 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition of Daily Activities through Multi-Modal Deep Learning: A Video, Pose, and Object-Aware Approach for Ambient Assisted Living
Mar 04, 2026Recognition of daily activities is a critical element for effective Ambient Assisted Living (AAL) systems, particularly to monitor the well-being and support the independence of older adults in indoor environments. However, developing robust activity recognition systems faces significant challenges, including intra-class variability, inter-class similarity, environmental variability, camera perspectives, and scene complexity. This paper presents a multi-modal approach for the recognition of activities of daily living tailored for older adults within AAL settings. The proposed system integrates visual information processed by a 3D Convolutional Neural Network (CNN) with 3D human pose data analyzed by a Graph Convolutional Network. Contextual information, derived from an object detection module, is fused with the 3D CNN features using a cross-attention mechanism to enhance recognition accuracy. This method is evaluated using the Toyota SmartHome dataset, which consists of real-world indoor activities. The results indicate that the proposed system achieves competitive classification accuracy for a range of daily activities, highlighting its potential as an essential component for advanced AAL monitoring solutions. This advancement supports the broader goal of developing intelligent systems that promote safety and autonomy among older adults.
Weakly Supervised Human Skin Segmentation using Guidance Attention Mechanisms
Feb 09, 2023Human skin segmentation is a crucial task in computer vision and biometric systems, yet it poses several challenges such as variability in skin color, pose, and illumination. This paper presents a robust data-driven skin segmentation method for a single image that addresses these challenges through the integration of contextual information and efficient network design. In addition to robustness and accuracy, the integration into real-time systems requires a careful balance between computational power, speed, and performance. The proposed method incorporates two attention modules, Body Attention and Skin Attention, that utilize contextual information to improve segmentation results. These modules draw attention to the desired areas, focusing on the body boundaries and skin pixels, respectively. Additionally, an efficient network architecture is employed in the encoder part to minimize computational power while retaining high performance. To handle the issue of noisy labels in skin datasets, the proposed method uses a weakly supervised training strategy, relying on the Skin Attention module. The results of this study demonstrate that the proposed method is comparable to, or outperforms, state-of-the-art methods on benchmark datasets.
Deep Learning meets Liveness Detection: Recent Advancements and Challenges
Dec 29, 2021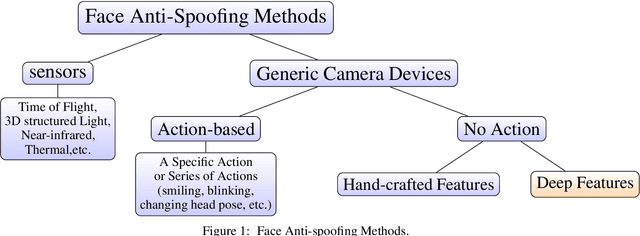
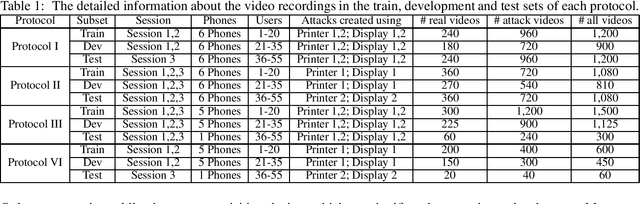
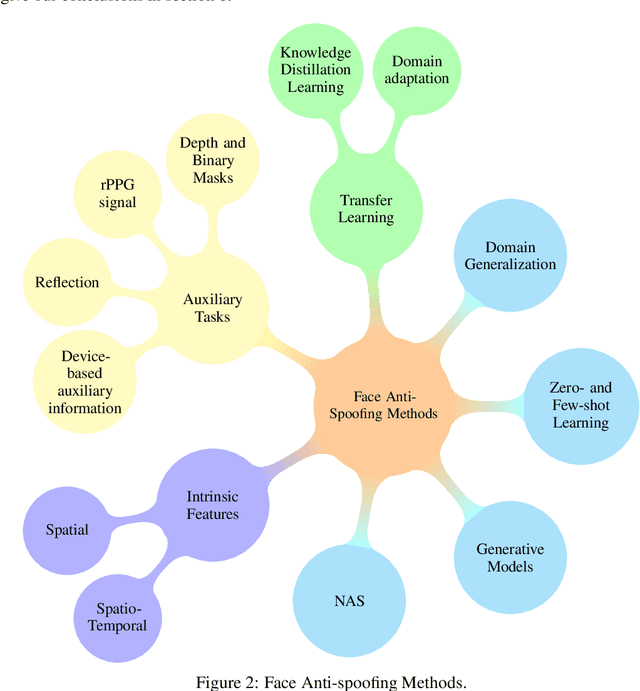
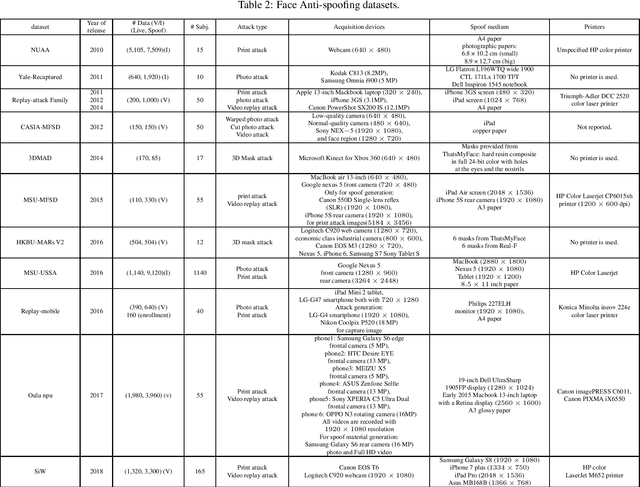
Facial biometrics has been recently received tremendous attention as a convenient replacement for traditional authentication systems. Consequently, detecting malicious attempts has found great significance, leading to extensive studies in face anti-spoofing~(FAS),i.e., face presentation attack detection. Deep feature learning and techniques, as opposed to hand-crafted features, have promised a dramatic increase in the FAS systems' accuracy, tackling the key challenges of materializing the real-world application of such systems. Hence, a new research area dealing with the development of more generalized as well as accurate models is increasingly attracting the attention of the research community and industry. In this paper, we present a comprehensive survey on the literature related to deep-feature-based FAS methods since 2017. To shed light on this topic, a semantic taxonomy based on various features and learning methodologies is represented. Further, we cover predominant public datasets for FAS in chronological order, their evolutional progress, and the evaluation criteria (both intra-dataset and inter-dataset). Finally, we discuss the open research challenges and future directions.
Advances and Challenges in Deep Lip Reading
Oct 15, 2021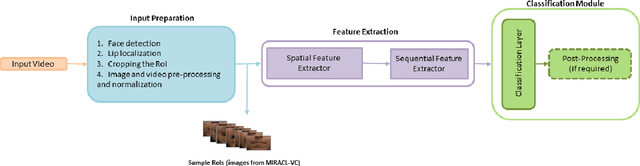
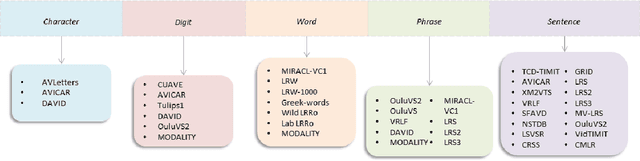
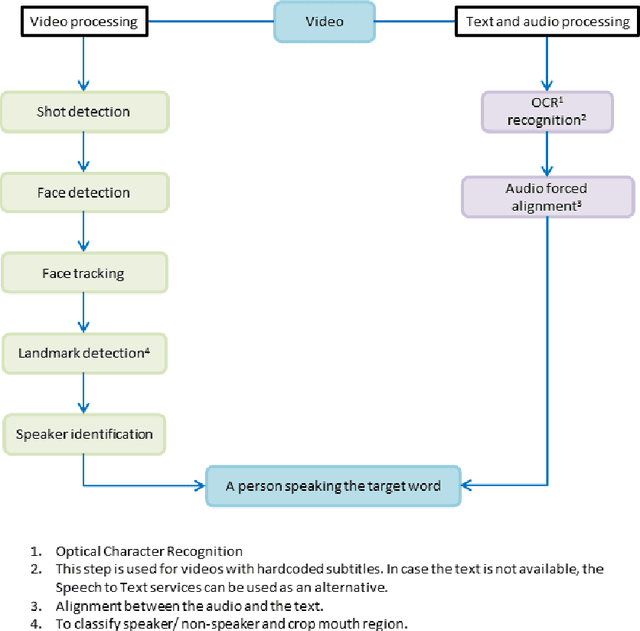
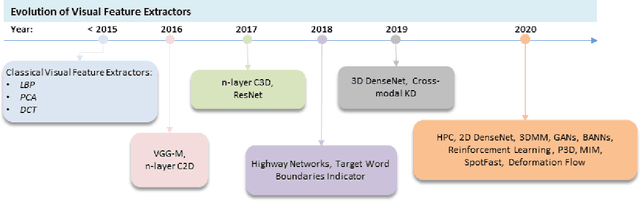
Driven by deep learning techniques and large-scale datasets, recent years have witnessed a paradigm shift in automatic lip reading. While the main thrust of Visual Speech Recognition (VSR) was improving accuracy of Audio Speech Recognition systems, other potential applications, such as biometric identification, and the promised gains of VSR systems, have motivated extensive efforts on developing the lip reading technology. This paper provides a comprehensive survey of the state-of-the-art deep learning based VSR research with a focus on data challenges, task-specific complications, and the corresponding solutions. Advancements in these directions will expedite the transformation of silent speech interface from theory to practice. We also discuss the main modules of a VSR pipeline and the influential datasets. Finally, we introduce some typical VSR application concerns and impediments to real-world scenarios as well as future research directions.