 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoPlan-Bench2: A Benchmark for Multimodal Large Language Model Planning in Real-World Scenarios
Paper and Code
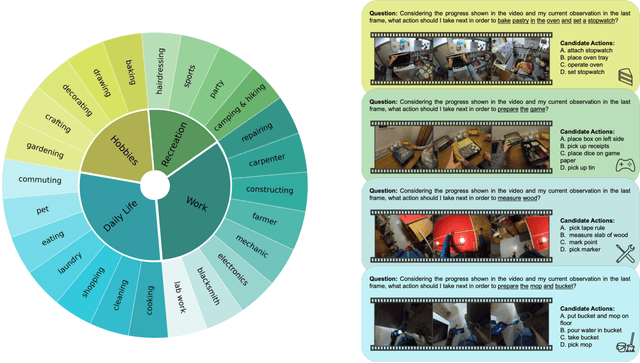



The advent of Multimodal Large Language Models, leveraging the power of Large Language Models, has recently demonstrated superior multimodal understanding and reasoning abilities, heralding a new era for artificial general intelligence. However, achieving AGI necessitates more than just comprehension and reasoning. A crucial capability required is effective planning in diverse scenarios, which involves making reasonable decisions based on complex environments to solve real-world problems. Despite its importance, the planning abilities of current MLLMs in varied scenarios remain underexplored. In this paper, we introduce EgoPlan-Bench2, a rigorous and comprehensive benchmark designed to assess the planning capabilities of MLLMs across a wide range of real-world scenarios. EgoPlan-Bench2 encompasses everyday tasks spanning 4 major domains and 24 detailed scenarios, closely aligned with human daily life. EgoPlan-Bench2 is constructed through a semi-automatic process utilizing egocentric videos, complemented by manual verification. Grounded in a first-person perspective, it mirrors the way humans approach problem-solving in everyday life. We evaluate 21 competitive MLLMs and provide an in-depth analysis of their limitations, revealing that they face significant challenges in real-world planning. To further improve the planning proficiency of current MLLMs, we propose a training-free approach using multimodal Chain-of-Thought (CoT) prompting through investigating the effectiveness of various multimodal prompts in complex planning. Our approach enhances the performance of GPT-4V by 10.24 on EgoPlan-Bench2 without additional training. Our work not only sheds light on the current limitations of MLLMs in planning, but also provides insights for future enhancements in this critical area. We have made data and code available at https://qiulu66.github.io/egoplanbench2/.