 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRényi State Entropy for Exploration Acceleration in Reinforcement Learning
Mar 08, 2022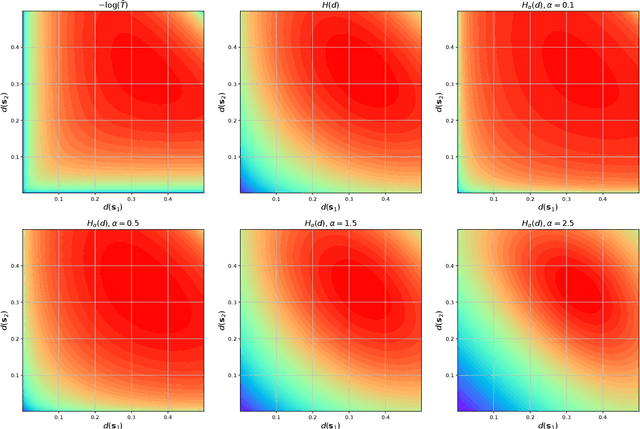
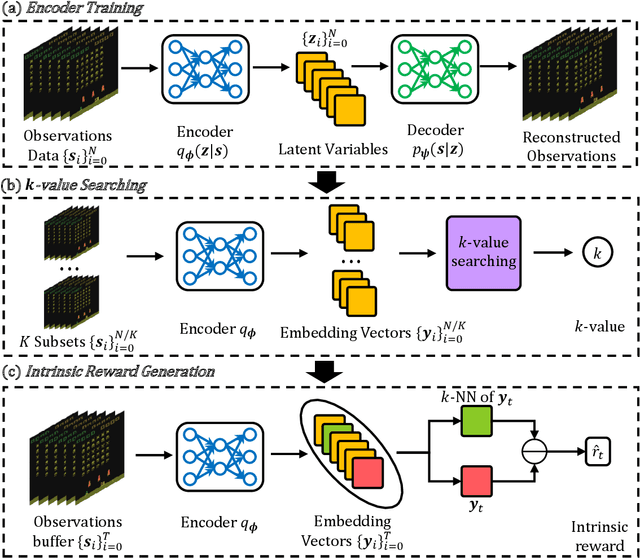


One of the most critical challenges in deep reinforcement learning is to maintain the long-term exploration capability of the agent. To tackle this problem, it has been recently proposed to provide intrinsic rewards for the agent to encourage exploration. However, most existing intrinsic reward-based methods proposed in the literature fail to provide sustainable exploration incentives, a problem known as vanishing rewards. In addition, these conventional methods incur complex models and additional memory in their learning procedures, resulting in high computational complexity and low robustness. In this work, a novel intrinsic reward module based on the R\'enyi entropy is proposed to provide high-quality intrinsic rewards. It is shown that the proposed method actually generalizes the existing state entropy maximization methods. In particular, a $k$-nearest neighbor estimator is introduced for entropy estimation while a $k$-value search method is designed to guarantee the estimation accuracy. Extensive simulation results demonstrate that the proposed R\'enyi entropy-based method can achieve higher performance as compared to existing schemes.
Towards User Scheduling for 6G: A Fairness-Oriented Scheduler Using Multi-Agent Reinforcement Learning
Feb 04, 2021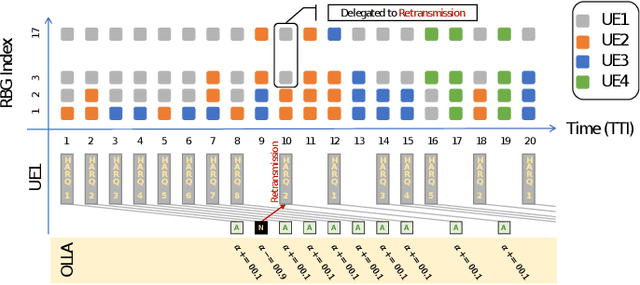
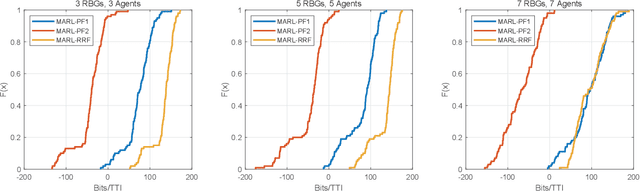
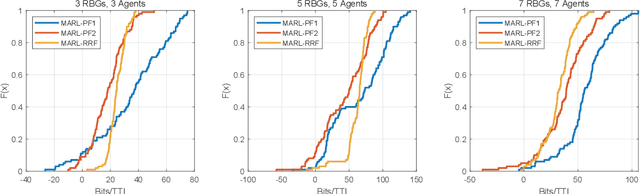
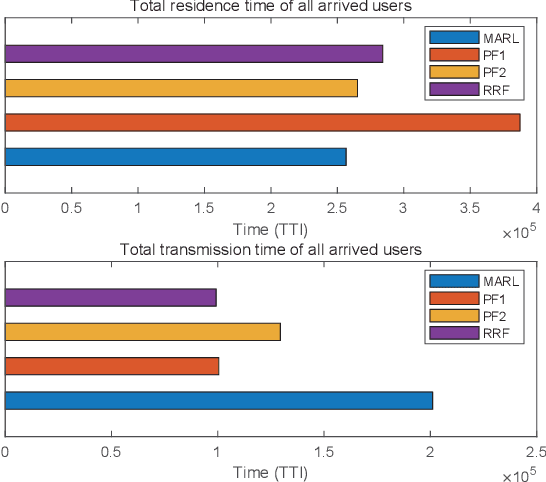
User scheduling is a classical problem and key technology in wireless communication, which will still plays an important role in the prospective 6G. There are many sophisticated schedulers that are widely deployed in the base stations, such as Proportional Fairness (PF) and Round-Robin Fashion (RRF). It is known that the Opportunistic (OP) scheduling is the optimal scheduler for maximizing the average user data rate (AUDR) considering the full buffer traffic. But the optimal strategy achieving the highest fairness still remains largely unknown both in the full buffer traffic and the bursty traffic. In this work, we investigate the problem of fairness-oriented user scheduling, especially for the RBG allocation. We build a user scheduler using Multi-Agent Reinforcement Learning (MARL), which conducts distributional optimization to maximize the fairness of the communication system. The agents take the cross-layer information (e.g. RSRP, Buffer size) as state and the RBG allocation result as action, then explore the optimal solution following a well-defined reward function designed for maximizing fairness. Furthermore, we take the 5%-tile user data rate (5TUDR) as the key performance indicator (KPI) of fairness, and compare the performance of MARL scheduling with PF scheduling and RRF scheduling by conducting extensive simulations. And the simulation results show that the proposed MARL scheduling outperforms the traditional schedulers.