 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Attention: Topology-aware Decoding for Long-Context Attention on GPU clusters
Aug 09, 2024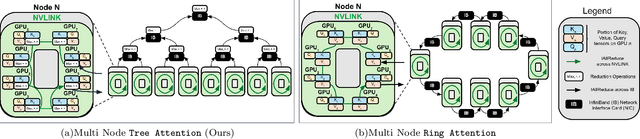
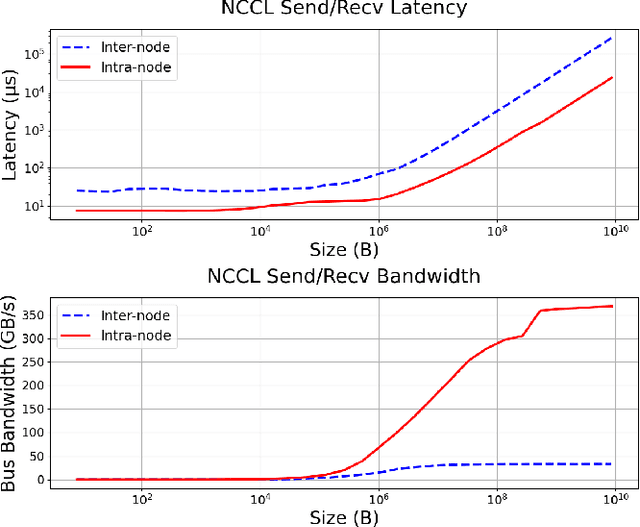
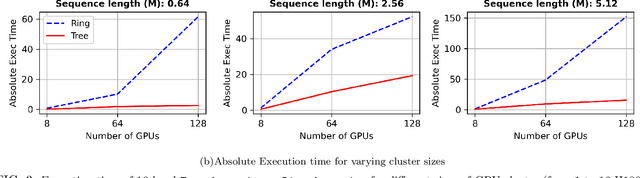
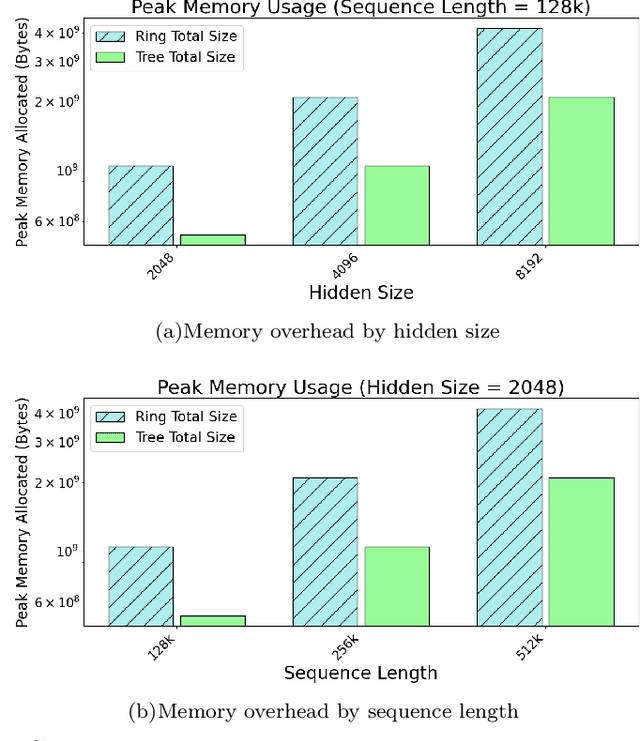
Self-attention is the core mathematical operation of modern transformer architectures and is also a significant computational bottleneck due to its quadratic complexity in the sequence length. In this work, we derive the scalar energy function whose gradient computes the self-attention block, thus elucidating the theoretical underpinnings of self-attention, providing a Bayesian interpretation of the operation and linking it closely with energy-based models such as Hopfield Networks. Our formulation reveals that the reduction across the sequence axis can be efficiently computed in parallel through a tree reduction. Our algorithm, for parallelizing attention computation across multiple GPUs enables cross-device decoding to be performed asymptotically faster (up to 8x faster in our experiments) than alternative approaches such as Ring Attention, while also requiring significantly less communication volume and incurring 2x less peak memory. Our code is publicly available here: \url{https://github.com/Zyphra/tree_attention}.