 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPPO: Multi Pair-wise Preference Optimization for LLMs with Arbitrary Negative Samples
Dec 13, 2024



Aligning Large Language Models (LLMs) with human feedback is crucial for their development. Existing preference optimization methods such as DPO and KTO, while improved based on Reinforcement Learning from Human Feedback (RLHF), are inherently derived from PPO, requiring a reference model that adds GPU memory resources and relies heavily on abundant preference data. Meanwhile, current preference optimization research mainly targets single-question scenarios with two replies, neglecting optimization with multiple replies, which leads to a waste of data in the application. This study introduces the MPPO algorithm, which leverages the average likelihood of model responses to fit the reward function and maximizes the utilization of preference data. Through a comparison of Point-wise, Pair-wise, and List-wise implementations, we found that the Pair-wise approach achieves the best performance, significantly enhancing the quality of model responses. Experimental results demonstrate MPPO's outstanding performance across various benchmarks. On MT-Bench, MPPO outperforms DPO, ORPO, and SimPO. Notably, on Arena-Hard, MPPO surpasses DPO and ORPO by substantial margins. These achievements underscore the remarkable advantages of MPPO in preference optimization tasks.
A novel Counterfactual method for aspect-based sentiment analysis
Jun 24, 2023


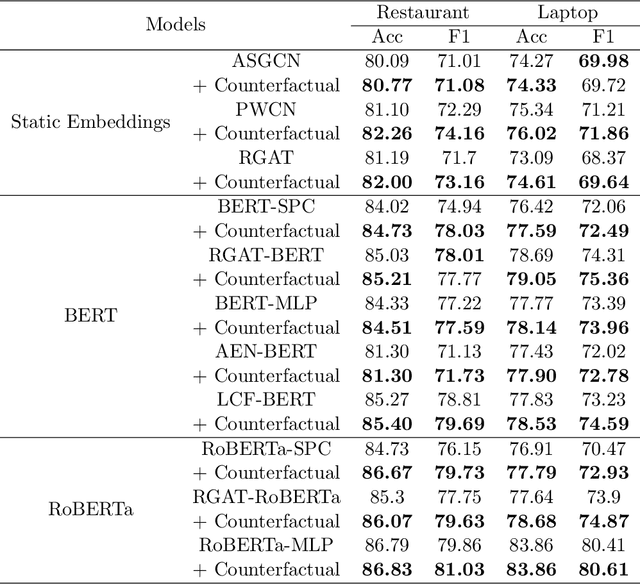
Aspect-based-sentiment-analysis (ABSA) is a fine-grained sentiment evaluation task, which analyze the emotional polarity of the evaluation aspects. However, previous works only focus on the identification of opinion expressions, forget that the diversity of opinion expressions also has great impacts on the ABSA task. To mitigate this problem, we propose a novel counterfactual data augmentation method to generate opinion expression with reversed sentiment polarity. Specially, the integrated gradients are calculated to identify and mask the opinion expression. Then, a prompt with the reverse label is combined to the original text, and a pre-trained language model (PLM), T5, is finally employed to retrieve the masks. The experimental results show the proposed counterfactual data augmentation method perform better than current augmentation methods on three ABSA datasets, i.e. Laptop, Restaurant and MAMS.