 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Problems With Model Editing: How Should Rational Belief Revision Work in LLMs?
Jun 27, 2024


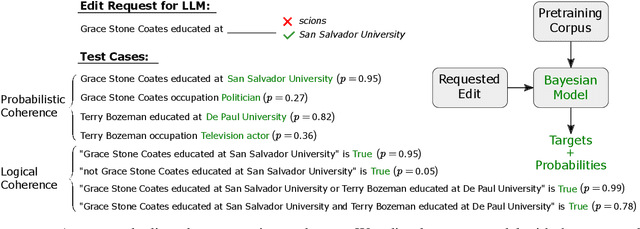
The model editing problem concerns how language models should learn new facts about the world over time. While empirical research on model editing has drawn widespread attention, the conceptual foundations of model editing remain shaky -- perhaps unsurprisingly, since model editing is essentially belief revision, a storied problem in philosophy that has eluded succinct solutions for decades. Model editing nonetheless demands a solution, since we need to be able to control the knowledge within language models. With this goal in mind, this paper critiques the standard formulation of the model editing problem and proposes a formal testbed for model editing research. We first describe 12 open problems with model editing, based on challenges with (1) defining the problem, (2) developing benchmarks, and (3) assuming LLMs have editable beliefs in the first place. Many of these challenges are extremely difficult to address, e.g. determining far-reaching consequences of edits, labeling probabilistic entailments between facts, and updating beliefs of agent simulators. Next, we introduce a semi-synthetic dataset for model editing based on Wikidata, where we can evaluate edits against labels given by an idealized Bayesian agent. This enables us to say exactly how belief revision in language models falls short of a desirable epistemic standard. We encourage further research exploring settings where such a gold standard can be compared against. Our code is publicly available at: https://github.com/peterbhase/LLM-belief-revision
Are language models rational? The case of coherence norms and belief revision
Jun 05, 2024Do norms of rationality apply to machine learning models, in particular language models? In this paper we investigate this question by focusing on a special subset of rational norms: coherence norms. We consider both logical coherence norms as well as coherence norms tied to the strength of belief. To make sense of the latter, we introduce the Minimal Assent Connection (MAC) and propose a new account of credence, which captures the strength of belief in language models. This proposal uniformly assigns strength of belief simply on the basis of model internal next token probabilities. We argue that rational norms tied to coherence do apply to some language models, but not to others. This issue is significant since rationality is closely tied to predicting and explaining behavior, and thus it is connected to considerations about AI safety and alignment, as well as understanding model behavior more generally.