 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Minimizing Feature Drift in Model Merging: Layer-wise Task Vector Fusion for Adaptive Knowledge Integration
May 29, 2025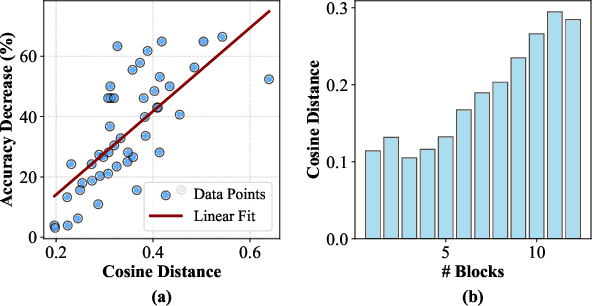
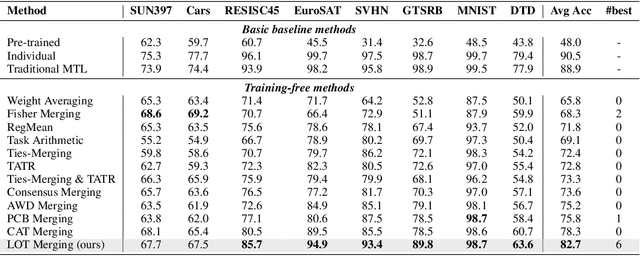
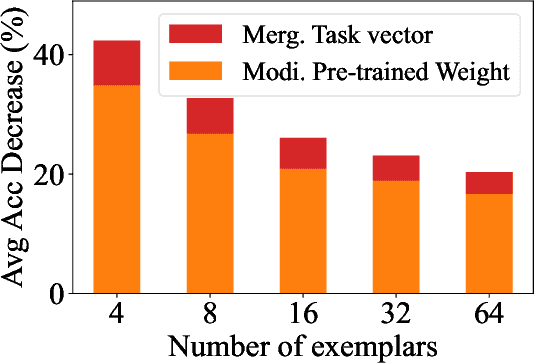
Multi-task model merging aims to consolidate knowledge from multiple fine-tuned task-specific experts into a unified model while minimizing performance degradation. Existing methods primarily approach this by minimizing differences between task-specific experts and the unified model, either from a parameter-level or a task-loss perspective. However, parameter-level methods exhibit a significant performance gap compared to the upper bound, while task-loss approaches entail costly secondary training procedures. In contrast, we observe that performance degradation closely correlates with feature drift, i.e., differences in feature representations of the same sample caused by model merging. Motivated by this observation, we propose Layer-wise Optimal Task Vector Merging (LOT Merging), a technique that explicitly minimizes feature drift between task-specific experts and the unified model in a layer-by-layer manner. LOT Merging can be formulated as a convex quadratic optimization problem, enabling us to analytically derive closed-form solutions for the parameters of linear and normalization layers. Consequently, LOT Merging achieves efficient model consolidation through basic matrix operations. Extensive experiments across vision and vision-language benchmarks demonstrate that LOT Merging significantly outperforms baseline methods, achieving improvements of up to 4.4% (ViT-B/32) over state-of-the-art approaches.
CAT Merging: A Training-Free Approach for Resolving Conflicts in Model Merging
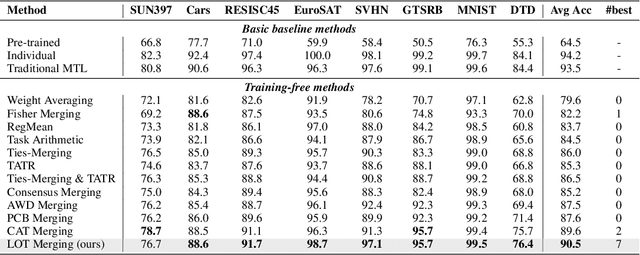
May 14, 2025Multi-task model merging offers a promising paradigm for integrating multiple expert models into a unified model without additional training. Existing state-of-the-art techniques, such as Task Arithmetic and its variants, merge models by accumulating task vectors -- the parameter differences between pretrained and finetuned models. However, task vector accumulation is often hindered by knowledge conflicts, leading to performance degradation. To address this challenge, we propose Conflict-Aware Task Merging (CAT Merging), a novel training-free framework that selectively trims conflict-prone components from the task vectors. CAT Merging introduces several parameter-specific strategies, including projection for linear weights and masking for scaling and shifting parameters in normalization layers. Extensive experiments on vision, language, and vision-language tasks demonstrate that CAT Merging effectively suppresses knowledge conflicts, achieving average accuracy improvements of up to 2.5% (ViT-B/32) and 2.0% (ViT-L/14) over state-of-the-art methods.
Task Arithmetic in Trust Region: A Training-Free Model Merging Approach to Navigate Knowledge Conflicts
Jan 25, 2025



Multi-task model merging offers an efficient solution for integrating knowledge from multiple fine-tuned models, mitigating the significant computational and storage demands associated with multi-task training. As a key technique in this field, Task Arithmetic (TA) defines task vectors by subtracting the pre-trained model ($\theta_{\text{pre}}$) from the fine-tuned task models in parameter space, then adjusting the weight between these task vectors and $\theta_{\text{pre}}$ to balance task-generalized and task-specific knowledge. Despite the promising performance of TA, conflicts can arise among the task vectors, particularly when different tasks require distinct model adaptations. In this paper, we formally define this issue as knowledge conflicts, characterized by the performance degradation of one task after merging with a model fine-tuned for another task. Through in-depth analysis, we show that these conflicts stem primarily from the components of task vectors that align with the gradient of task-specific losses at $\theta_{\text{pre}}$. To address this, we propose Task Arithmetic in Trust Region (TATR), which defines the trust region as dimensions in the model parameter space that cause only small changes (corresponding to the task vector components with gradient orthogonal direction) in the task-specific losses. Restricting parameter merging within this trust region, TATR can effectively alleviate knowledge conflicts. Moreover, TATR serves as both an independent approach and a plug-and-play module compatible with a wide range of TA-based methods. Extensive empirical evaluations on eight distinct datasets robustly demonstrate that TATR improves the multi-task performance of several TA-based model merging methods by an observable margin.
CLAP: Learning Transferable Binary Code Representations with Natural Language Supervision
Feb 26, 2024Binary code representation learning has shown significant performance in binary analysis tasks. But existing solutions often have poor transferability, particularly in few-shot and zero-shot scenarios where few or no training samples are available for the tasks. To address this problem, we present CLAP (Contrastive Language-Assembly Pre-training), which employs natural language supervision to learn better representations of binary code (i.e., assembly code) and get better transferability. At the core, our approach boosts superior transfer learning capabilities by effectively aligning binary code with their semantics explanations (in natural language), resulting a model able to generate better embeddings for binary code. To enable this alignment training, we then propose an efficient dataset engine that could automatically generate a large and diverse dataset comprising of binary code and corresponding natural language explanations. We have generated 195 million pairs of binary code and explanations and trained a prototype of CLAP. The evaluations of CLAP across various downstream tasks in binary analysis all demonstrate exceptional performance. Notably, without any task-specific training, CLAP is often competitive with a fully supervised baseline, showing excellent transferability. We release our pre-trained model and code at https://github.com/Hustcw/CLAP.
Towards Plastic and Stable Exemplar-Free Incremental Learning: A Dual-Learner Framework with Cumulative Parameter Averaging
Oct 28, 2023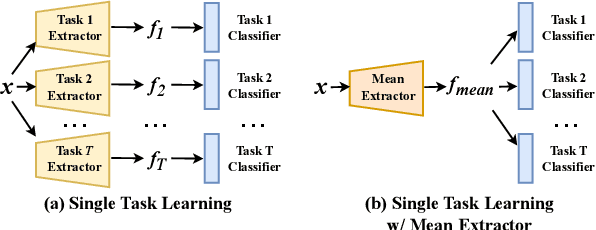

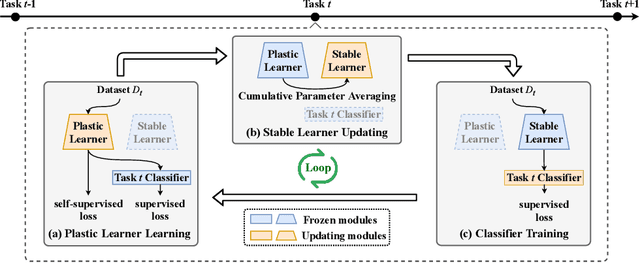
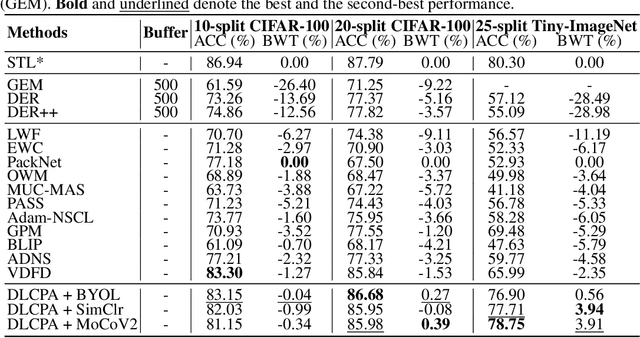
The dilemma between plasticity and stability presents a significant challenge in Incremental Learning (IL), especially in the exemplar-free scenario where accessing old-task samples is strictly prohibited during the learning of a new task. A straightforward solution to this issue is learning and storing an independent model for each task, known as Single Task Learning (STL). Despite the linear growth in model storage with the number of tasks in STL, we empirically discover that averaging these model parameters can potentially preserve knowledge across all tasks. Inspired by this observation, we propose a Dual-Learner framework with Cumulative Parameter Averaging (DLCPA). DLCPA employs a dual-learner design: a plastic learner focused on acquiring new-task knowledge and a stable learner responsible for accumulating all learned knowledge. The knowledge from the plastic learner is transferred to the stable learner via cumulative parameter averaging. Additionally, several task-specific classifiers work in cooperation with the stable learner to yield the final prediction. Specifically, when learning a new task, these modules are updated in a cyclic manner: i) the plastic learner is initially optimized using a self-supervised loss besides the supervised loss to enhance the feature extraction robustness; ii) the stable learner is then updated with respect to the plastic learner in a cumulative parameter averaging manner to maintain its task-wise generalization; iii) the task-specific classifier is accordingly optimized to align with the stable learner. Experimental results on CIFAR-100 and Tiny-ImageNet show that DLCPA outperforms several state-of-the-art exemplar-free baselines in both Task-IL and Class-IL settings.
Exemplar-free Class Incremental Learning via Discriminative and Comparable One-class Classifiers
Jan 05, 2022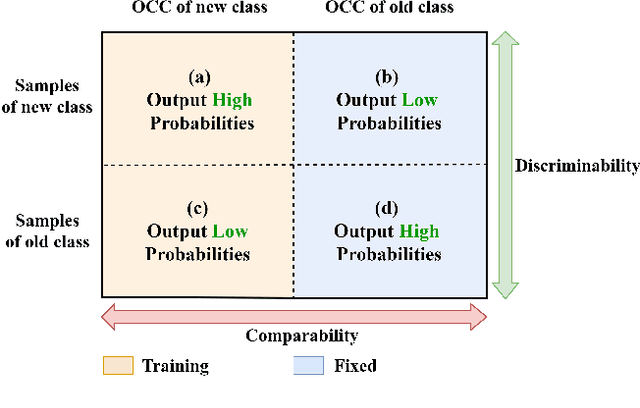
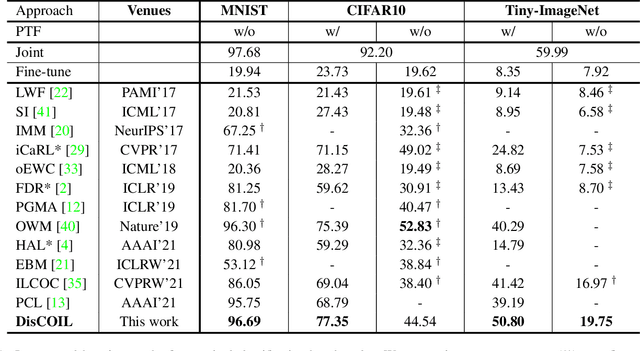
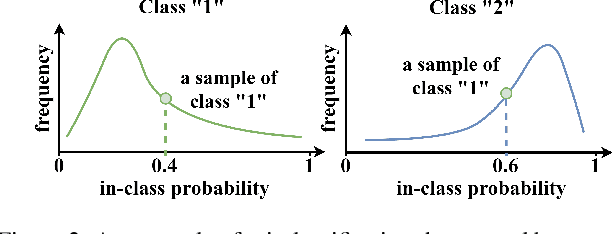
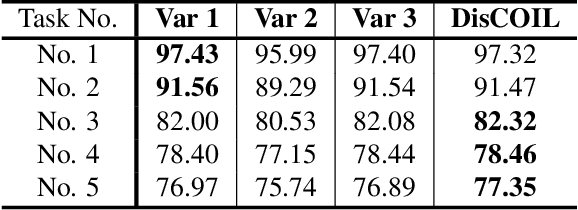
The exemplar-free class incremental learning requires classification models to learn new class knowledge incrementally without retaining any old samples. Recently, the framework based on parallel one-class classifiers (POC), which trains a one-class classifier (OCC) independently for each category, has attracted extensive attention, since it can naturally avoid catastrophic forgetting. POC, however, suffers from weak discriminability and comparability due to its independent training strategy for different OOCs. To meet this challenge, we propose a new framework, named Discriminative and Comparable One-class classifiers for Incremental Learning (DisCOIL). DisCOIL follows the basic principle of POC, but it adopts variational auto-encoders (VAE) instead of other well-established one-class classifiers (e.g. deep SVDD), because a trained VAE can not only identify the probability of an input sample belonging to a class but also generate pseudo samples of the class to assist in learning new tasks. With this advantage, DisCOIL trains a new-class VAE in contrast with the old-class VAEs, which forces the new-class VAE to reconstruct better for new-class samples but worse for the old-class pseudo samples, thus enhancing the comparability. Furthermore, DisCOIL introduces a hinge reconstruction loss to ensure the discriminability. We evaluate our method extensively on MNIST, CIFAR10, and Tiny-ImageNet. The experimental results show that DisCOIL achieves state-of-the-art performance.