 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting CLIP Adaptation for Image Quality Assessment via Meta-Prompt Learning and Gradient Regularization
Paper and Code
Sep 09, 2024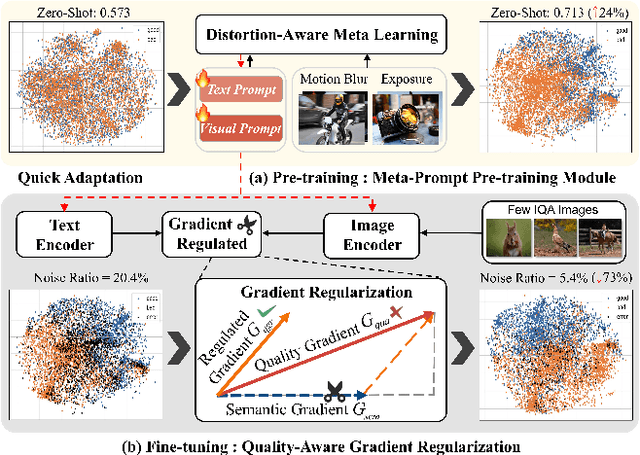
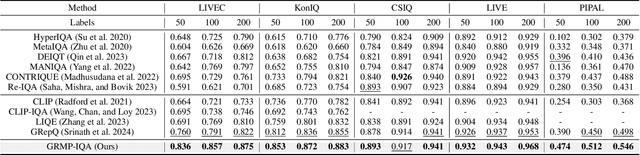


Image Quality Assessment (IQA) remains an unresolved challenge in the field of computer vision, due to complex distortion conditions, diverse image content, and limited data availability. The existing Blind IQA (BIQA) methods heavily rely on extensive human annotations to train models, which is both labor-intensive and costly due to the demanding nature of creating IQA datasets. To mitigate the dependence on labeled samples, this paper introduces a novel Gradient-Regulated Meta-Prompt IQA Framework (GRMP-IQA). This framework aims to fast adapt the powerful visual-language pre-trained model, CLIP, to downstream IQA tasks, significantly improving accuracy in scenarios with limited data. Specifically, the GRMP-IQA comprises two key modules: Meta-Prompt Pre-training Module and Quality-Aware Gradient Regularization. The Meta Prompt Pre-training Module leverages a meta-learning paradigm to pre-train soft prompts with shared meta-knowledge across different distortions, enabling rapid adaptation to various IQA tasks. On the other hand, the Quality-Aware Gradient Regularization is designed to adjust the update gradients during fine-tuning, focusing the model's attention on quality-relevant features and preventing overfitting to semantic information. Extensive experiments on five standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods under limited data setting, i.e., achieving SRCC values of 0.836 (vs. 0.760 on LIVEC) and 0.853 (vs. 0.812 on KonIQ). Notably, utilizing just 20\% of the training data, our GRMP-IQA outperforms most existing fully supervised BIQA methods.