 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Synchronous Parallel
Paper and Code
Oct 05, 2017
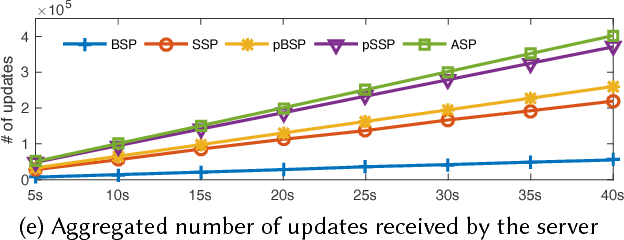
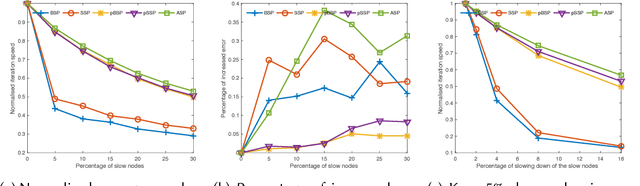
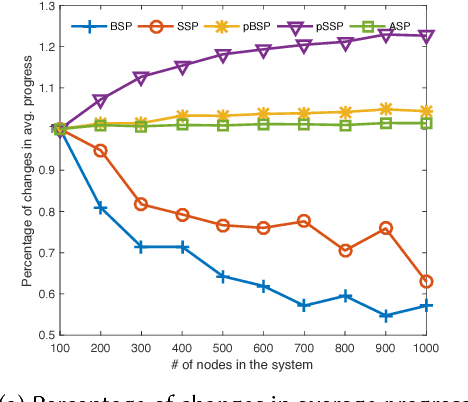
Most machine learning and deep neural network algorithms rely on certain iterative algorithms to optimise their utility/cost functions, e.g. Stochastic Gradient Descent. In distributed learning, the networked nodes have to work collaboratively to update the model parameters, and the way how they proceed is referred to as synchronous parallel design (or barrier control). Synchronous parallel protocol is the building block of any distributed learning framework, and its design has direct impact on the performance and scalability of the system. In this paper, we propose a new barrier control technique - Probabilistic Synchronous Parallel (PSP). Com- paring to the previous Bulk Synchronous Parallel (BSP), Stale Synchronous Parallel (SSP), and (Asynchronous Parallel) ASP, the proposed solution e ectively improves both the convergence speed and the scalability of the SGD algorithm by introducing a sampling primitive into the system. Moreover, we also show that the sampling primitive can be applied atop of the existing barrier control mechanisms to derive fully distributed PSP-based synchronous parallel. We not only provide a thorough theoretical analysis1 on the convergence of PSP-based SGD algorithm, but also implement a full-featured distributed learning framework called Actor and perform intensive evaluation atop of it.