 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryfish: On deep audio analysis with Large Language Models
Aug 18, 2025The recent revolutionary progress in text-based large language models (LLMs) has contributed to the growth of interest in extending capabilities of such models to multimodal perception and understanding tasks. Hearing is an essential capability that is highly desired to be integrated into LLMs. However, effective integrating listening capabilities into LLMs is a significant challenge lying in generalizing complex auditory tasks across speech and sounds. To address these issues, we introduce Cryfish, our version of auditory-capable LLM. The model integrates WavLM audio-encoder features into Qwen2 model using a transformer-based connector. Cryfish is adapted to various auditory tasks through a specialized training strategy. We evaluate the model on the new Dynamic SUPERB Phase-2 comprehensive multitask benchmark specifically designed for auditory-capable models. The paper presents an in-depth analysis and detailed comparison of Cryfish with the publicly available models.
STCON System for the CHiME-8 Challenge
Oct 17, 2024



This paper describes the STCON system for the CHiME-8 Challenge Task 1 (DASR) aimed at distant automatic speech transcription and diarization with multiple recording devices. Our main attention was paid to carefully trained and tuned diarization pipeline and speaker counting. This allowed to significantly reduce diarization error rate (DER) and obtain more reliable segments for speech separation and recognition. To improve source separation, we designed a Guided Target speaker Extraction (G-TSE) model and used it in conjunction with the traditional Guided Source Separation (GSS) method. To train various parts of our pipeline, we investigated several data augmentation and generation techniques, which helped us to improve the overall system quality.
LT-LM: a novel non-autoregressive language model for single-shot lattice rescoring
Apr 06, 2021
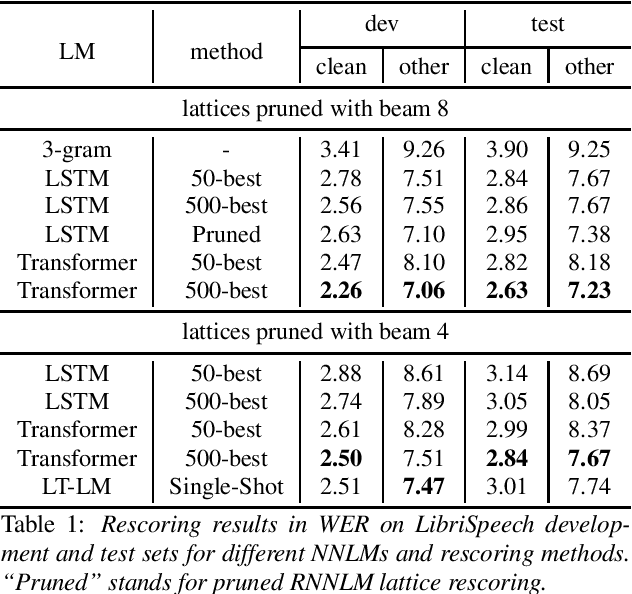
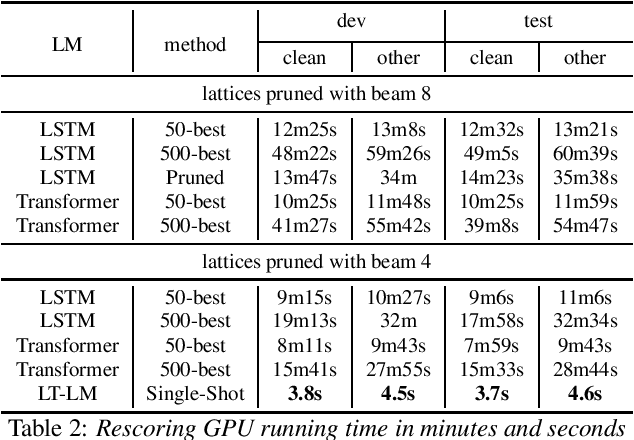
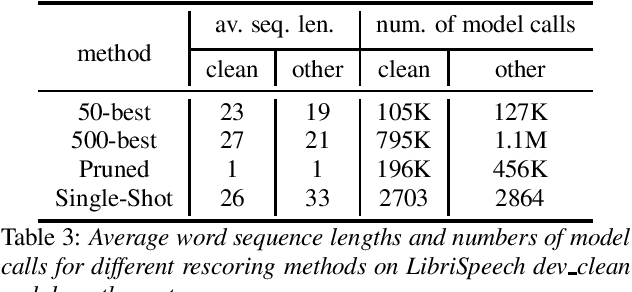
Neural network-based language models are commonly used in rescoring approaches to improve the quality of modern automatic speech recognition (ASR) systems. Most of the existing methods are computationally expensive since they use autoregressive language models. We propose a novel rescoring approach, which processes the entire lattice in a single call to the model. The key feature of our rescoring policy is a novel non-autoregressive Lattice Transformer Language Model (LT-LM). This model takes the whole lattice as an input and predicts a new language score for each arc. Additionally, we propose the artificial lattices generation approach to incorporate a large amount of text data in the LT-LM training process. Our single-shot rescoring performs orders of magnitude faster than other rescoring methods in our experiments. It is more than 300 times faster than pruned RNNLM lattice rescoring and N-best rescoring while slightly inferior in terms of WER.
Dynamic Acoustic Unit Augmentation With BPE-Dropout for Low-Resource End-to-End Speech Recognition
Mar 12, 2021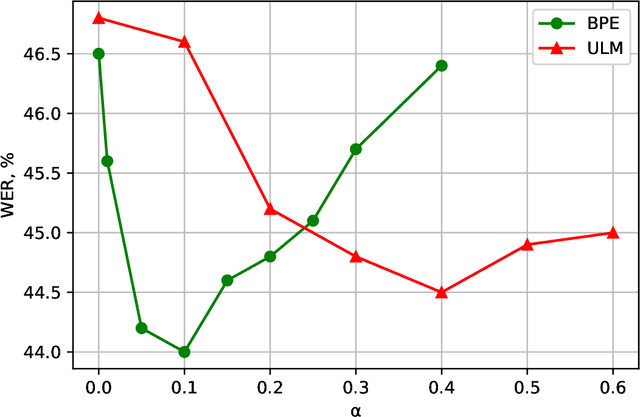
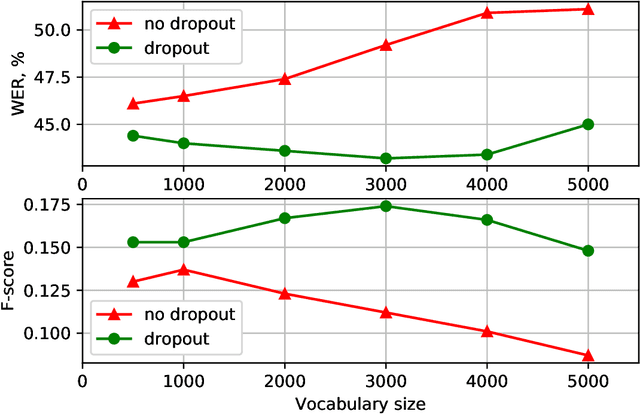
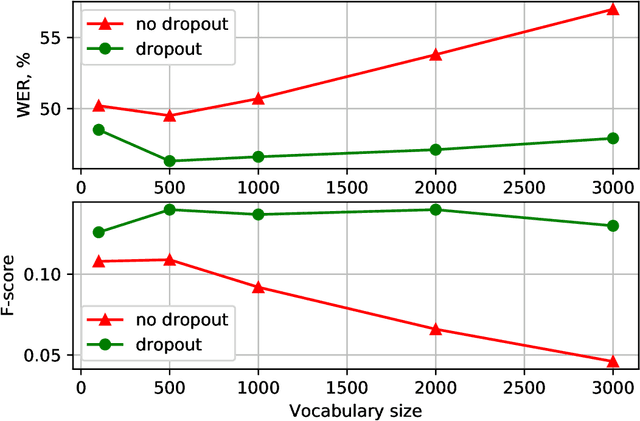
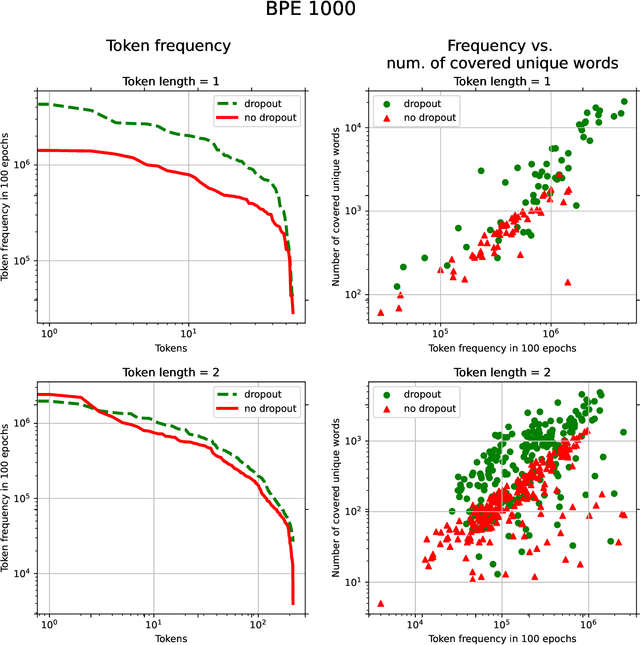
With the rapid development of speech assistants, adapting server-intended automatic speech recognition (ASR) solutions to a direct device has become crucial. Researchers and industry prefer to use end-to-end ASR systems for on-device speech recognition tasks. This is because end-to-end systems can be made resource-efficient while maintaining a higher quality compared to hybrid systems. However, building end-to-end models requires a significant amount of speech data. Another challenging task associated with speech assistants is personalization, which mainly lies in handling out-of-vocabulary (OOV) words. In this work, we consider building an effective end-to-end ASR system in low-resource setups with a high OOV rate, embodied in Babel Turkish and Babel Georgian tasks. To address the aforementioned problems, we propose a method of dynamic acoustic unit augmentation based on the BPE-dropout technique. It non-deterministically tokenizes utterances to extend the token's contexts and to regularize their distribution for the model's recognition of unseen words. It also reduces the need for optimal subword vocabulary size search. The technique provides a steady improvement in regular and personalized (OOV-oriented) speech recognition tasks (at least 6% relative WER and 25% relative F-score) at no additional computational cost. Owing to the use of BPE-dropout, our monolingual Turkish Conformer established a competitive result with 22.2% character error rate (CER) and 38.9% word error rate (WER), which is close to the best published multilingual system.
Target-Speaker Voice Activity Detection: a Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario
May 14, 2020
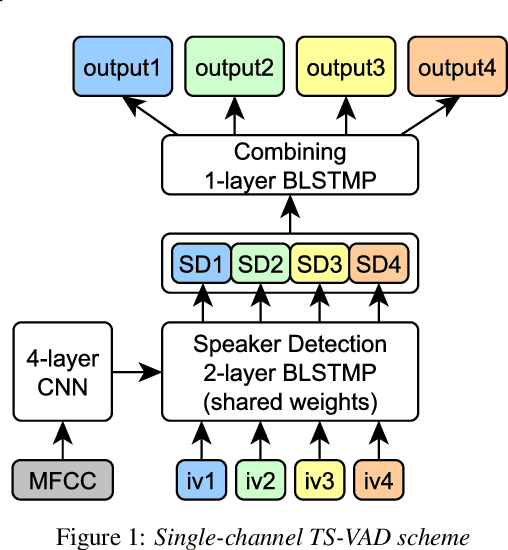
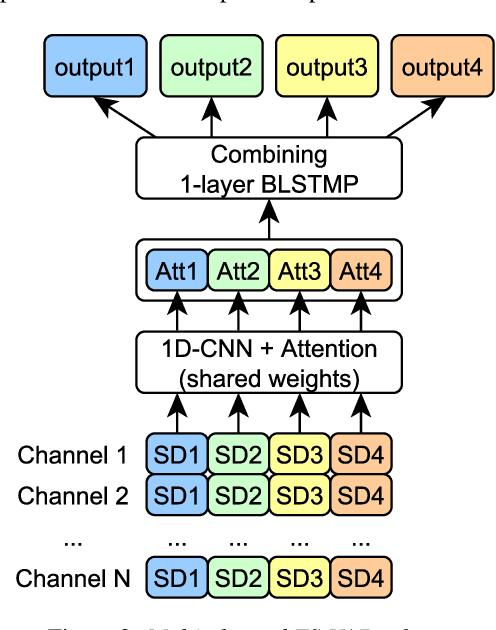
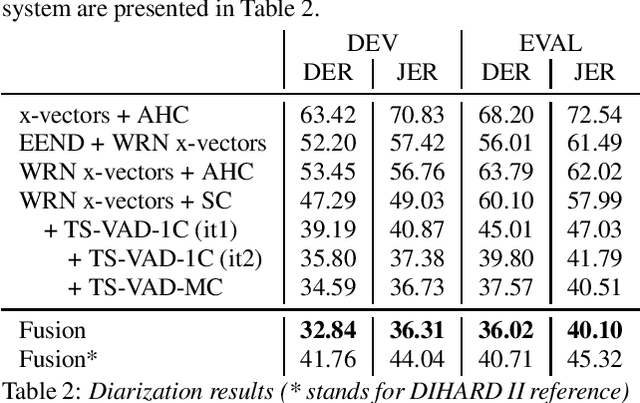
Speaker diarization for real-life scenarios is an extremely challenging problem. Widely used clustering-based diarization approaches perform rather poorly in such conditions, mainly due to the limited ability to handle overlapping speech. We propose a novel Target-Speaker Voice Activity Detection (TS-VAD) approach, which directly predicts an activity of each speaker on each time frame. TS-VAD model takes conventional speech features (e.g., MFCC) along with i-vectors for each speaker as inputs. A set of binary classification output layers produces activities of each speaker. I-vectors can be estimated iteratively, starting with a strong clustering-based diarization. We also extend the TS-VAD approach to the multi-microphone case using a simple attention mechanism on top of hidden representations extracted from the single-channel TS-VAD model. Moreover, post-processing strategies for the predicted speaker activity probabilities are investigated. Experiments on the CHiME-6 unsegmented data show that TS-VAD achieves state-of-the-art results outperforming the baseline x-vector-based system by more than 30% Diarization Error Rate (DER) abs.