 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Vector Quantized Attention
Feb 03, 2026Standard sequence mixing layers used in language models struggle to balance efficiency and performance. Self-attention performs well on long context tasks but has expensive quadratic compute and linear memory costs, while linear attention and SSMs use only linear compute and constant memory but struggle with long context processing. In this paper, we develop a sequence mixing layer that aims to find a better compromise between memory-compute costs and long-context processing, which we call online vector-quantized (OVQ) attention. OVQ-attention requires linear compute costs and constant memory, but, unlike linear attention and SSMs, it uses a sparse memory update that allows it to greatly increase the size of its memory state and, consequently, memory capacity. We develop a theoretical basis for OVQ-attention based on Gaussian mixture regression, and we test it on a variety of synthetic long context tasks and on long context language modeling. OVQ-attention shows significant improvements over linear attention baselines and the original VQ-attention, on which OVQ-attention was inspired. It demonstrates competitive, and sometimes identical, performance to strong self-attention baselines up 64k sequence length, despite using a small fraction of the memory of full self-attention.
Toward Conversational Agents with Context and Time Sensitive Long-term Memory
May 29, 2024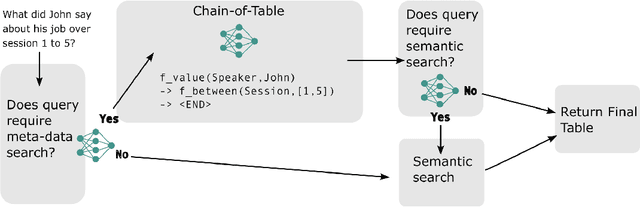
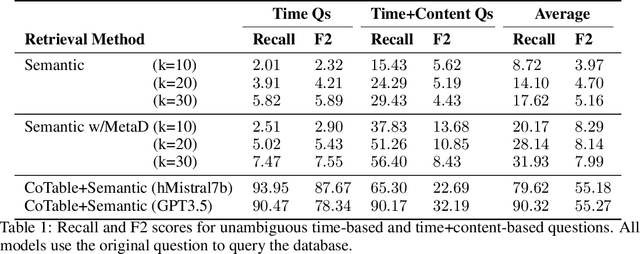
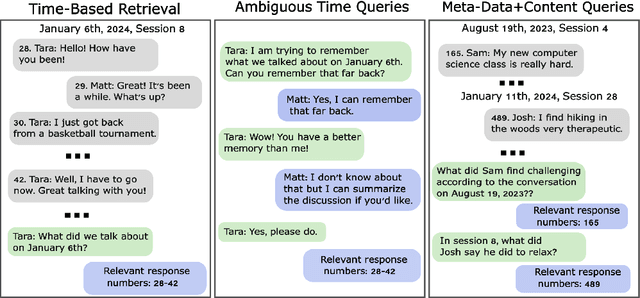

There has recently been growing interest in conversational agents with long-term memory which has led to the rapid development of language models that use retrieval-augmented generation (RAG). Until recently, most work on RAG has focused on information retrieval from large databases of texts, like Wikipedia, rather than information from long-form conversations. In this paper, we argue that effective retrieval from long-form conversational data faces two unique problems compared to static database retrieval: 1) time/event-based queries, which requires the model to retrieve information about previous conversations based on time or the order of a conversational event (e.g., the third conversation on Tuesday), and 2) ambiguous queries that require surrounding conversational context to understand. To better develop RAG-based agents that can deal with these challenges, we generate a new dataset of ambiguous and time-based questions that build upon a recent dataset of long-form, simulated conversations, and demonstrate that standard RAG based approaches handle such questions poorly. We then develop a novel retrieval model which combines chained-of-table search methods, standard vector-database retrieval, and a prompting method to disambiguate queries, and demonstrate that this approach substantially improves over current methods at solving these tasks. We believe that this new dataset and more advanced RAG agent can act as a key benchmark and stepping stone towards effective memory augmented conversational agents that can be used in a wide variety of AI applications.
A Sparse Quantized Hopfield Network for Online-Continual Memory
Jul 27, 2023An important difference between brains and deep neural networks is the way they learn. Nervous systems learn online where a stream of noisy data points are presented in a non-independent, identically distributed (non-i.i.d.) way. Further, synaptic plasticity in the brain depends only on information local to synapses. Deep networks, on the other hand, typically use non-local learning algorithms and are trained in an offline, non-noisy, i.i.d. setting. Understanding how neural networks learn under the same constraints as the brain is an open problem for neuroscience and neuromorphic computing. A standard approach to this problem has yet to be established. In this paper, we propose that discrete graphical models that learn via an online maximum a posteriori learning algorithm could provide such an approach. We implement this kind of model in a novel neural network called the Sparse Quantized Hopfield Network (SQHN). We show that SQHNs outperform state-of-the-art neural networks on associative memory tasks, outperform these models in online, non-i.i.d. settings, learn efficiently with noisy inputs, and are better than baselines on a novel episodic memory task.
Understanding and Improving Optimization in Predictive Coding Networks
May 23, 2023
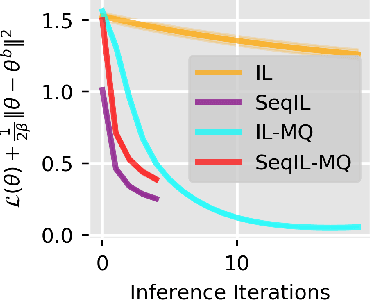
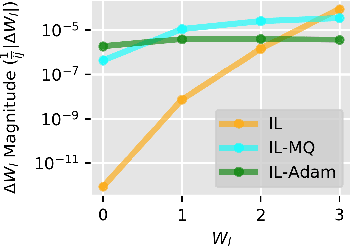

Backpropagation (BP), the standard learning algorithm for artificial neural networks, is often considered biologically implausible. In contrast, the standard learning algorithm for predictive coding (PC) models in neuroscience, known as the inference learning algorithm (IL), is a promising, bio-plausible alternative. However, several challenges and questions hinder IL's application to real-world problems. For example, IL is computationally demanding, and without memory-intensive optimizers like Adam, IL may converge to poor local minima. Moreover, although IL can reduce loss more quickly than BP, the reasons for these speedups or their robustness remains unclear. In this paper, we tackle these challenges by 1) altering the standard implementation of PC circuits to substantially reduce computation, 2) developing a novel optimizer that improves the convergence of IL without increasing memory usage, and 3) establishing theoretical results that help elucidate the conditions under which IL is sensitive to second and higher-order information.
A Theoretical Framework for Inference Learning
Jun 01, 2022
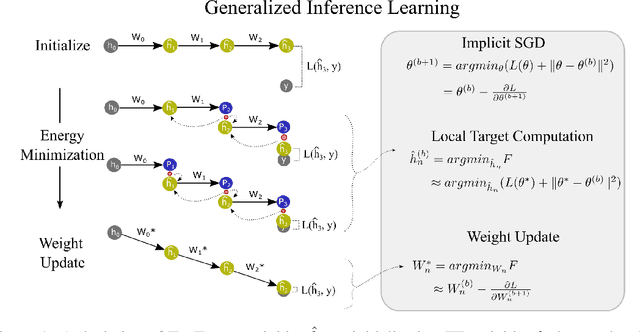
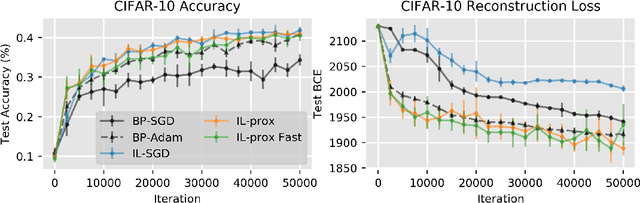
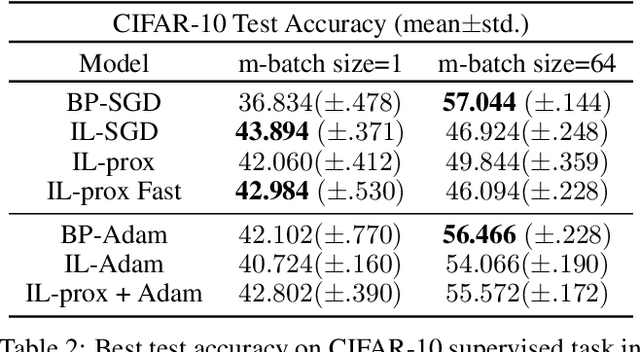
Backpropagation (BP) is the most successful and widely used algorithm in deep learning. However, the computations required by BP are challenging to reconcile with known neurobiology. This difficulty has stimulated interest in more biologically plausible alternatives to BP. One such algorithm is the inference learning algorithm (IL). IL has close connections to neurobiological models of cortical function and has achieved equal performance to BP on supervised learning and auto-associative tasks. In contrast to BP, however, the mathematical foundations of IL are not well-understood. Here, we develop a novel theoretical framework for IL. Our main result is that IL closely approximates an optimization method known as implicit stochastic gradient descent (implicit SGD), which is distinct from the explicit SGD implemented by BP. Our results further show how the standard implementation of IL can be altered to better approximate implicit SGD. Our novel implementation considerably improves the stability of IL across learning rates, which is consistent with our theory, as a key property of implicit SGD is its stability. We provide extensive simulation results that further support our theoretical interpretations and also demonstrate IL achieves quicker convergence when trained with small mini-batches while matching the performance of BP for large mini-batches.
Tightening the Biological Constraints on Gradient-Based Predictive Coding
Apr 30, 2021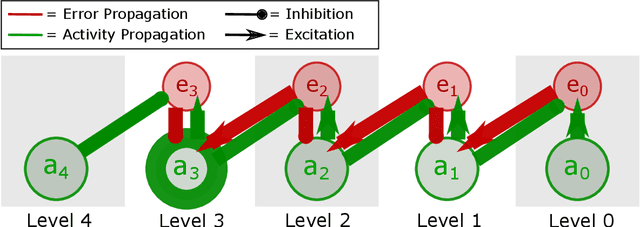

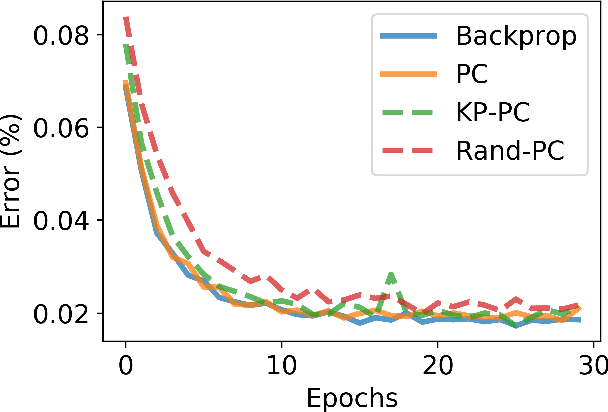
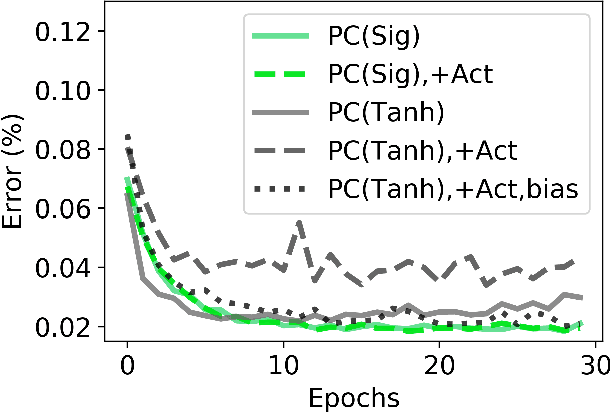
Predictive coding (PC) is a general theory of cortical function. The local, gradient-based learning rules found in one kind of PC model have recently been shown to closely approximate backpropagation. This finding suggests that this gradient-based PC model may be useful for understanding how the brain solves the credit assignment problem. The model may also be useful for developing local learning algorithms that are compatible with neuromorphic hardware. In this paper, we modify this PC model so that it better fits biological constraints, including the constraints that neurons can only have positive firing rates and the constraint that synapses only flow in one direction. We also compute the gradient-based weight and activity updates given the modified activity values. We show that, under certain conditions, these modified PC networks perform as well or nearly as well on MNIST data as the unmodified PC model and networks trained with backpropagation.