 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised training of keypoint-agnostic descriptors for flexible retinal image registration
May 05, 2025



Current color fundus image registration approaches are limited, among other things, by the lack of labeled data, which is even more significant in the medical domain, motivating the use of unsupervised learning. Therefore, in this work, we develop a novel unsupervised descriptor learning method that does not rely on keypoint detection. This enables the resulting descriptor network to be agnostic to the keypoint detector used during the registration inference. To validate this approach, we perform an extensive and comprehensive comparison on the reference public retinal image registration dataset. Additionally, we test our method with multiple keypoint detectors of varied nature, even proposing some novel ones. Our results demonstrate that the proposed approach offers accurate registration, not incurring in any performance loss versus supervised methods. Additionally, it demonstrates accurate performance regardless of the keypoint detector used. Thus, this work represents a notable step towards leveraging unsupervised learning in the medical domain.
Unsupervised Deep Learning-based Keypoint Localization Estimating Descriptor Matching Performance
May 05, 2025



Retinal image registration, particularly for color fundus images, is a challenging yet essential task with diverse clinical applications. Existing registration methods for color fundus images typically rely on keypoints and descriptors for alignment; however, a significant limitation is their reliance on labeled data, which is particularly scarce in the medical domain. In this work, we present a novel unsupervised registration pipeline that entirely eliminates the need for labeled data. Our approach is based on the principle that locations with distinctive descriptors constitute reliable keypoints. This fully inverts the conventional state-of-the-art approach, conditioning the detector on the descriptor rather than the opposite. First, we propose an innovative descriptor learning method that operates without keypoint detection or any labels, generating descriptors for arbitrary locations in retinal images. Next, we introduce a novel, label-free keypoint detector network which works by estimating descriptor performance directly from the input image. We validate our method through a comprehensive evaluation on four hold-out datasets, demonstrating that our unsupervised descriptor outperforms state-of-the-art supervised descriptors and that our unsupervised detector significantly outperforms existing unsupervised detection methods. Finally, our full registration pipeline achieves performance comparable to the leading supervised methods, while not employing any labeled data. Additionally, the label-free nature and design of our method enable direct adaptation to other domains and modalities.
ConKeD++ -- Improving descriptor learning for retinal image registration: A comprehensive study of contrastive losses
Apr 25, 2024Self-supervised contrastive learning has emerged as one of the most successful deep learning paradigms. In this regard, it has seen extensive use in image registration and, more recently, in the particular field of medical image registration. In this work, we propose to test and extend and improve a state-of-the-art framework for color fundus image registration, ConKeD. Using the ConKeD framework we test multiple loss functions, adapting them to the framework and the application domain. Furthermore, we evaluate our models using the standarized benchmark dataset FIRE as well as several datasets that have never been used before for color fundus registration, for which we are releasing the pairing data as well as a standardized evaluation approach. Our work demonstrates state-of-the-art performance across all datasets and metrics demonstrating several advantages over current SOTA color fundus registration methods
ConKeD: Multiview contrastive descriptor learning for keypoint-based retinal image registration
Jan 11, 2024Retinal image registration is of utmost importance due to its wide applications in medical practice. In this context, we propose ConKeD, a novel deep learning approach to learn descriptors for retinal image registration. In contrast to current registration methods, our approach employs a novel multi-positive multi-negative contrastive learning strategy that enables the utilization of additional information from the available training samples. This makes it possible to learn high quality descriptors from limited training data. To train and evaluate ConKeD, we combine these descriptors with domain-specific keypoints, particularly blood vessel bifurcations and crossovers, that are detected using a deep neural network. Our experimental results demonstrate the benefits of the novel multi-positive multi-negative strategy, as it outperforms the widely used triplet loss technique (single-positive and single-negative) as well as the single-positive multi-negative alternative. Additionally, the combination of ConKeD with the domain-specific keypoints produces comparable results to the state-of-the-art methods for retinal image registration, while offering important advantages such as avoiding pre-processing, utilizing fewer training samples, and requiring fewer detected keypoints, among others. Therefore, ConKeD shows a promising potential towards facilitating the development and application of deep learning-based methods for retinal image registration.
Weakly-supervised detection of AMD-related lesions in color fundus images using explainable deep learning
Dec 04, 2022Age-related macular degeneration (AMD) is a degenerative disorder affecting the macula, a key area of the retina for visual acuity. Nowadays, it is the most frequent cause of blindness in developed countries. Although some promising treatments have been developed, their effectiveness is low in advanced stages. This emphasizes the importance of large-scale screening programs. Nevertheless, implementing such programs for AMD is usually unfeasible, since the population at risk is large and the diagnosis is challenging. All this motivates the development of automatic methods. In this sense, several works have achieved positive results for AMD diagnosis using convolutional neural networks (CNNs). However, none incorporates explainability mechanisms, which limits their use in clinical practice. In that regard, we propose an explainable deep learning approach for the diagnosis of AMD via the joint identification of its associated retinal lesions. In our proposal, a CNN is trained end-to-end for the joint task using image-level labels. The provided lesion information is of clinical interest, as it allows to assess the developmental stage of AMD. Additionally, the approach allows to explain the diagnosis from the identified lesions. This is possible thanks to the use of a CNN with a custom setting that links the lesions and the diagnosis. Furthermore, the proposed setting also allows to obtain coarse lesion segmentation maps in a weakly-supervised way, further improving the explainability. The training data for the approach can be obtained without much extra work by clinicians. The experiments conducted demonstrate that our approach can identify AMD and its associated lesions satisfactorily, while providing adequate coarse segmentation maps for most common lesions.
Simultaneous segmentation and classification of the retinal arteries and veins from color fundus images
Sep 20, 2022The study of the retinal vasculature is a fundamental stage in the screening and diagnosis of many diseases. A complete retinal vascular analysis requires to segment and classify the blood vessels of the retina into arteries and veins (A/V). Early automatic methods approached these segmentation and classification tasks in two sequential stages. However, currently, these tasks are approached as a joint semantic segmentation task, as the classification results highly depend on the effectiveness of the vessel segmentation. In that regard, we propose a novel approach for the simultaneous segmentation and classification of the retinal A/V from eye fundus images. In particular, we propose a novel method that, unlike previous approaches, and thanks to a novel loss, decomposes the joint task into three segmentation problems targeting arteries, veins and the whole vascular tree. This configuration allows to handle vessel crossings intuitively and directly provides accurate segmentation masks of the different target vascular trees. The provided ablation study on the public Retinal Images vessel Tree Extraction (RITE) dataset demonstrates that the proposed method provides a satisfactory performance, particularly in the segmentation of the different structures. Furthermore, the comparison with the state of the art shows that our method achieves highly competitive results in A/V classification, while significantly improving vascular segmentation. The proposed multi-segmentation method allows to detect more vessels and better segment the different structures, while achieving a competitive classification performance. Also, in these terms, our approach outperforms the approaches of various reference works. Moreover, in contrast with previous approaches, the proposed method allows to directly detect the vessel crossings, as well as preserving the continuity of A/V at these complex locations.
Improving AMD diagnosis by the simultaneous identification of associated retinal lesions
May 22, 2022Age-related Macular Degeneration (AMD) is the predominant cause of blindness in developed countries, specially in elderly people. Moreover, its prevalence is increasing due to the global population ageing. In this scenario, early detection is crucial to avert later vision impairment. Nonetheless, implementing large-scale screening programmes is usually not viable, since the population at-risk is large and the analysis must be performed by expert clinicians. Also, the diagnosis of AMD is considered to be particularly difficult, as it is characterized by many different lesions that, in many cases, resemble those of other macular diseases. To overcome these issues, several works have proposed automatic methods for the detection of AMD in retinography images, the most widely used modality for the screening of the disease. Nowadays, most of these works use Convolutional Neural Networks (CNNs) for the binary classification of images into AMD and non-AMD classes. In this work, we propose a novel approach based on CNNs that simultaneously performs AMD diagnosis and the classification of its potential lesions. This latter secondary task has not yet been addressed in this domain, and provides complementary useful information that improves the diagnosis performance and helps understanding the decision. A CNN model is trained using retinography images with image-level labels for both AMD and lesion presence, which are relatively easy to obtain. The experiments conducted in several public datasets show that the proposed approach improves the detection of AMD, while achieving satisfactory results in the identification of most lesions.
Multimodal Transfer Learning-based Approaches for Retinal Vascular Segmentation
Dec 18, 2020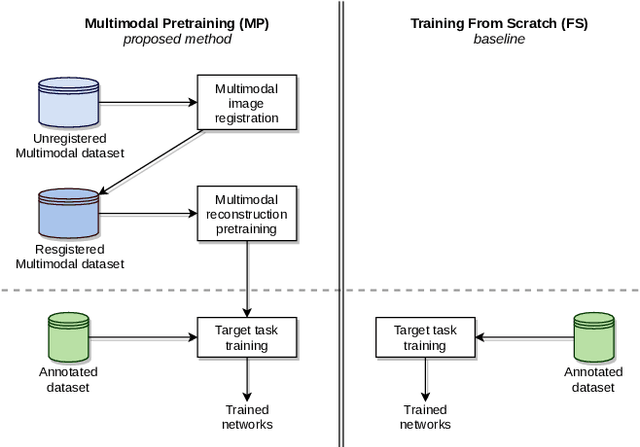
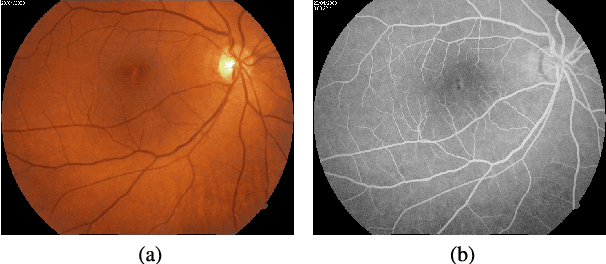
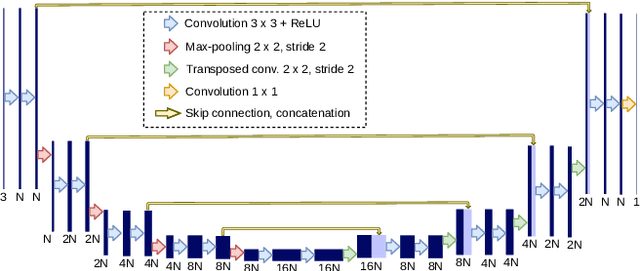
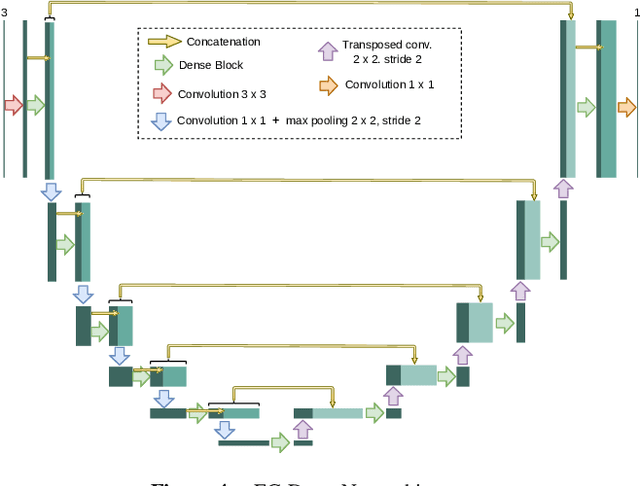
In ophthalmology, the study of the retinal microcirculation is a key issue in the analysis of many ocular and systemic diseases, like hypertension or diabetes. This motivates the research on improving the retinal vasculature segmentation. Nowadays, Fully Convolutional Neural Networks (FCNs) usually represent the most successful approach to image segmentation. However, the success of these models is conditioned by an adequate selection and adaptation of the architectures and techniques used, as well as the availability of a large amount of annotated data. These two issues become specially relevant when applying FCNs to medical image segmentation as, first, the existent models are usually adjusted from broad domain applications over photographic images, and second, the amount of annotated data is usually scarcer. In this work, we present multimodal transfer learning-based approaches for retinal vascular segmentation, performing a comparative study of recent FCN architectures. In particular, to overcome the annotated data scarcity, we propose the novel application of self-supervised network pretraining that takes advantage of existent unlabelled multimodal data. The results demonstrate that the self-supervised pretrained networks obtain significantly better vascular masks with less training in the target task, independently of the network architecture, and that some FCN architecture advances motivated for broad domain applications do not translate into significant improvements over the vasculature segmentation task.
Multi-stage transfer learning for lung segmentation using portable X-ray devices for patients with COVID-19
Oct 30, 2020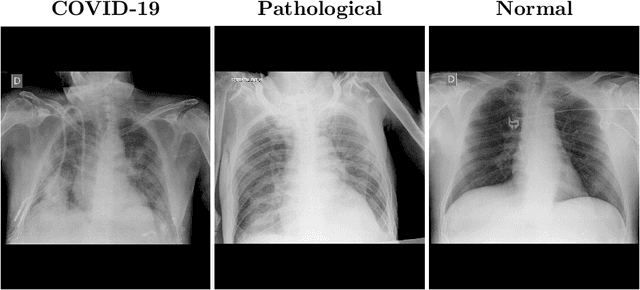
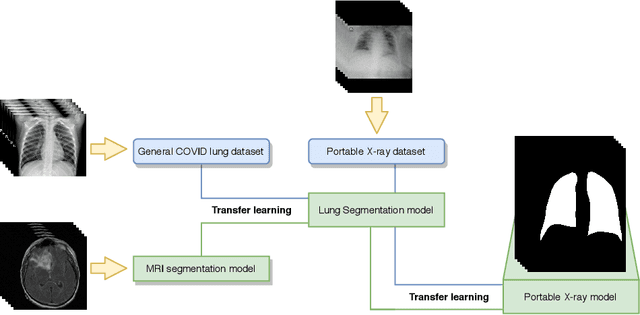

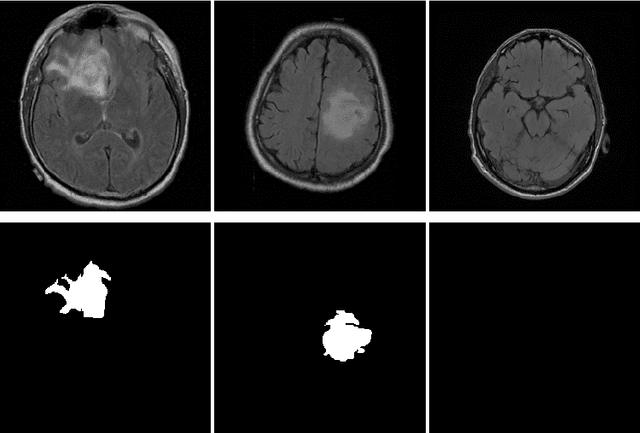
In 2020, the SARS-CoV-2 virus causes a global pandemic of the new human coronavirus disease COVID-19. This pathogen primarily infects the respiratory system of the afflicted, usually resulting in pneumonia and in a severe case of acute respiratory distress syndrome. These disease developments result in the formation of different pathological structures in the lungs, similar to those observed in other viral pneumonias that can be detected by the use of chest X-rays. For this reason, the detection and analysis of the pulmonary regions, the main focus of affection of COVID-19, becomes a crucial part of both clinical and automatic diagnosis processes. Due to the overload of the health services, portable X-ray devices are widely used, representing an alternative to fixed devices to reduce the risk of cross-contamination. However, these devices entail different complications as the image quality that, together with the subjectivity of the clinician, make the diagnostic process more difficult. In this work, we developed a novel fully automatic methodology specially designed for the identification of these lung regions in X-ray images of low quality as those from portable devices. To do so, we took advantage of a large dataset from magnetic resonance imaging of a similar pathology and performed two stages of transfer learning to obtain a robust methodology with a low number of images from portable X-ray devices. This way, our methodology obtained a satisfactory accuracy of $0.9761 \pm 0.0100$ for patients with COVID-19, $0.9801 \pm 0.0104$ for normal patients and $0.9769 \pm 0.0111$ for patients with pulmonary diseases with similar characteristics as COVID-19 (such as pneumonia) but not genuine COVID-19.
Automatic segmentation of the Foveal Avascular Zone in ophthalmological OCT-A images
Nov 26, 2018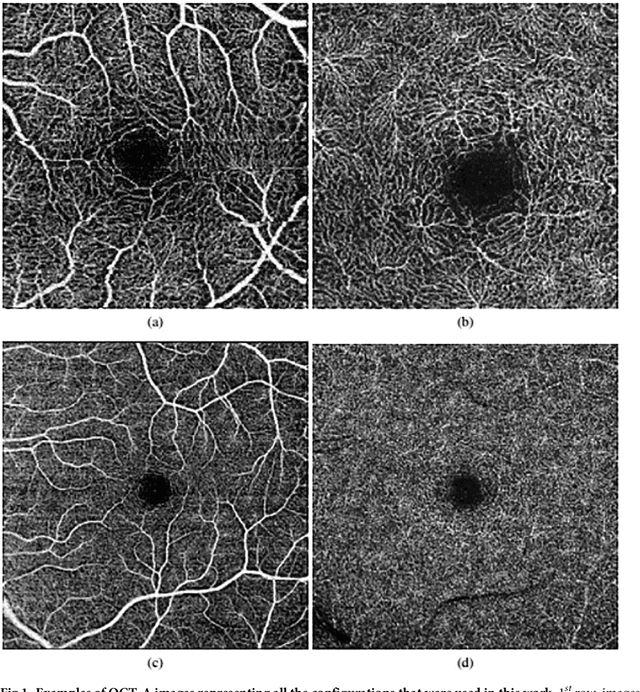



Angiography by Optical Coherence Tomography is a non-invasive retinal imaging modality of recent appearance that allows the visualization of the vascular structure at predefined depths based on the detection of the blood movement. OCT-A images constitute a suitable scenario to analyse the retinal vascular properties of regions of interest, measuring the characteristics of the foveal vascular and avascular zones. Extracted parameters of this region can be used as prognostic factors that determine if the patient suffers from certain pathologies, indicating the associated pathological degree. The manual extraction of these biomedical parameters is a long, tedious and subjective process, introducing a significant intra and inter-expert variability, which penalizes the utility of the measurements. In addition, the absence of tools that automatically facilitate these calculations encourages the creation of computer-aided diagnosis frameworks that ease the doctor's work, increasing their productivity and making viable the use of this type of vascular biomarkers. We propose a fully automatic system that identifies and precisely segments the region of the foveal avascular zone (FAZ) using a novel ophthalmological image modality as is OCT-A. The system combines different image processing techniques to firstly identify the region where the FAZ is contained and, secondly, proceed with the extraction of its precise contour. The system was validated using a representative set of 168 OCT-A images, providing accurate results with the best correlation with the manual measurements of two experts clinician of 0.93 as well as a Jaccard's index of 0.82 of the best experimental case. This tool provides an accurate FAZ measurement with the desired objectivity and reproducibility, being very useful for the analysis of relevant vascular diseases through the study of the retinal microcirculation.