 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Descriptive Study of Variable Discretization and Cost-Sensitive Logistic Regression on Imbalanced Credit Data
Paper and Code
Dec 28, 2018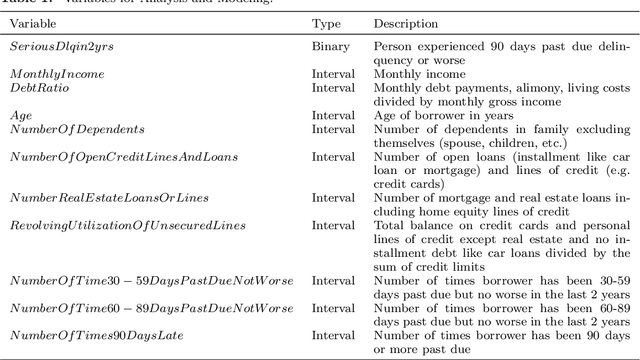



Training classification models on imbalanced data sets tends to result in bias towards the majority class. In this paper, we demonstrate how the variable discretization and Cost-Sensitive Logistic Regression help mitigate this bias on an imbalanced credit scoring data set. 10-fold cross-validation is used as the evaluation method, and the performance measurements are ROC curves and the associated Area Under the Curve. The results show that good variable discretization and Cost-Sensitive Logistic Regression with the best class weight can reduce the model bias and/or variance. It is also shown that effective variable selection helps reduce the model variance. From the algorithm perspective, Cost-Sensitive Logistic Regression is beneficial for increasing the prediction ability of predictors even if they are not in their best forms and keeping the multivariate effect and univariate effect of predictors consistent. From the predictors perspective, the variable discretization performs slightly better than Cost-Sensitive Logistic Regression, provides more reasonable coefficient estimates for predictors which have nonlinear relationship against their empirical logit, and is robust to penalty weights of misclassifications of events and non-events determined by their proportions.