 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaEmbeddings: Efficient Russian Language Embedding Model
Oct 25, 2025We introduce GigaEmbeddings, a novel framework for training high-performance Russian-focused text embeddings through hierarchical instruction tuning of the decoder-only LLM designed specifically for Russian language (GigaChat-3B). Our three-stage pipeline, comprising large-scale contrastive pre-training in web-scale corpora, fine-tuning with hard negatives, and multitask generalization across retrieval, classification, and clustering tasks, addresses key limitations of existing methods by unifying diverse objectives and leveraging synthetic data generation. Architectural innovations include bidirectional attention for contextual modeling, latent attention pooling for robust sequence aggregation, and strategic pruning of 25% of transformer layers to enhance efficiency without compromising performance. Evaluated on the ruMTEB benchmark spanning 23 multilingual tasks, GigaEmbeddings achieves state-of-the-art results (69.1 avg. score), outperforming strong baselines with a larger number of parameters.
GigaChat Family: Efficient Russian Language Modeling Through Mixture of Experts Architecture
Jun 11, 2025Generative large language models (LLMs) have become crucial for modern NLP research and applications across various languages. However, the development of foundational models specifically tailored to the Russian language has been limited, primarily due to the significant computational resources required. This paper introduces the GigaChat family of Russian LLMs, available in various sizes, including base models and instruction-tuned versions. We provide a detailed report on the model architecture, pre-training process, and experiments to guide design choices. In addition, we evaluate their performance on Russian and English benchmarks and compare GigaChat with multilingual analogs. The paper presents a system demonstration of the top-performing models accessible via an API, a Telegram bot, and a Web interface. Furthermore, we have released three open GigaChat models in open-source (https://huggingface.co/ai-sage), aiming to expand NLP research opportunities and support the development of industrial solutions for the Russian language.
MERA: A Comprehensive LLM Evaluation in Russian
Jan 12, 2024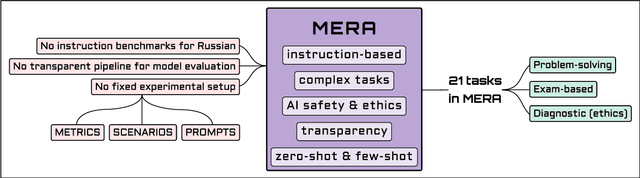
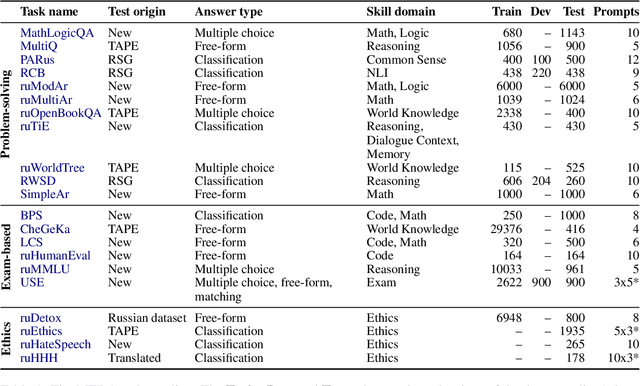

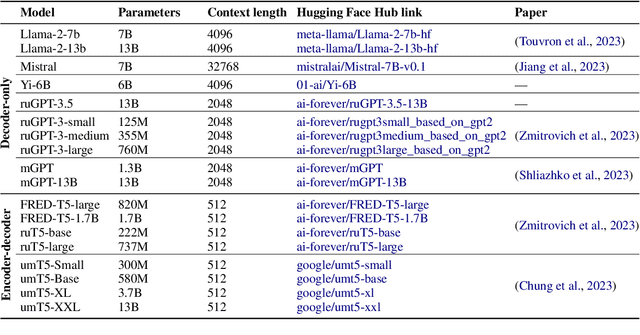
Over the past few years, one of the most notable advancements in AI research has been in foundation models (FMs), headlined by the rise of language models (LMs). As the models' size increases, LMs demonstrate enhancements in measurable aspects and the development of new qualitative features. However, despite researchers' attention and the rapid growth in LM application, the capabilities, limitations, and associated risks still need to be better understood. To address these issues, we introduce an open Multimodal Evaluation of Russian-language Architectures (MERA), a new instruction benchmark for evaluating foundation models oriented towards the Russian language. The benchmark encompasses 21 evaluation tasks for generative models in 11 skill domains and is designed as a black-box test to ensure the exclusion of data leakage. The paper introduces a methodology to evaluate FMs and LMs in zero- and few-shot fixed instruction settings that can be extended to other modalities. We propose an evaluation methodology, an open-source code base for the MERA assessment, and a leaderboard with a submission system. We evaluate open LMs as baselines and find that they are still far behind the human level. We publicly release MERA to guide forthcoming research, anticipate groundbreaking model features, standardize the evaluation procedure, and address potential societal drawbacks.
Large Raw Emotional Dataset with Aggregation Mechanism
Dec 23, 2022



We present a new data set for speech emotion recognition (SER) tasks called Dusha. The corpus contains approximately 350 hours of data, more than 300 000 audio recordings with Russian speech and their transcripts. Therefore it is the biggest open bi-modal data collection for SER task nowadays. It is annotated using a crowd-sourcing platform and includes two subsets: acted and real-life. Acted subset has a more balanced class distribution than the unbalanced real-life part consisting of audio podcasts. So the first one is suitable for model pre-training, and the second is elaborated for fine-tuning purposes, model approbation, and validation. This paper describes pre-processing routine, annotation, and experiment with a baseline model to demonstrate some actual metrics which could be obtained with the Dusha data set.