 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFIQA: Explainable Fundus Image Quality Assessment via Anatomical Priors
Jun 18, 2026Image quality control is vital for a wide range of downstream applications. Deep learning-based image quality assessment methods typically train classifiers on dataset-specific quality labels, inheriting two limitations: (1) generalization is tied to the labeling criteria of the training set and (2) these methods cannot provide spatial feedback on where the quality is degraded, lacking explainability. In this work, we propose EFIQA, a framework that requires no quality-related supervision and produces spatial quality maps by design. Rather than learning ``what is degradation" from human-annotated labels, EFIQA learns ``what should be there" by leveraging anatomical priors. For fundus photography, we instantiate this as a two-stage approach, by first training an unsupervised anomaly detector via masked anatomical inpainting to identify regions of missing vasculature, and then distilling this prior knowledge into a shallow adapter mapping features of a frozen foundation model to precise quality maps. External-dataset evaluation demonstrates that this label-free approach with minimal adaptation achieves better performance and explainability compared with supervised methods across benchmarks with different quality criteria, highlighting its potential for real-world applications.
* Accepted in MIDL 2026. Code: https://github.com/penway/EFIQA
MIRAGE: Multimodal foundation model and benchmark for comprehensive retinal OCT image analysis
Jun 11, 2025Artificial intelligence (AI) has become a fundamental tool for assisting clinicians in analyzing ophthalmic images, such as optical coherence tomography (OCT). However, developing AI models often requires extensive annotation, and existing models tend to underperform on independent, unseen data. Foundation models (FMs), large AI models trained on vast unlabeled datasets, have shown promise in overcoming these challenges. Nonetheless, available FMs for ophthalmology lack extensive validation, especially for segmentation tasks, and focus on a single imaging modality. In this context, we propose MIRAGE, a novel multimodal FM for the analysis of OCT and scanning laser ophthalmoscopy (SLO) images. Additionally, we propose a new evaluation benchmark with OCT/SLO classification and segmentation tasks. The comparison with general and specialized FMs and segmentation methods shows the superiority of MIRAGE in both types of tasks, highlighting its suitability as a basis for the development of robust AI systems for retinal OCT image analysis. Both MIRAGE and the evaluation benchmark are publicly available: https://github.com/j-morano/MIRAGE.
RRWNet: Recursive Refinement Network for Effective Retinal Artery/Vein Segmentation and Classification
Feb 05, 2024



The caliber and configuration of retinal blood vessels serve as important biomarkers for various diseases and medical conditions. A thorough analysis of the retinal vasculature requires the segmentation of blood vessels and their classification into arteries and veins, which is typically performed on color fundus images obtained by retinography, a widely used imaging technique. Nonetheless, manually performing these tasks is labor-intensive and prone to human error. Various automated methods have been proposed to address this problem. However, the current state of art in artery/vein segmentation and classification faces challenges due to manifest classification errors that affect the topological consistency of segmentation maps. This study presents an innovative end-to-end framework, RRWNet, designed to recursively refine semantic segmentation maps and correct manifest classification errors. The framework consists of a fully convolutional neural network with a Base subnetwork that generates base segmentation maps from input images, and a Recursive Refinement subnetwork that iteratively and recursively improves these maps. Evaluation on public datasets demonstrates the state-of-the-art performance of the proposed method, yielding more topologically consistent segmentation maps with fewer manifest classification errors than existing approaches. In addition, the Recursive Refinement module proves effective in post-processing segmentation maps from other methods, automatically correcting classification errors and improving topological consistency. The model code, weights, and predictions are publicly available at https://github.com/j-morano/rrwnet.
Deep Multimodal Fusion of Data with Heterogeneous Dimensionality via Projective Networks
Feb 02, 2024



The use of multimodal imaging has led to significant improvements in the diagnosis and treatment of many diseases. Similar to clinical practice, some works have demonstrated the benefits of multimodal fusion for automatic segmentation and classification using deep learning-based methods. However, current segmentation methods are limited to fusion of modalities with the same dimensionality (e.g., 3D+3D, 2D+2D), which is not always possible, and the fusion strategies implemented by classification methods are incompatible with localization tasks. In this work, we propose a novel deep learning-based framework for the fusion of multimodal data with heterogeneous dimensionality (e.g., 3D+2D) that is compatible with localization tasks. The proposed framework extracts the features of the different modalities and projects them into the common feature subspace. The projected features are then fused and further processed to obtain the final prediction. The framework was validated on the following tasks: segmentation of geographic atrophy (GA), a late-stage manifestation of age-related macular degeneration, and segmentation of retinal blood vessels (RBV) in multimodal retinal imaging. Our results show that the proposed method outperforms the state-of-the-art monomodal methods on GA and RBV segmentation by up to 3.10% and 4.64% Dice, respectively.
SAMedOCT: Adapting Segment Anything Model (SAM) for Retinal OCT
Aug 31, 2023The Segment Anything Model (SAM) has gained significant attention in the field of image segmentation due to its impressive capabilities and prompt-based interface. While SAM has already been extensively evaluated in various domains, its adaptation to retinal OCT scans remains unexplored. To bridge this research gap, we conduct a comprehensive evaluation of SAM and its adaptations on a large-scale public dataset of OCTs from RETOUCH challenge. Our evaluation covers diverse retinal diseases, fluid compartments, and device vendors, comparing SAM against state-of-the-art retinal fluid segmentation methods. Through our analysis, we showcase adapted SAM's efficacy as a powerful segmentation model in retinal OCT scans, although still lagging behind established methods in some circumstances. The findings highlight SAM's adaptability and robustness, showcasing its utility as a valuable tool in retinal OCT image analysis and paving the way for further advancements in this domain.
Self-supervised learning via inter-modal reconstruction and feature projection networks for label-efficient 3D-to-2D segmentation
Jul 13, 2023Deep learning has become a valuable tool for the automation of certain medical image segmentation tasks, significantly relieving the workload of medical specialists. Some of these tasks require segmentation to be performed on a subset of the input dimensions, the most common case being 3D-to-2D. However, the performance of existing methods is strongly conditioned by the amount of labeled data available, as there is currently no data efficient method, e.g. transfer learning, that has been validated on these tasks. In this work, we propose a novel convolutional neural network (CNN) and self-supervised learning (SSL) method for label-efficient 3D-to-2D segmentation. The CNN is composed of a 3D encoder and a 2D decoder connected by novel 3D-to-2D blocks. The SSL method consists of reconstructing image pairs of modalities with different dimensionality. The approach has been validated in two tasks with clinical relevance: the en-face segmentation of geographic atrophy and reticular pseudodrusen in optical coherence tomography. Results on different datasets demonstrate that the proposed CNN significantly improves the state of the art in scenarios with limited labeled data by up to 8% in Dice score. Moreover, the proposed SSL method allows further improvement of this performance by up to 23%, and we show that the SSL is beneficial regardless of the network architecture.
Weakly-supervised detection of AMD-related lesions in color fundus images using explainable deep learning
Dec 04, 2022Age-related macular degeneration (AMD) is a degenerative disorder affecting the macula, a key area of the retina for visual acuity. Nowadays, it is the most frequent cause of blindness in developed countries. Although some promising treatments have been developed, their effectiveness is low in advanced stages. This emphasizes the importance of large-scale screening programs. Nevertheless, implementing such programs for AMD is usually unfeasible, since the population at risk is large and the diagnosis is challenging. All this motivates the development of automatic methods. In this sense, several works have achieved positive results for AMD diagnosis using convolutional neural networks (CNNs). However, none incorporates explainability mechanisms, which limits their use in clinical practice. In that regard, we propose an explainable deep learning approach for the diagnosis of AMD via the joint identification of its associated retinal lesions. In our proposal, a CNN is trained end-to-end for the joint task using image-level labels. The provided lesion information is of clinical interest, as it allows to assess the developmental stage of AMD. Additionally, the approach allows to explain the diagnosis from the identified lesions. This is possible thanks to the use of a CNN with a custom setting that links the lesions and the diagnosis. Furthermore, the proposed setting also allows to obtain coarse lesion segmentation maps in a weakly-supervised way, further improving the explainability. The training data for the approach can be obtained without much extra work by clinicians. The experiments conducted demonstrate that our approach can identify AMD and its associated lesions satisfactorily, while providing adequate coarse segmentation maps for most common lesions.
Simultaneous segmentation and classification of the retinal arteries and veins from color fundus images
Sep 20, 2022The study of the retinal vasculature is a fundamental stage in the screening and diagnosis of many diseases. A complete retinal vascular analysis requires to segment and classify the blood vessels of the retina into arteries and veins (A/V). Early automatic methods approached these segmentation and classification tasks in two sequential stages. However, currently, these tasks are approached as a joint semantic segmentation task, as the classification results highly depend on the effectiveness of the vessel segmentation. In that regard, we propose a novel approach for the simultaneous segmentation and classification of the retinal A/V from eye fundus images. In particular, we propose a novel method that, unlike previous approaches, and thanks to a novel loss, decomposes the joint task into three segmentation problems targeting arteries, veins and the whole vascular tree. This configuration allows to handle vessel crossings intuitively and directly provides accurate segmentation masks of the different target vascular trees. The provided ablation study on the public Retinal Images vessel Tree Extraction (RITE) dataset demonstrates that the proposed method provides a satisfactory performance, particularly in the segmentation of the different structures. Furthermore, the comparison with the state of the art shows that our method achieves highly competitive results in A/V classification, while significantly improving vascular segmentation. The proposed multi-segmentation method allows to detect more vessels and better segment the different structures, while achieving a competitive classification performance. Also, in these terms, our approach outperforms the approaches of various reference works. Moreover, in contrast with previous approaches, the proposed method allows to directly detect the vessel crossings, as well as preserving the continuity of A/V at these complex locations.
Improving AMD diagnosis by the simultaneous identification of associated retinal lesions
May 22, 2022Age-related Macular Degeneration (AMD) is the predominant cause of blindness in developed countries, specially in elderly people. Moreover, its prevalence is increasing due to the global population ageing. In this scenario, early detection is crucial to avert later vision impairment. Nonetheless, implementing large-scale screening programmes is usually not viable, since the population at-risk is large and the analysis must be performed by expert clinicians. Also, the diagnosis of AMD is considered to be particularly difficult, as it is characterized by many different lesions that, in many cases, resemble those of other macular diseases. To overcome these issues, several works have proposed automatic methods for the detection of AMD in retinography images, the most widely used modality for the screening of the disease. Nowadays, most of these works use Convolutional Neural Networks (CNNs) for the binary classification of images into AMD and non-AMD classes. In this work, we propose a novel approach based on CNNs that simultaneously performs AMD diagnosis and the classification of its potential lesions. This latter secondary task has not yet been addressed in this domain, and provides complementary useful information that improves the diagnosis performance and helps understanding the decision. A CNN model is trained using retinography images with image-level labels for both AMD and lesion presence, which are relatively easy to obtain. The experiments conducted in several public datasets show that the proposed approach improves the detection of AMD, while achieving satisfactory results in the identification of most lesions.
Multimodal Transfer Learning-based Approaches for Retinal Vascular Segmentation
Dec 18, 2020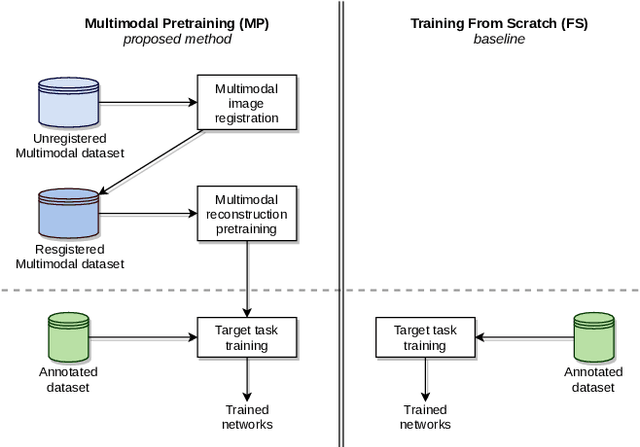
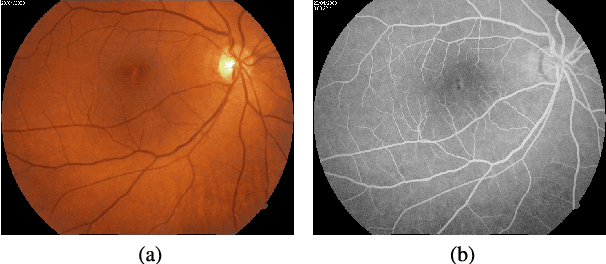
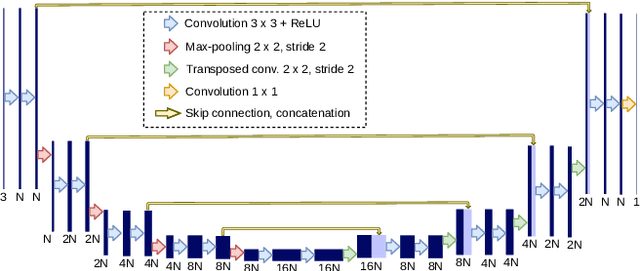
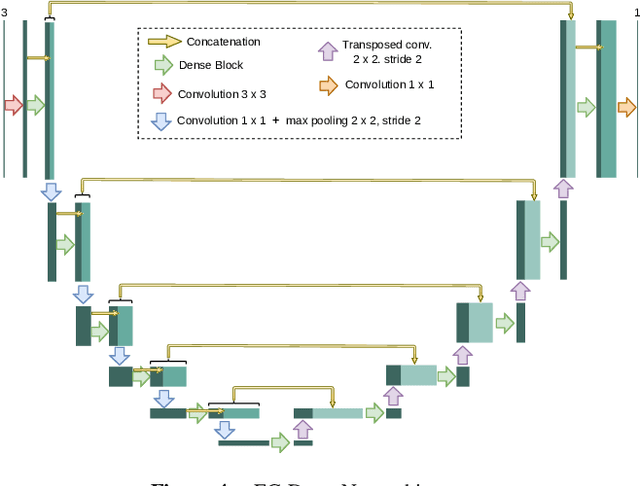
In ophthalmology, the study of the retinal microcirculation is a key issue in the analysis of many ocular and systemic diseases, like hypertension or diabetes. This motivates the research on improving the retinal vasculature segmentation. Nowadays, Fully Convolutional Neural Networks (FCNs) usually represent the most successful approach to image segmentation. However, the success of these models is conditioned by an adequate selection and adaptation of the architectures and techniques used, as well as the availability of a large amount of annotated data. These two issues become specially relevant when applying FCNs to medical image segmentation as, first, the existent models are usually adjusted from broad domain applications over photographic images, and second, the amount of annotated data is usually scarcer. In this work, we present multimodal transfer learning-based approaches for retinal vascular segmentation, performing a comparative study of recent FCN architectures. In particular, to overcome the annotated data scarcity, we propose the novel application of self-supervised network pretraining that takes advantage of existent unlabelled multimodal data. The results demonstrate that the self-supervised pretrained networks obtain significantly better vascular masks with less training in the target task, independently of the network architecture, and that some FCN architecture advances motivated for broad domain applications do not translate into significant improvements over the vasculature segmentation task.