 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociative Memories in the Feature Space
Paper and Code
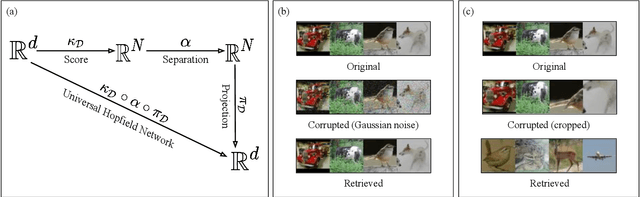
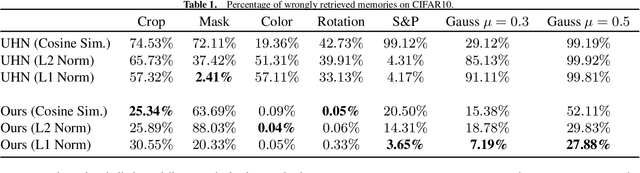
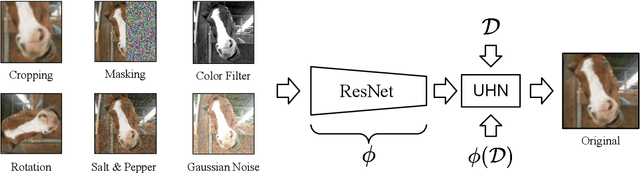
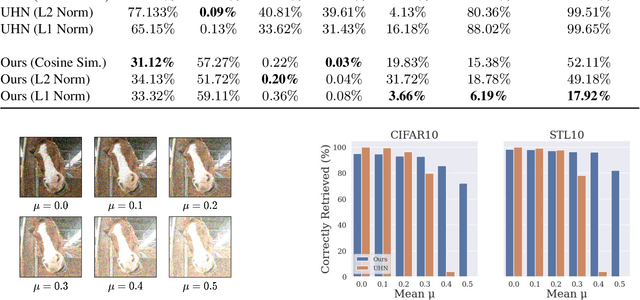
An autoassociative memory model is a function that, given a set of data points, takes as input an arbitrary vector and outputs the most similar data point from the memorized set. However, popular memory models fail to retrieve images even when the corruption is mild and easy to detect for a human evaluator. This is because similarities are evaluated in the raw pixel space, which does not contain any semantic information about the images. This problem can be easily solved by computing \emph{similarities} in an embedding space instead of the pixel space. We show that an effective way of computing such embeddings is via a network pretrained with a contrastive loss. As the dimension of embedding spaces is often significantly smaller than the pixel space, we also have a faster computation of similarity scores. We test this method on complex datasets such as CIFAR10 and STL10. An additional drawback of current models is the need of storing the whole dataset in the pixel space, which is often extremely large. We relax this condition and propose a class of memory models that only stores low-dimensional semantic embeddings, and uses them to retrieve similar, but not identical, memories. We demonstrate a proof of concept of this method on a simple task on the MNIST dataset.