 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransducers with Pronunciation-aware Embeddings for Automatic Speech Recognition
Paper and Code
Apr 04, 2024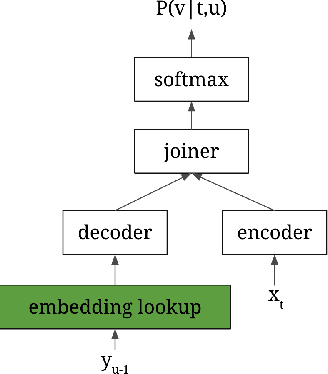

This paper proposes Transducers with Pronunciation-aware Embeddings (PET). Unlike conventional Transducers where the decoder embeddings for different tokens are trained independently, the PET model's decoder embedding incorporates shared components for text tokens with the same or similar pronunciations. With experiments conducted in multiple datasets in Mandarin Chinese and Korean, we show that PET models consistently improve speech recognition accuracy compared to conventional Transducers. Our investigation also uncovers a phenomenon that we call error chain reactions. Instead of recognition errors being evenly spread throughout an utterance, they tend to group together, with subsequent errors often following earlier ones. Our analysis shows that PET models effectively mitigate this issue by substantially reducing the likelihood of the model generating additional errors following a prior one. Our implementation will be open-sourced with the NeMo toolkit.