 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTCON System for the CHiME-8 Challenge
Oct 17, 2024



This paper describes the STCON system for the CHiME-8 Challenge Task 1 (DASR) aimed at distant automatic speech transcription and diarization with multiple recording devices. Our main attention was paid to carefully trained and tuned diarization pipeline and speaker counting. This allowed to significantly reduce diarization error rate (DER) and obtain more reliable segments for speech separation and recognition. To improve source separation, we designed a Guided Target speaker Extraction (G-TSE) model and used it in conjunction with the traditional Guided Source Separation (GSS) method. To train various parts of our pipeline, we investigated several data augmentation and generation techniques, which helped us to improve the overall system quality.
Uconv-Conformer: High Reduction of Input Sequence Length for End-to-End Speech Recognition
Aug 16, 2022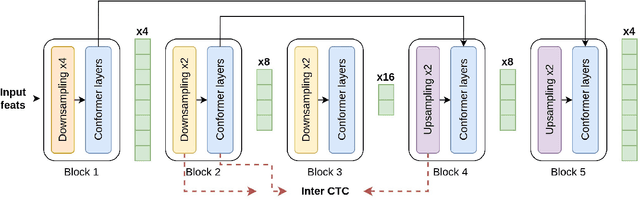
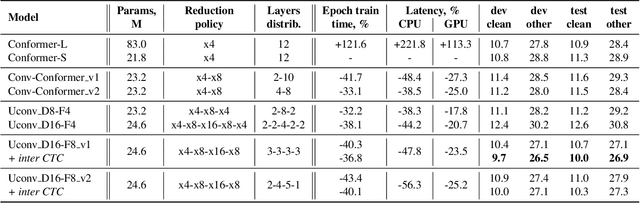
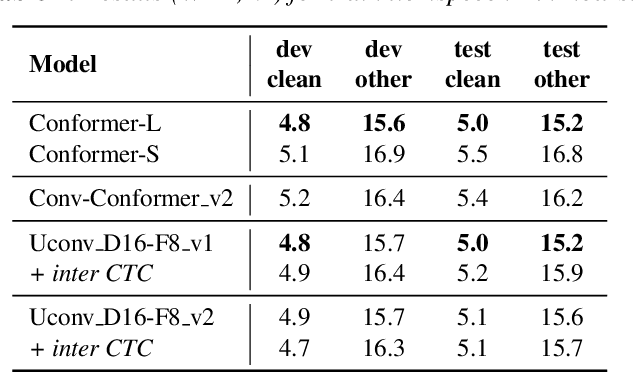
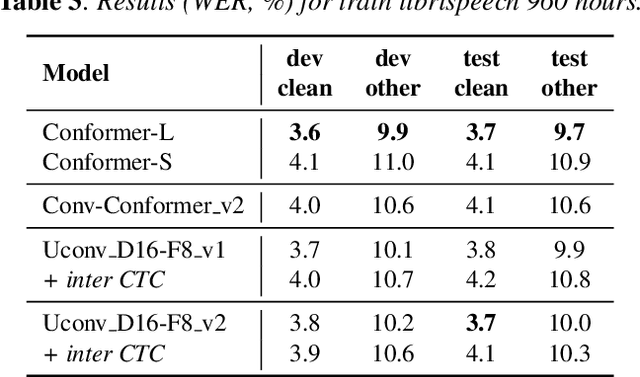
Optimization of modern ASR architectures is among the highest priority tasks since it saves many computational resources for model training and inference. The work proposes a new Uconv-Conformer architecture based on the standard Conformer model that consistently reduces the input sequence length by 16 times, which results in speeding up the work of the intermediate layers. To solve the convergence problem with such a significant reduction of the time dimension, we use upsampling blocks similar to the U-Net architecture to ensure the correct CTC loss calculation and stabilize network training. The Uconv-Conformer architecture appears to be not only faster in terms of training and inference but also shows better WER compared to the baseline Conformer. Our best Uconv-Conformer model showed 40.3% epoch training time reduction, 47.8%, and 23.5% inference acceleration on the CPU and GPU, respectively. Relative WER on Librispeech test_clean and test_other decreased by 7.3% and 9.2%.
LT-LM: a novel non-autoregressive language model for single-shot lattice rescoring
Apr 06, 2021
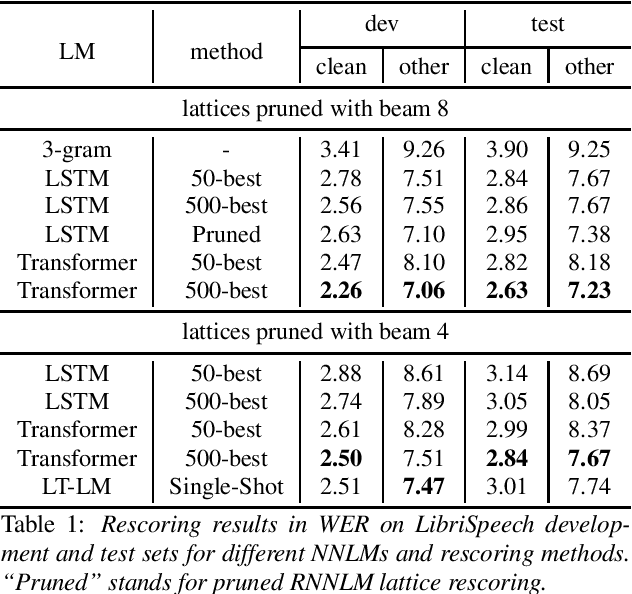
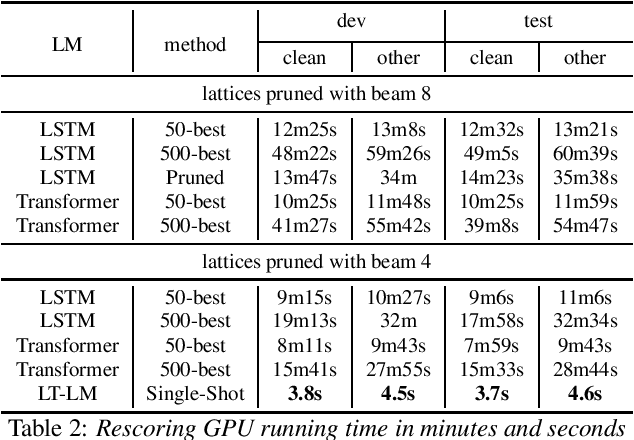
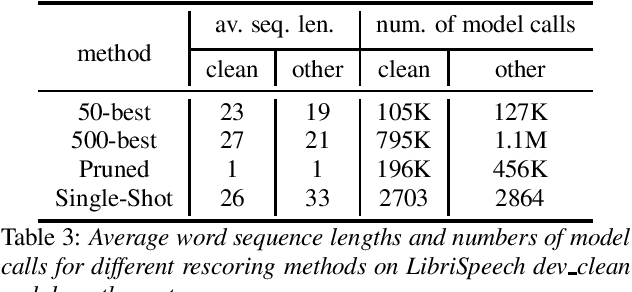
Neural network-based language models are commonly used in rescoring approaches to improve the quality of modern automatic speech recognition (ASR) systems. Most of the existing methods are computationally expensive since they use autoregressive language models. We propose a novel rescoring approach, which processes the entire lattice in a single call to the model. The key feature of our rescoring policy is a novel non-autoregressive Lattice Transformer Language Model (LT-LM). This model takes the whole lattice as an input and predicts a new language score for each arc. Additionally, we propose the artificial lattices generation approach to incorporate a large amount of text data in the LT-LM training process. Our single-shot rescoring performs orders of magnitude faster than other rescoring methods in our experiments. It is more than 300 times faster than pruned RNNLM lattice rescoring and N-best rescoring while slightly inferior in terms of WER.
Target-Speaker Voice Activity Detection: a Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario
May 14, 2020
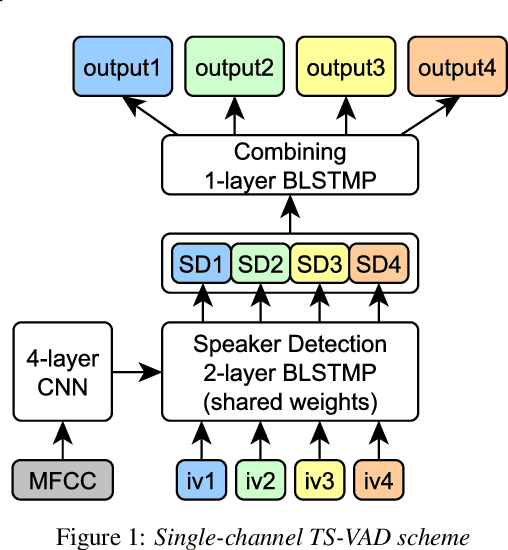
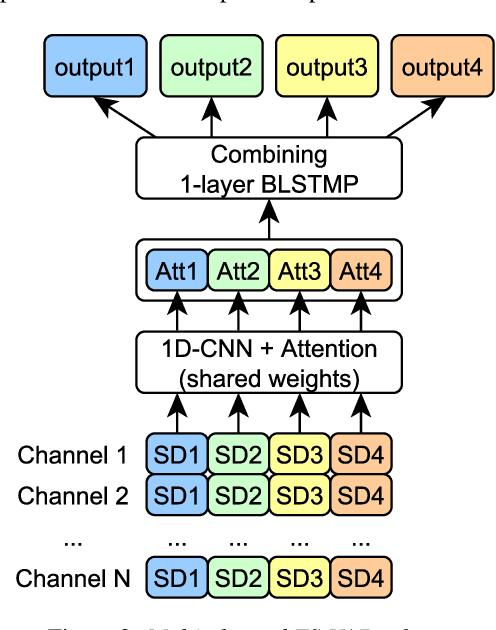
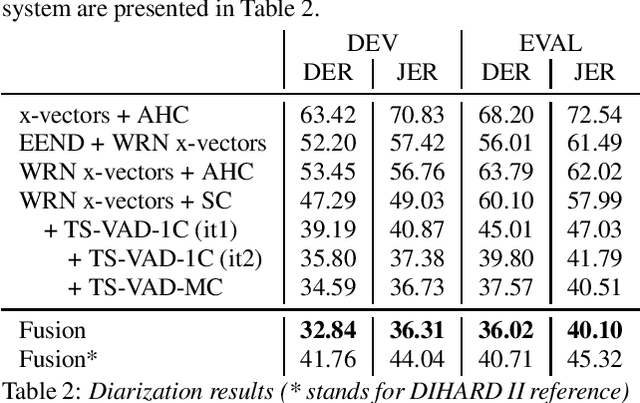
Speaker diarization for real-life scenarios is an extremely challenging problem. Widely used clustering-based diarization approaches perform rather poorly in such conditions, mainly due to the limited ability to handle overlapping speech. We propose a novel Target-Speaker Voice Activity Detection (TS-VAD) approach, which directly predicts an activity of each speaker on each time frame. TS-VAD model takes conventional speech features (e.g., MFCC) along with i-vectors for each speaker as inputs. A set of binary classification output layers produces activities of each speaker. I-vectors can be estimated iteratively, starting with a strong clustering-based diarization. We also extend the TS-VAD approach to the multi-microphone case using a simple attention mechanism on top of hidden representations extracted from the single-channel TS-VAD model. Moreover, post-processing strategies for the predicted speaker activity probabilities are investigated. Experiments on the CHiME-6 unsegmented data show that TS-VAD achieves state-of-the-art results outperforming the baseline x-vector-based system by more than 30% Diarization Error Rate (DER) abs.