 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry Breaking in Transformers for Efficient and Interpretable Training
Jan 29, 2026The attention mechanism in its standard implementation contains extraneous rotational degrees of freedom that are carried through computation but do not affect model activations or outputs. We introduce a simple symmetry-breaking protocol that inserts a preferred direction into this rotational space through batchwise-sampled, unlearned query and value biases. This modification has two theoretically motivated and empirically validated consequences. First, it can substantially improve the performance of simple, memory-efficient optimizers, narrowing -- and in some cases closing -- the gap to successful but more complex memory-intensive adaptive methods. We demonstrate this by pretraining 124M parameter transformer models with four optimization algorithms (AdamW, SOAP, SGDM, and Energy Conserving Descent(ECD)) and evaluating both validation loss and downstream logical reasoning. Second, it enables an interpretable use of otherwise redundant rotational degrees of freedom, selectively amplifying semantically meaningful token classes within individual attention heads. Overall, our results show that minimal, principled architectural changes can simultaneously improve performance and interpretability.
The Zamba2 Suite: Technical Report
Nov 22, 2024In this technical report, we present the Zamba2 series -- a suite of 1.2B, 2.7B, and 7.4B parameter hybrid Mamba2-transformer models that achieve state of the art performance against the leading open-weights models of their class, while achieving substantial gains in inference latency, throughput, and memory efficiency. The Zamba2 series builds upon our initial work with Zamba1-7B, optimizing its architecture, training and annealing datasets, and training for up to three trillion tokens. We provide open-source weights for all models of the Zamba2 series as well as instruction-tuned variants that are strongly competitive against comparable instruct-tuned models of their class. We additionally open-source the pretraining dataset, which we call Zyda-2, used to train the Zamba2 series of models. The models and datasets used in this work are openly available at https://huggingface.co/Zyphra
Tree Attention: Topology-aware Decoding for Long-Context Attention on GPU clusters
Aug 09, 2024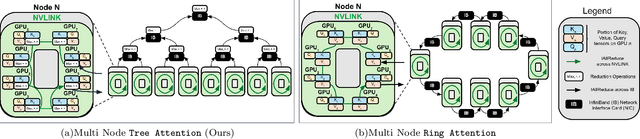
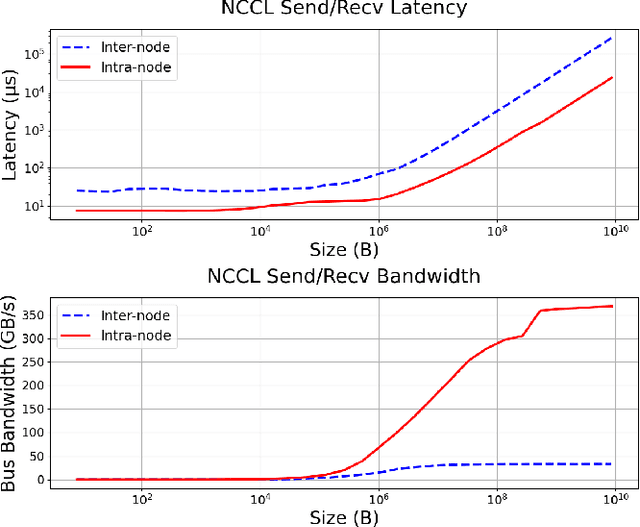
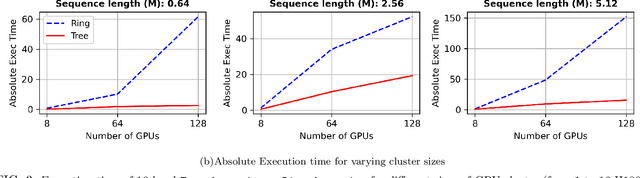
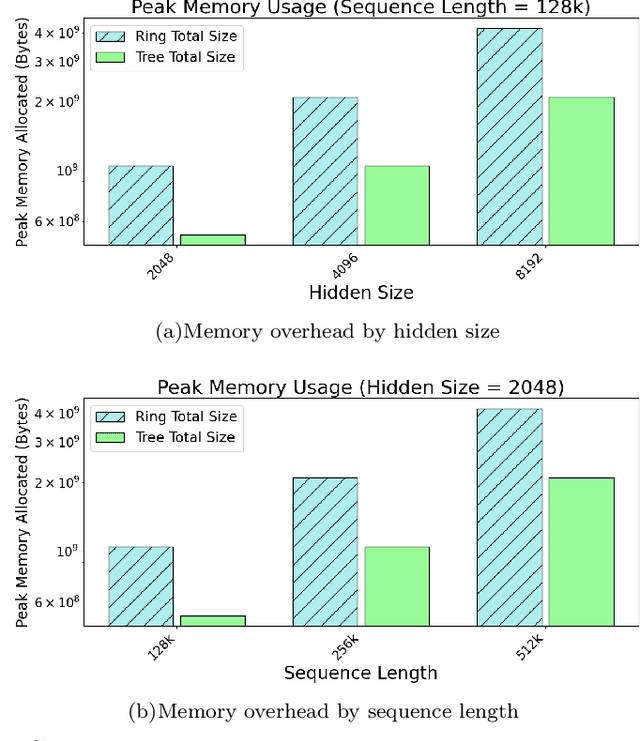
Self-attention is the core mathematical operation of modern transformer architectures and is also a significant computational bottleneck due to its quadratic complexity in the sequence length. In this work, we derive the scalar energy function whose gradient computes the self-attention block, thus elucidating the theoretical underpinnings of self-attention, providing a Bayesian interpretation of the operation and linking it closely with energy-based models such as Hopfield Networks. Our formulation reveals that the reduction across the sequence axis can be efficiently computed in parallel through a tree reduction. Our algorithm, for parallelizing attention computation across multiple GPUs enables cross-device decoding to be performed asymptotically faster (up to 8x faster in our experiments) than alternative approaches such as Ring Attention, while also requiring significantly less communication volume and incurring 2x less peak memory. Our code is publicly available here: \url{https://github.com/Zyphra/tree_attention}.