 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed data analytics
Mar 26, 2022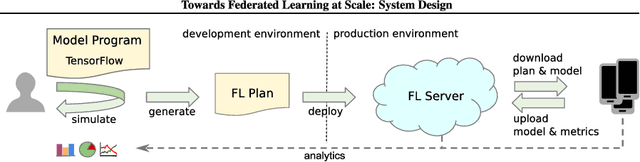

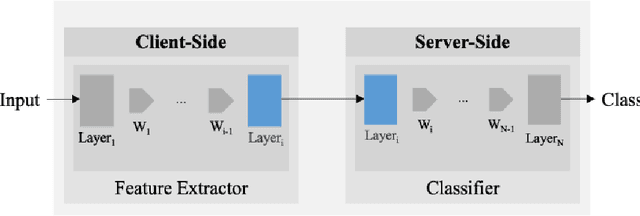
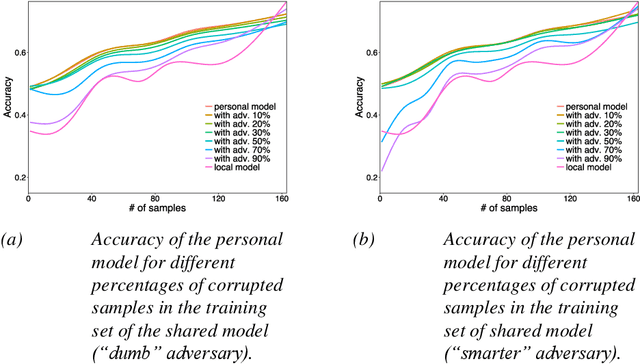
Machine Learning (ML) techniques have begun to dominate data analytics applications and services. Recommendation systems are a key component of online service providers. The financial industry has adopted ML to harness large volumes of data in areas such as fraud detection, risk-management, and compliance. Deep Learning is the technology behind voice-based personal assistants, etc. Deployment of ML technologies onto cloud computing infrastructures has benefited numerous aspects of our daily life. The advertising and associated online industries in particular have fuelled a rapid rise the in deployment of personal data collection and analytics tools. Traditionally, behavioural analytics relies on collecting vast amounts of data in centralised cloud infrastructure before using it to train machine learning models that allow user behaviour and preferences to be inferred. A contrasting approach, distributed data analytics, where code and models for training and inference are distributed to the places where data is collected, has been boosted by two recent, ongoing developments: increased processing power and memory capacity available in user devices at the edge of the network, such as smartphones and home assistants; and increased sensitivity to the highly intrusive nature of many of these devices and services and the attendant demands for improved privacy. Indeed, the potential for increased privacy is not the only benefit of distributing data analytics to the edges of the network: reducing the movement of large volumes of data can also improve energy efficiency, helping to ameliorate the ever increasing carbon footprint of our digital infrastructure, enabling much lower latency for service interactions than is possible when services are cloud-hosted. These approaches often introduce challenges in privacy, utility, and efficiency trade-offs, while having to ensure fruitful user engagement.