 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiCLIP: An Efficient Contrastive Baseline for Open-domain Visual Entity Recognition
Mar 10, 2026Open-domain visual entity recognition (VER) seeks to associate images with entities in encyclopedic knowledge bases such as Wikipedia. Recent generative methods tailored for VER demonstrate strong performance but incur high computational costs, limiting their scalability and practical deployment. In this work, we revisit the contrastive paradigm for VER and introduce WikiCLIP, a simple yet effective framework that establishes a strong and efficient baseline for open-domain VER. WikiCLIP leverages large language model embeddings as knowledge-rich entity representations and enhances them with a Vision-Guided Knowledge Adaptor (VGKA) that aligns textual semantics with visual cues at the patch level. To further encourage fine-grained discrimination, a Hard Negative Synthesis Mechanism generates visually similar but semantically distinct negatives during training. Experimental results on popular open-domain VER benchmarks, such as OVEN, demonstrate that WikiCLIP significantly outperforms strong baselines. Specifically, WikiCLIP achieves a 16% improvement on the challenging OVEN unseen set, while reducing inference latency by nearly 100 times compared with the leading generative model, AutoVER. The project page is available at https://artanic30.github.io/project_pages/WikiCLIP/
Wiki-R1: Incentivizing Multimodal Reasoning for Knowledge-based VQA via Data and Sampling Curriculum
Mar 05, 2026Knowledge-Based Visual Question Answering (KB-VQA) requires models to answer questions about an image by integrating external knowledge, posing significant challenges due to noisy retrieval and the structured, encyclopedic nature of the knowledge base. These characteristics create a distributional gap from pretrained multimodal large language models (MLLMs), making effective reasoning and domain adaptation difficult in the post-training stage. In this work, we propose \textit{Wiki-R1}, a data-generation-based curriculum reinforcement learning framework that systematically incentivizes reasoning in MLLMs for KB-VQA. Wiki-R1 constructs a sequence of training distributions aligned with the model's evolving capability, bridging the gap from pretraining to the KB-VQA target distribution. We introduce \textit{controllable curriculum data generation}, which manipulates the retriever to produce samples at desired difficulty levels, and a \textit{curriculum sampling strategy} that selects informative samples likely to yield non-zero advantages during RL updates. Sample difficulty is estimated using observed rewards and propagated to unobserved samples to guide learning. Experiments on two KB-VQA benchmarks, Encyclopedic VQA and InfoSeek, demonstrate that Wiki-R1 achieves new state-of-the-art results, improving accuracy from 35.5\% to 37.1\% on Encyclopedic VQA and from 40.1\% to 44.1\% on InfoSeek. The project page is available at https://artanic30.github.io/project_pages/WikiR1/.
DA-DPO: Cost-efficient Difficulty-aware Preference Optimization for Reducing MLLM Hallucinations
Jan 02, 2026Direct Preference Optimization (DPO) has shown strong potential for mitigating hallucinations in Multimodal Large Language Models (MLLMs). However, existing multimodal DPO approaches often suffer from overfitting due to the difficulty imbalance in preference data. Our analysis shows that MLLMs tend to overemphasize easily distinguishable preference pairs, which hinders fine-grained hallucination suppression and degrades overall performance. To address this issue, we propose Difficulty-Aware Direct Preference Optimization (DA-DPO), a cost-effective framework designed to balance the learning process. DA-DPO consists of two main components: (1) Difficulty Estimation leverages pre-trained vision--language models with complementary generative and contrastive objectives, whose outputs are integrated via a distribution-aware voting strategy to produce robust difficulty scores without additional training; and (2) Difficulty-Aware Training reweights preference pairs based on their estimated difficulty, down-weighting easy samples while emphasizing harder ones to alleviate overfitting. This framework enables more effective preference optimization by prioritizing challenging examples, without requiring new data or extra fine-tuning stages. Extensive experiments demonstrate that DA-DPO consistently improves multimodal preference optimization, yielding stronger robustness to hallucinations and better generalization across standard benchmarks, while remaining computationally efficient. The project page is available at https://artanic30.github.io/project_pages/DA-DPO/.
Mining Fine-Grained Image-Text Alignment for Zero-Shot Captioning via Text-Only Training
Jan 04, 2024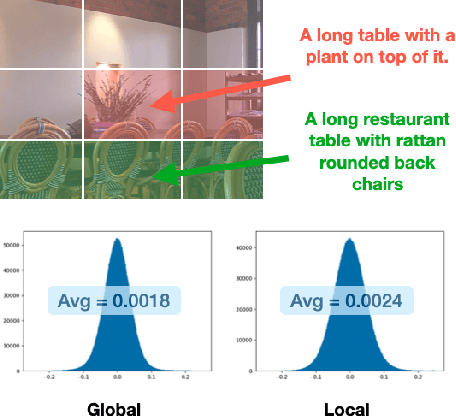
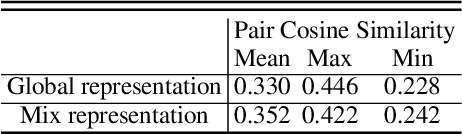
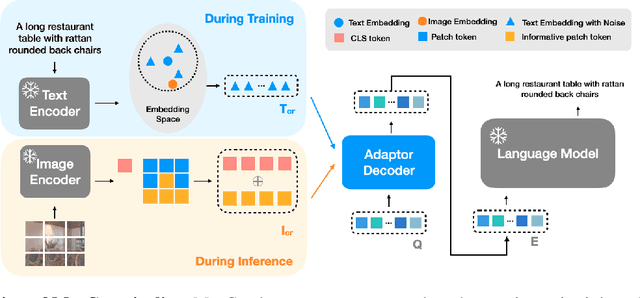
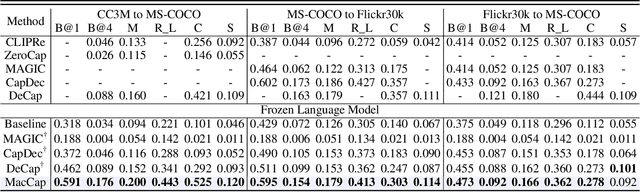
Image captioning aims at generating descriptive and meaningful textual descriptions of images, enabling a broad range of vision-language applications. Prior works have demonstrated that harnessing the power of Contrastive Image Language Pre-training (CLIP) offers a promising approach to achieving zero-shot captioning, eliminating the need for expensive caption annotations. However, the widely observed modality gap in the latent space of CLIP harms the performance of zero-shot captioning by breaking the alignment between paired image-text features. To address this issue, we conduct an analysis on the CLIP latent space which leads to two findings. Firstly, we observe that the CLIP's visual feature of image subregions can achieve closer proximity to the paired caption due to the inherent information loss in text descriptions. In addition, we show that the modality gap between a paired image-text can be empirically modeled as a zero-mean Gaussian distribution. Motivated by the findings, we propose a novel zero-shot image captioning framework with text-only training to reduce the modality gap. In particular, we introduce a subregion feature aggregation to leverage local region information, which produces a compact visual representation for matching text representation. Moreover, we incorporate a noise injection and CLIP reranking strategy to boost captioning performance. We also extend our framework to build a zero-shot VQA pipeline, demonstrating its generality. Through extensive experiments on common captioning and VQA datasets such as MSCOCO, Flickr30k and VQAV2, we show that our method achieves remarkable performance improvements. Code is available at https://github.com/Artanic30/MacCap.
HOICLIP: Efficient Knowledge Transfer for HOI Detection with Vision-Language Models
Mar 29, 2023



Human-Object Interaction (HOI) detection aims to localize human-object pairs and recognize their interactions. Recently, Contrastive Language-Image Pre-training (CLIP) has shown great potential in providing interaction prior for HOI detectors via knowledge distillation. However, such approaches often rely on large-scale training data and suffer from inferior performance under few/zero-shot scenarios. In this paper, we propose a novel HOI detection framework that efficiently extracts prior knowledge from CLIP and achieves better generalization. In detail, we first introduce a novel interaction decoder to extract informative regions in the visual feature map of CLIP via a cross-attention mechanism, which is then fused with the detection backbone by a knowledge integration block for more accurate human-object pair detection. In addition, prior knowledge in CLIP text encoder is leveraged to generate a classifier by embedding HOI descriptions. To distinguish fine-grained interactions, we build a verb classifier from training data via visual semantic arithmetic and a lightweight verb representation adapter. Furthermore, we propose a training-free enhancement to exploit global HOI predictions from CLIP. Extensive experiments demonstrate that our method outperforms the state of the art by a large margin on various settings, e.g. +4.04 mAP on HICO-Det. The source code is available in https://github.com/Artanic30/HOICLIP.