 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-efficient domain adaptive pre-training for medical images
Apr 28, 2022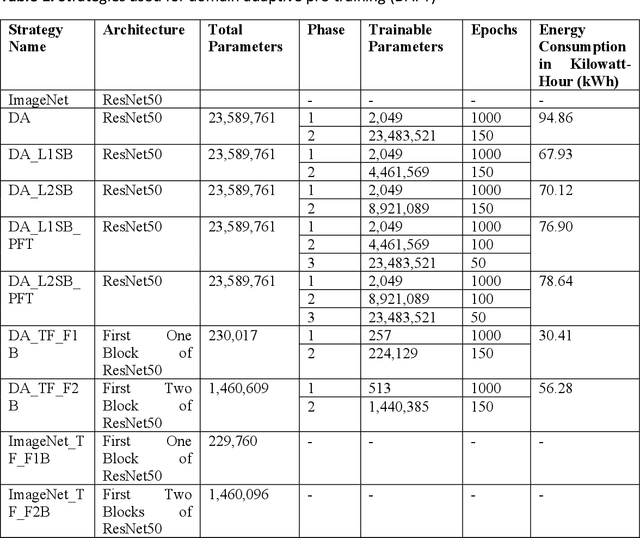

The deep learning-based analysis of medical images suffers from data scarcity because of high annotation costs and privacy concerns. Researchers in this domain have used transfer learning to avoid overfitting when using complex architectures. However, the domain differences between pre-training and downstream data hamper the performance of the downstream task. Some recent studies have successfully used domain-adaptive pre-training (DAPT) to address this issue. In DAPT, models are initialized with the generic dataset pre-trained weights, and further pre-training is performed using a moderately sized in-domain dataset (medical images). Although this technique achieved good results for the downstream tasks in terms of accuracy and robustness, it is computationally expensive even when the datasets for DAPT are moderately sized. These compute-intensive techniques and models impact the environment negatively and create an uneven playing field for researchers with limited resources. This study proposed computationally efficient DAPT without compromising the downstream accuracy and robustness. This study proposes three techniques for this purpose, where the first (partial DAPT) performs DAPT on a subset of layers. The second one adopts a hybrid strategy (hybrid DAPT) by performing partial DAPT for a few epochs and then full DAPT for the remaining epochs. The third technique performs DAPT on simplified variants of the base architecture. The results showed that compared to the standard DAPT (full DAPT), the hybrid DAPT technique achieved better performance on the development and external datasets. In contrast, simplified architectures (after DAPT) achieved the best robustness while achieving modest performance on the development dataset .