 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Attention-Based Multi-Agent PPO for Latency Spike Resolution in 6G RAN Slicing
Feb 11, 2026Sixth-generation (6G) radio access networks (RANs) must enforce strict service-level agreements (SLAs) for heterogeneous slices, yet sudden latency spikes remain difficult to diagnose and resolve with conventional deep reinforcement learning (DRL) or explainable RL (XRL). We propose \emph{Attention-Enhanced Multi-Agent Proximal Policy Optimization (AE-MAPPO)}, which integrates six specialized attention mechanisms into multi-agent slice control and surfaces them as zero-cost, faithful explanations. The framework operates across O-RAN timescales with a three-phase strategy: predictive, reactive, and inter-slice optimization. A URLLC case study shows AE-MAPPO resolves a latency spike in $18$ms, restores latency to $0.98$ms with $99.9999\%$ reliability, and reduces troubleshooting time by $93\%$ while maintaining eMBB and mMTC continuity. These results confirm AE-MAPPO's ability to combine SLA compliance with inherent interpretability, enabling trustworthy and real-time automation for 6G RAN slicing.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
On the Effective throughput of Shadowed Beaulieu-Xie fading channel
Nov 20, 2023



Given the imperative for advanced wireless networks in the next generation and the rise of real-time applications within wireless communication, there is a notable focus on investigating data rate performance across various fading scenarios. This research delved into analyzing the effective throughput of the shadowed Beaulieu-Xie (SBX) composite fading channel using the PDF-based approach. To get the simplified relationship between the performance parameter and channel parameters, the low-SNR and the high-SNR approximation of the effective rate are also provided. The proposed formulations are evaluated for different values of system parameters to study their impact on the effective throughput. Also, the impact of the delay parameter on the EC is investigated. Monte-Carlo simulations are used to verify the facticity of the deduced equations.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021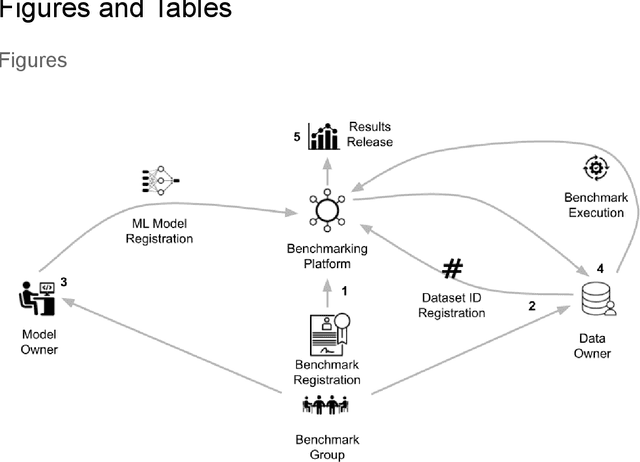
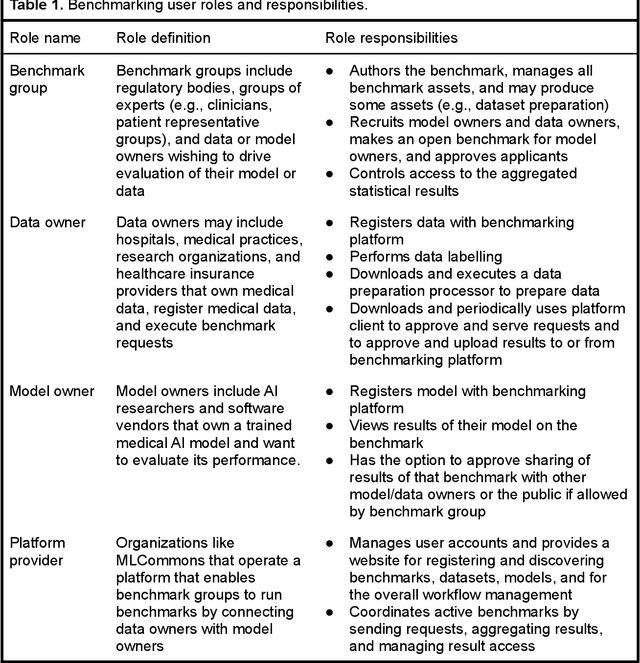
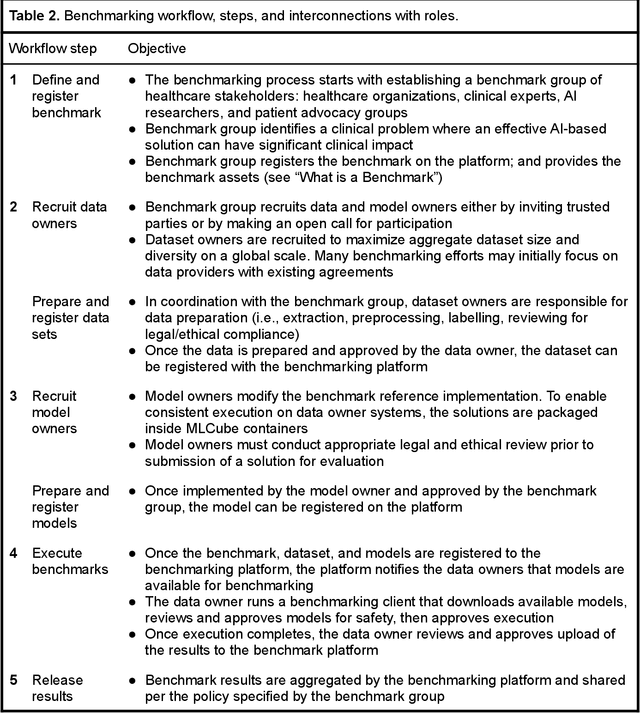
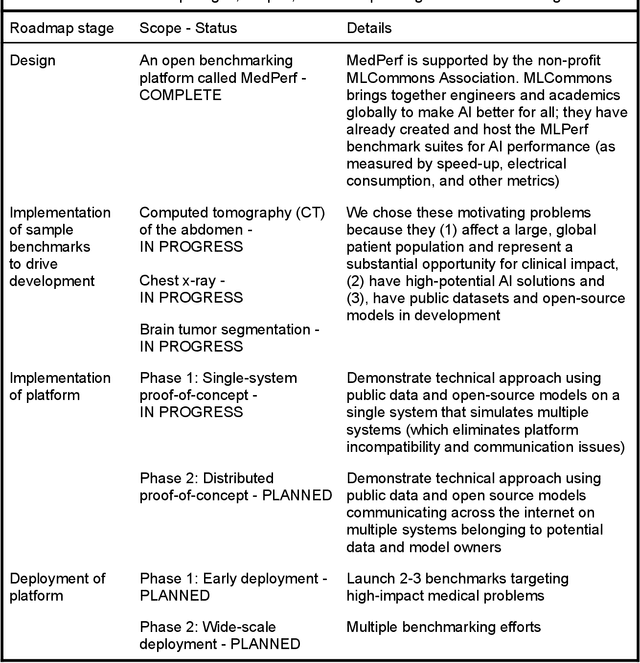
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
Revisiting IoT Device Identification
Jul 16, 2021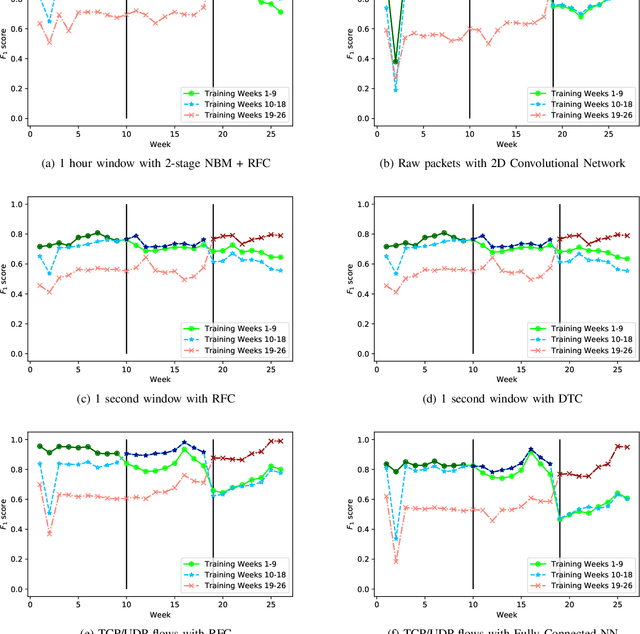


Internet-of-Things (IoT) devices are known to be the source of many security problems, and as such, they would greatly benefit from automated management. This requires robustly identifying devices so that appropriate network security policies can be applied. We address this challenge by exploring how to accurately identify IoT devices based on their network behavior, while leveraging approaches previously proposed by other researchers. We compare the accuracy of four different previously proposed machine learning models (tree-based and neural network-based) for identifying IoT devices. We use packet trace data collected over a period of six months from a large IoT test-bed. We show that, while all models achieve high accuracy when evaluated on the same dataset as they were trained on, their accuracy degrades over time, when evaluated on data collected outside the training set. We show that on average the models' accuracy degrades after a couple of weeks by up to 40 percentage points (on average between 12 and 21 percentage points). We argue that, in order to keep the models' accuracy at a high level, these need to be continuously updated.
The Case for Retraining of ML Models for IoT Device Identification at the Edge
Nov 17, 2020
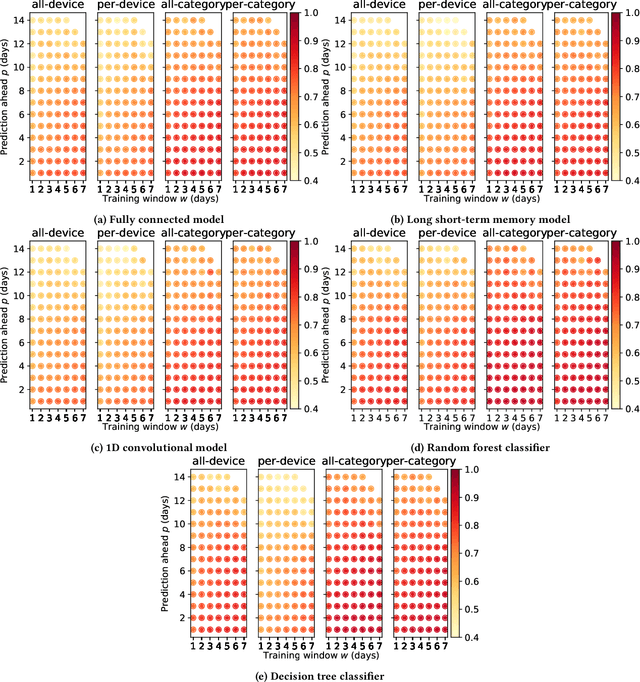
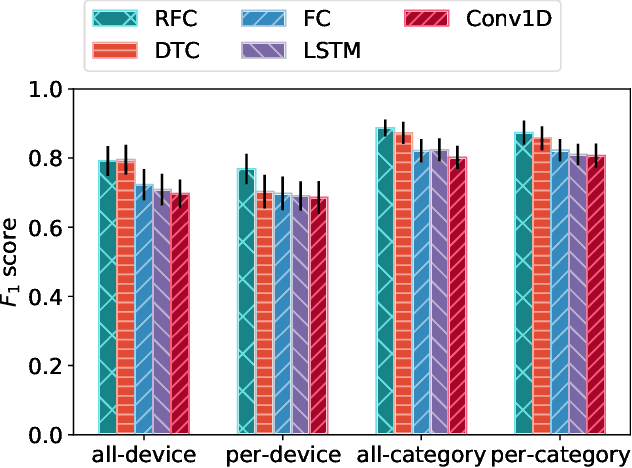
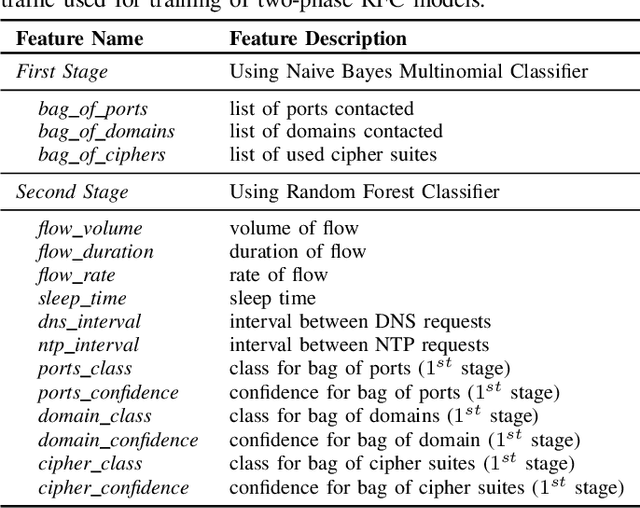
Internet-of-Things (IoT) devices are known to be the source of many security problems, and as such they would greatly benefit from automated management. This requires robustly identifying devices so that appropriate network security policies can be applied. We address this challenge by exploring how to accurately identify IoT devices based on their network behavior, using resources available at the edge of the network. In this paper, we compare the accuracy of five different machine learning models (tree-based and neural network-based) for identifying IoT devices by using packet trace data from a large IoT test-bed, showing that all models need to be updated over time to avoid significant degradation in accuracy. In order to effectively update the models, we find that it is necessary to use data gathered from the deployment environment, e.g., the household. We therefore evaluate our approach using hardware resources and data sources representative of those that would be available at the edge of the network, such as in an IoT deployment. We show that updating neural network-based models at the edge is feasible, as they require low computational and memory resources and their structure is amenable to being updated. Our results show that it is possible to achieve device identification and categorization with over 80% and 90% accuracy respectively at the edge.
Benchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020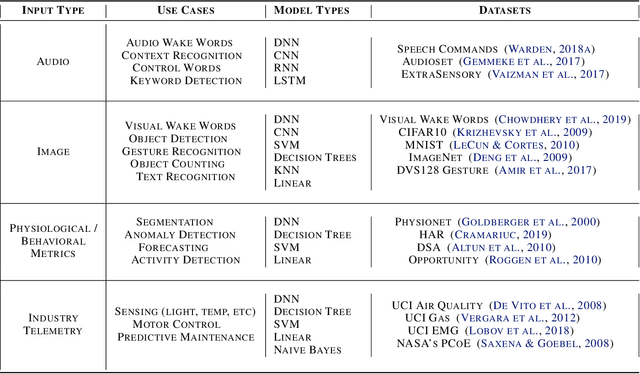
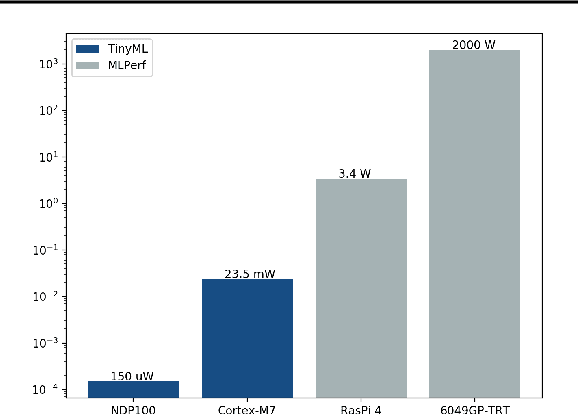
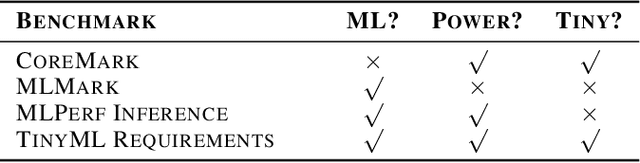
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.
Face Prediction Model for an Automatic Age-invariant Face Recognition System
Apr 16, 2015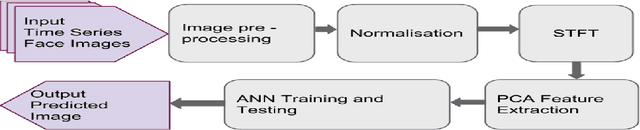

Automated face recognition and identification softwares are becoming part of our daily life; it finds its abode not only with Facebook's auto photo tagging, Apple's iPhoto, Google's Picasa, Microsoft's Kinect, but also in Homeland Security Department's dedicated biometric face detection systems. Most of these automatic face identification systems fail where the effects of aging come into the picture. Little work exists in the literature on the subject of face prediction that accounts for aging, which is a vital part of the computer face recognition systems. In recent years, individual face components' (e.g. eyes, nose, mouth) features based matching algorithms have emerged, but these approaches are still not efficient. Therefore, in this work we describe a Face Prediction Model (FPM), which predicts human face aging or growth related image variation using Principle Component Analysis (PCA) and Artificial Neural Network (ANN) learning techniques. The FPM captures the facial changes, which occur with human aging and predicts the facial image with a few years of gap with an acceptable accuracy of face matching from 76 to 86%.