 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Challenges in Deep Lip Reading
Paper and Code
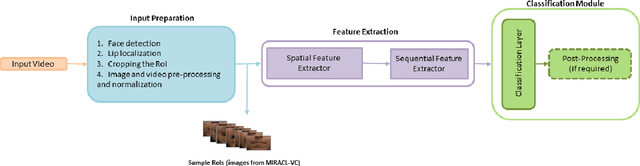
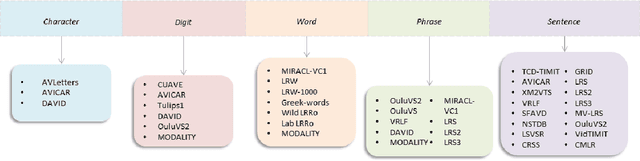
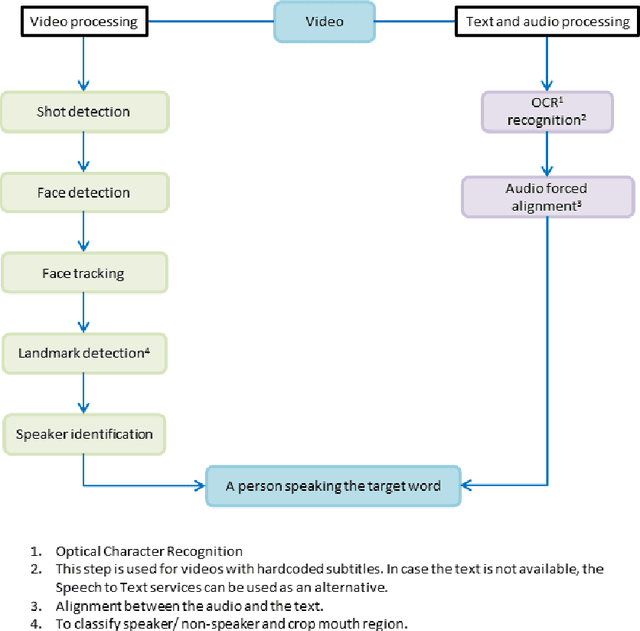
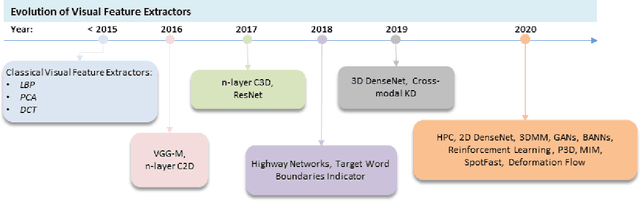
Driven by deep learning techniques and large-scale datasets, recent years have witnessed a paradigm shift in automatic lip reading. While the main thrust of Visual Speech Recognition (VSR) was improving accuracy of Audio Speech Recognition systems, other potential applications, such as biometric identification, and the promised gains of VSR systems, have motivated extensive efforts on developing the lip reading technology. This paper provides a comprehensive survey of the state-of-the-art deep learning based VSR research with a focus on data challenges, task-specific complications, and the corresponding solutions. Advancements in these directions will expedite the transformation of silent speech interface from theory to practice. We also discuss the main modules of a VSR pipeline and the influential datasets. Finally, we introduce some typical VSR application concerns and impediments to real-world scenarios as well as future research directions.