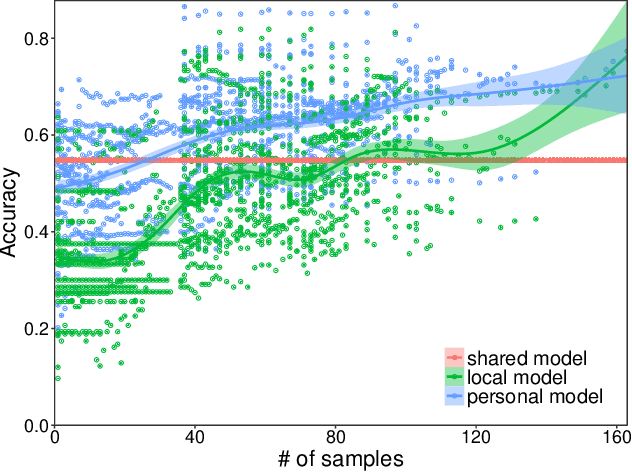
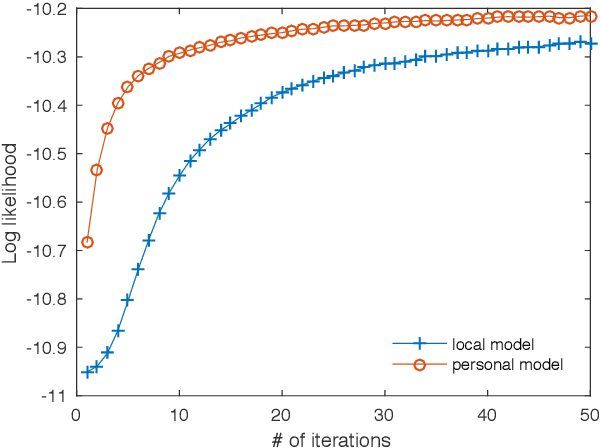
Many current Internet services rely on inferences from models trained on user data. Commonly, both the training and inference tasks are carried out using cloud resources fed by personal data collected at scale from users. Holding and using such large collections of personal data in the cloud creates privacy risks to the data subjects, but is currently required for users to benefit from such services. We explore how to provide for model training and inference in a system where computation is pushed to the data in preference to moving data to the cloud, obviating many current privacy risks. Specifically, we take an initial model learnt from a small set of users and retrain it locally using data from a single user. We evaluate on two tasks: one supervised learning task, using a neural network to recognise users' current activity from accelerometer traces; and one unsupervised learning task, identifying topics in a large set of documents. In both cases the accuracy is improved. We also analyse the robustness of our approach against adversarial attacks, as well as its feasibility by presenting a performance evaluation on a representative resource-constrained device (a Raspberry Pi).