 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sparse Quantized Hopfield Network for Online-Continual Memory
Jul 27, 2023An important difference between brains and deep neural networks is the way they learn. Nervous systems learn online where a stream of noisy data points are presented in a non-independent, identically distributed (non-i.i.d.) way. Further, synaptic plasticity in the brain depends only on information local to synapses. Deep networks, on the other hand, typically use non-local learning algorithms and are trained in an offline, non-noisy, i.i.d. setting. Understanding how neural networks learn under the same constraints as the brain is an open problem for neuroscience and neuromorphic computing. A standard approach to this problem has yet to be established. In this paper, we propose that discrete graphical models that learn via an online maximum a posteriori learning algorithm could provide such an approach. We implement this kind of model in a novel neural network called the Sparse Quantized Hopfield Network (SQHN). We show that SQHNs outperform state-of-the-art neural networks on associative memory tasks, outperform these models in online, non-i.i.d. settings, learn efficiently with noisy inputs, and are better than baselines on a novel episodic memory task.
Understanding and Improving Optimization in Predictive Coding Networks
May 23, 2023
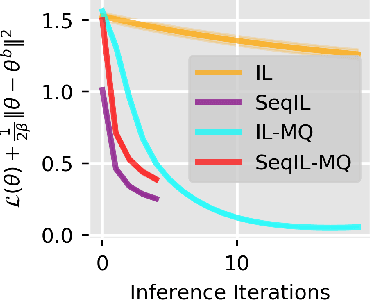
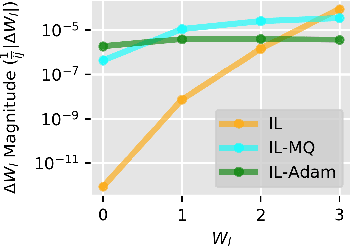

Backpropagation (BP), the standard learning algorithm for artificial neural networks, is often considered biologically implausible. In contrast, the standard learning algorithm for predictive coding (PC) models in neuroscience, known as the inference learning algorithm (IL), is a promising, bio-plausible alternative. However, several challenges and questions hinder IL's application to real-world problems. For example, IL is computationally demanding, and without memory-intensive optimizers like Adam, IL may converge to poor local minima. Moreover, although IL can reduce loss more quickly than BP, the reasons for these speedups or their robustness remains unclear. In this paper, we tackle these challenges by 1) altering the standard implementation of PC circuits to substantially reduce computation, 2) developing a novel optimizer that improves the convergence of IL without increasing memory usage, and 3) establishing theoretical results that help elucidate the conditions under which IL is sensitive to second and higher-order information.
A Theoretical Framework for Inference Learning
Jun 01, 2022
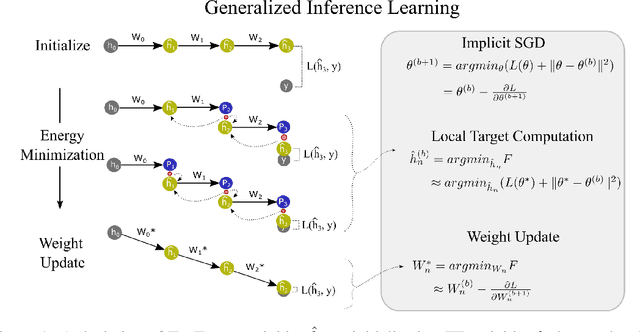
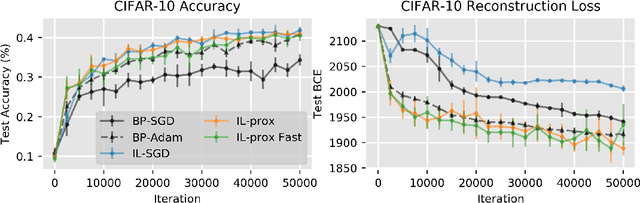
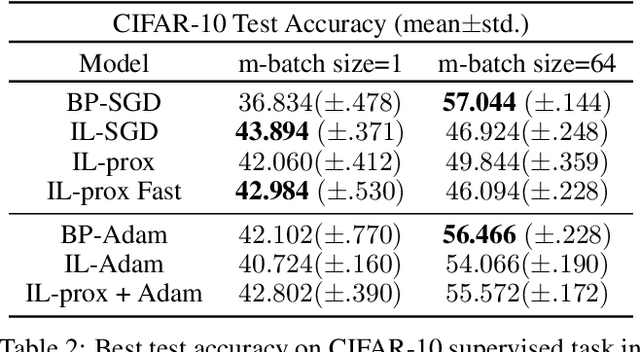
Backpropagation (BP) is the most successful and widely used algorithm in deep learning. However, the computations required by BP are challenging to reconcile with known neurobiology. This difficulty has stimulated interest in more biologically plausible alternatives to BP. One such algorithm is the inference learning algorithm (IL). IL has close connections to neurobiological models of cortical function and has achieved equal performance to BP on supervised learning and auto-associative tasks. In contrast to BP, however, the mathematical foundations of IL are not well-understood. Here, we develop a novel theoretical framework for IL. Our main result is that IL closely approximates an optimization method known as implicit stochastic gradient descent (implicit SGD), which is distinct from the explicit SGD implemented by BP. Our results further show how the standard implementation of IL can be altered to better approximate implicit SGD. Our novel implementation considerably improves the stability of IL across learning rates, which is consistent with our theory, as a key property of implicit SGD is its stability. We provide extensive simulation results that further support our theoretical interpretations and also demonstrate IL achieves quicker convergence when trained with small mini-batches while matching the performance of BP for large mini-batches.
A Framework to Explore Workload-Specific Performance and Lifetime Trade-offs in Neuromorphic Computing
Nov 01, 2019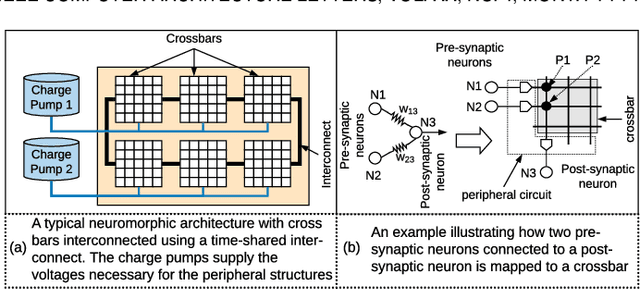
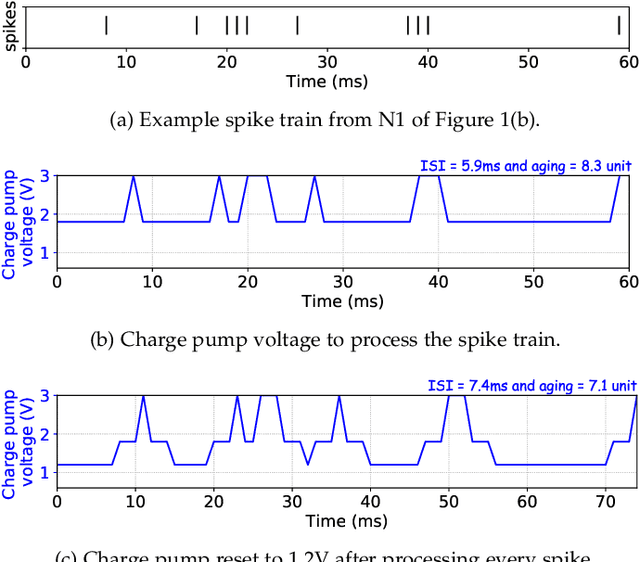
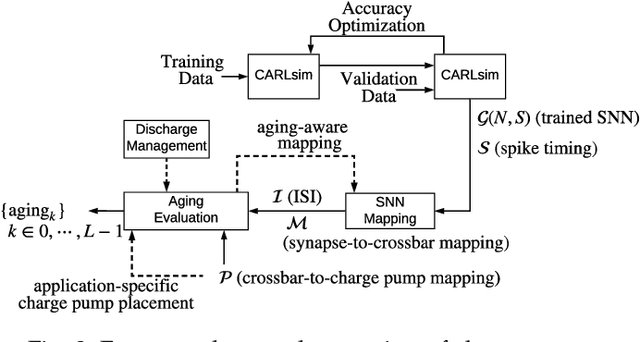
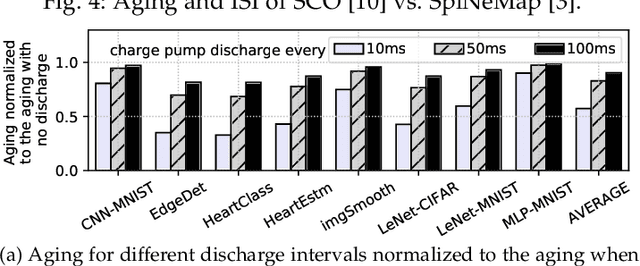
Neuromorphic hardware with non-volatile memory (NVM) can implement machine learning workload in an energy-efficient manner. Unfortunately, certain NVMs such as phase change memory (PCM) require high voltages for correct operation. These voltages are supplied from an on-chip charge pump. If the charge pump is activated too frequently, its internal CMOS devices do not recover from stress, accelerating their aging and leading to negative bias temperature instability (NBTI) generated defects. Forcefully discharging the stressed charge pump can lower the aging rate of its CMOS devices, but makes the neuromorphic hardware unavailable to perform computations while its charge pump is being discharged. This negatively impacts performance such as latency and accuracy of the machine learning workload being executed. In this paper, we propose a novel framework to exploit workload-specific performance and lifetime trade-offs in neuromorphic computing. Our framework first extracts the precise times at which a charge pump in the hardware is activated to support neural computations within a workload. This timing information is then used with a characterized NBTI reliability model to estimate the charge pump's aging during the workload execution. We use our framework to evaluate workload-specific performance and reliability impacts of using 1) different SNN mapping strategies and 2) different charge pump discharge strategies. We show that our framework can be used by system designers to explore performance and reliability trade-offs early in the design of neuromorphic hardware such that appropriate reliability-oriented design margins can be set.