 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
Exploring the Effect of Reinforcement Learning on Video Understanding: Insights from SEED-Bench-R1
Mar 31, 2025



Recent advancements in Chain of Thought (COT) generation have significantly improved the reasoning capabilities of Large Language Models (LLMs), with reinforcement learning (RL) emerging as an effective post-training approach. Multimodal Large Language Models (MLLMs) inherit this reasoning potential but remain underexplored in tasks requiring both perception and logical reasoning. To address this, we introduce SEED-Bench-R1, a benchmark designed to systematically evaluate post-training methods for MLLMs in video understanding. It includes intricate real-world videos and complex everyday planning tasks in the format of multiple-choice questions, requiring sophisticated perception and reasoning. SEED-Bench-R1 assesses generalization through a three-level hierarchy: in-distribution, cross-environment, and cross-environment-task scenarios, equipped with a large-scale training dataset with easily verifiable ground-truth answers. Using Qwen2-VL-Instruct-7B as a base model, we compare RL with supervised fine-tuning (SFT), demonstrating RL's data efficiency and superior performance on both in-distribution and out-of-distribution tasks, even outperforming SFT on general video understanding benchmarks like LongVideoBench. Our detailed analysis reveals that RL enhances visual perception but often produces less logically coherent reasoning chains. We identify key limitations such as inconsistent reasoning and overlooked visual cues, and suggest future improvements in base model reasoning, reward modeling, and RL robustness against noisy signals.
EgoPlan-Bench2: A Benchmark for Multimodal Large Language Model Planning in Real-World Scenarios
Dec 05, 2024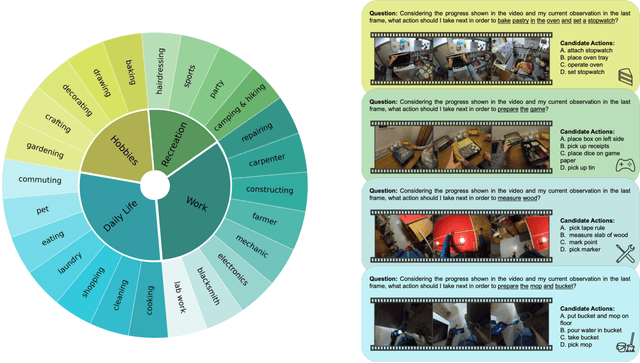



The advent of Multimodal Large Language Models, leveraging the power of Large Language Models, has recently demonstrated superior multimodal understanding and reasoning abilities, heralding a new era for artificial general intelligence. However, achieving AGI necessitates more than just comprehension and reasoning. A crucial capability required is effective planning in diverse scenarios, which involves making reasonable decisions based on complex environments to solve real-world problems. Despite its importance, the planning abilities of current MLLMs in varied scenarios remain underexplored. In this paper, we introduce EgoPlan-Bench2, a rigorous and comprehensive benchmark designed to assess the planning capabilities of MLLMs across a wide range of real-world scenarios. EgoPlan-Bench2 encompasses everyday tasks spanning 4 major domains and 24 detailed scenarios, closely aligned with human daily life. EgoPlan-Bench2 is constructed through a semi-automatic process utilizing egocentric videos, complemented by manual verification. Grounded in a first-person perspective, it mirrors the way humans approach problem-solving in everyday life. We evaluate 21 competitive MLLMs and provide an in-depth analysis of their limitations, revealing that they face significant challenges in real-world planning. To further improve the planning proficiency of current MLLMs, we propose a training-free approach using multimodal Chain-of-Thought (CoT) prompting through investigating the effectiveness of various multimodal prompts in complex planning. Our approach enhances the performance of GPT-4V by 10.24 on EgoPlan-Bench2 without additional training. Our work not only sheds light on the current limitations of MLLMs in planning, but also provides insights for future enhancements in this critical area. We have made data and code available at https://qiulu66.github.io/egoplanbench2/.