 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Transfer Learning-based Approaches for Retinal Vascular Segmentation
Paper and Code
Dec 18, 2020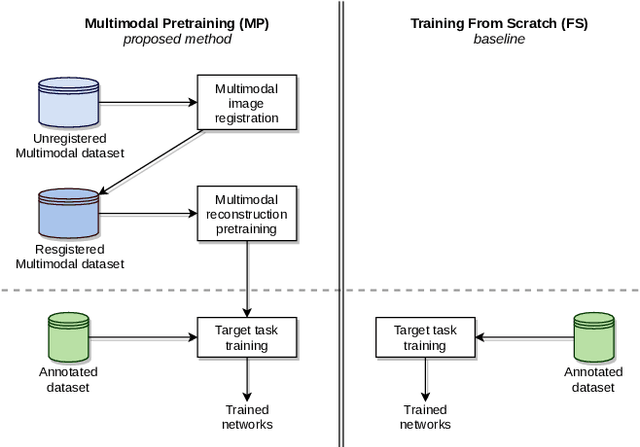
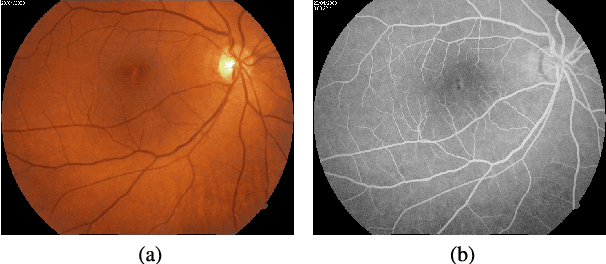
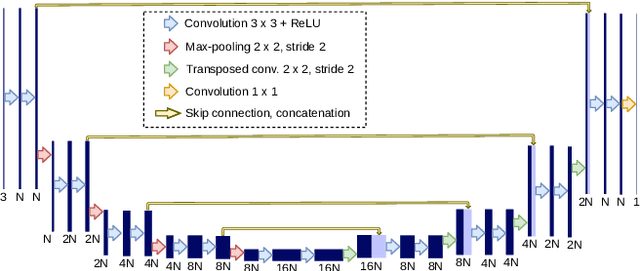
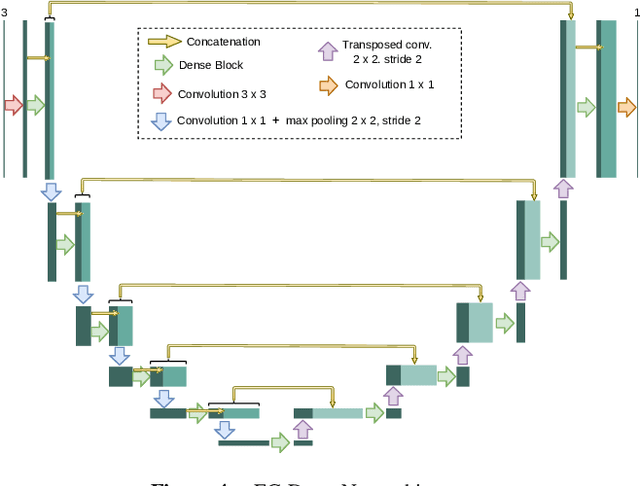
In ophthalmology, the study of the retinal microcirculation is a key issue in the analysis of many ocular and systemic diseases, like hypertension or diabetes. This motivates the research on improving the retinal vasculature segmentation. Nowadays, Fully Convolutional Neural Networks (FCNs) usually represent the most successful approach to image segmentation. However, the success of these models is conditioned by an adequate selection and adaptation of the architectures and techniques used, as well as the availability of a large amount of annotated data. These two issues become specially relevant when applying FCNs to medical image segmentation as, first, the existent models are usually adjusted from broad domain applications over photographic images, and second, the amount of annotated data is usually scarcer. In this work, we present multimodal transfer learning-based approaches for retinal vascular segmentation, performing a comparative study of recent FCN architectures. In particular, to overcome the annotated data scarcity, we propose the novel application of self-supervised network pretraining that takes advantage of existent unlabelled multimodal data. The results demonstrate that the self-supervised pretrained networks obtain significantly better vascular masks with less training in the target task, independently of the network architecture, and that some FCN architecture advances motivated for broad domain applications do not translate into significant improvements over the vasculature segmentation task.