Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMRT Chatbots: Improving Non-Task-Oriented Dialog with Simulated Multiple Reference Training
Paper and Code
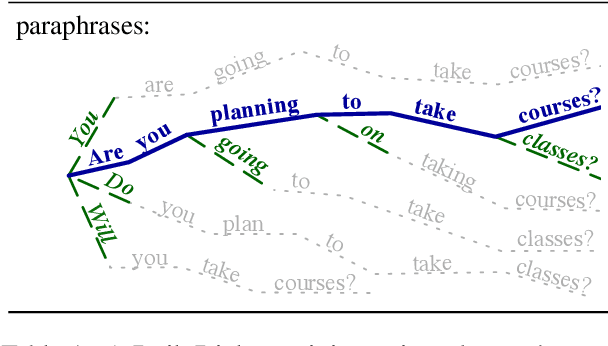

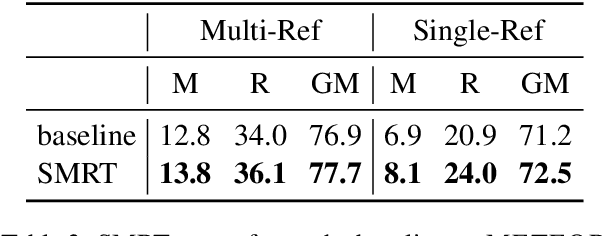
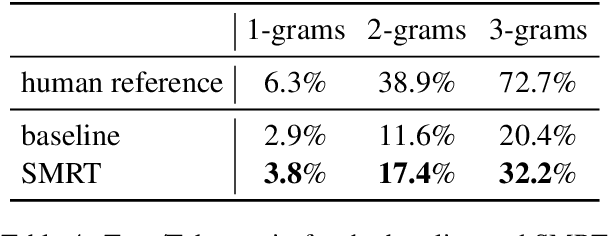
Non-task-oriented dialog models suffer from poor quality and non-diverse responses. To overcome limited conversational data, we apply Simulated Multiple Reference Training (SMRT; Khayrallah et al., 2020), and use a paraphraser to simulate multiple responses per training prompt. We find SMRT improves over a strong Transformer baseline as measured by human and automatic quality scores and lexical diversity. We also find SMRT is comparable to pretraining in human evaluation quality, and outperforms pretraining on automatic quality and lexical diversity, without requiring related-domain dialog data.
* EMNLP 2020 Camera Ready
View paper on